







供稿 | eBay DSS Team
作者 | 肖春君
编辑 | 顾欣怡
本文12482字,预计阅读时间35分钟
更多干货请关注“eBay技术荟”公众号
序
eBay作为一家互联网电商,有海量的商品交易数据和丰富的数据分析及应用场景。其中,服务于商业智能 (BI) 的数据集,往往根据业务部门的需求及数据本身的特点,以结构、半结构化等形式存在于多个分离异构的数据平台。目前大数据领域已经涌现了众多优秀的大数据查询及计算引擎,针对不同的应用场景各有侧重。但为了向数据科学家、分析师,以及企业决策人员等终端用户提供数据探索和商业智能服务,各数据分析和应用平台往往需要同时对接多个异构的数据平台和查询引擎,构建7*24小时在线的即席查询和报表服务。这些面向用户的数据应用,比如交互式的数据查询及探索平台、商业智能 (BI) 产品,以及基于机器学习的分析预测平台等,对后端的数据平台的访问都有共同的需求和相似的特点。弥合数据平台和数据应用之间的断层,打通端到端(终端用户及应用到数据存储计算引擎)的数据访问、支持源到源(多种分离异构的数据平台)的数据流动、构建跨数据源、跨存储平台的统一的查询计算引擎,提供面向应用的、统一、强大、高效、稳定的快速数据访问服务,是eBay数仓部门 Data Service & Solution (DSS) 需要提供给eBay数据用户的基础能力。本文以eBay增强商业智能平台Nous, 以及业务指标异常检测平台(MMD, Moving Metrics Detection)等多个数据产品所使用的快速数据访问服务DataExpress为例, 介绍Actor Model及其在企业级数据服务中的应用。PART 01
背景介绍
Nous是eBay内部增强智能分析平台,通过结合元数据管理 (metadata) 及知识图谱 (knowledge graph) 等技术,支持用户自定义业务指标(metric)和分析维度(dimension),并提供基于自然语言处理和属性图的搜索入口,让用户可以轻松整合定制业务报表、进行交互式数据洞察分析。MMD是一个基于机器学习模型的时间序列异常指标检测系统。
Nous和MMD共享同一套元数据管理、知识图谱等基础组件,都通过DataExpress服务统一访问后端多种数据存储和查询引擎,包括Kylin, SparkSQL, MySQL, ElasticSearch, MongoDB等,查询类型以时间序列聚合查询为主。不同之处在于,Nous主要是交互式即席查询,查询并发量较低、对响应速度要求较高;而MMD以批量点查为主(即批量地对特定的指标、维度进行时间序列的聚合查询),因而数据查询并发量相对较高,而对响应延时并不像Nous那么苛刻。作为数据查询的通路,很自然地,在DataExpress的最初版本中(1.0版本,下文简称DE1.0)我们以查询(query)为核心实体,采用了生产者、消费者的数据模型,以及无状态(stateless)的多节点、多流水线并行执行的系统架构,如下图所示。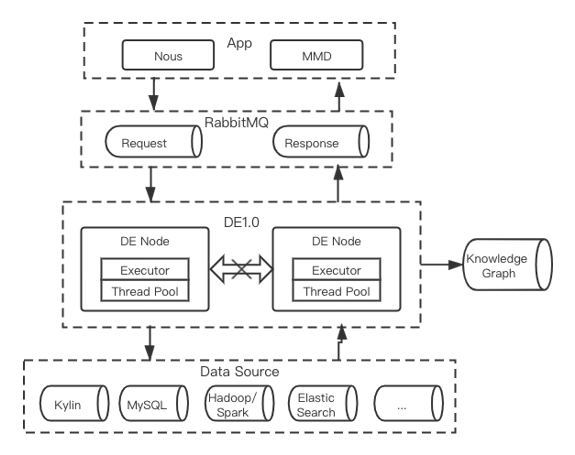
图1(点击可查看大图)
DataExpress1.0节点抓取消息队列中的查询请求,结合Knowledge Graph (KG) 中存储的元数据,包括数据源(data source)、指标(metric)、维度(dimension)及其关系(relationship)等,解析查询请求、选择最优查询路径、规划查询计划、执行物理查询、返回结果。该架构模型简单、稳定、高效,但同时也严重制约了DataExpress的能力。例如,1)缺少全局的资源管理及调度能力
像DataExpress这种集群服务,很自然地存在全局的资源管理、任务调度、数据共享的需求,但DataExpress1.0这种无状态的“伪”分布式系统,刻意回避了这方面的需求及挑战;而通过简单地增加外部服务来协调资源分配、共享集群状态,不但难以满足业务需求,反而不必要地增加系统开发和运维的复杂度、降低系统的稳定性和运行效率,得不偿失。2)限制了查询优化能力
为了提高查询速度,同时降低后端数据平台的访问压力,我们期望针对数据查询的模式及数据平台的特性,采用多种优化手段,例如基于平台和表(table)的实时性能统计的最优查询路径的选择;为每个表创建独立的查询缓存及更新淘汰策略、并保证用户视角的数据的一致性及时效性;为某些访问较慢的表自动创建“半聚合”加速缓存表等等。但多种优化手段都依赖于全局范围的状态收集、任务管理、数据复用,在DE1.0目前的架构下都难以较好地实现。3)限制跨平台联合查询(DAG)
跨平台联合查询,例如把ElasticSearch中的数据集与Spark平台中的表进行“JOIN”操作,以至更复杂的跨多数据源、多平台类型的探索性联合查询,相应的查询规划(query plan)中的步骤跨越多个平台,涉及多个基础及派生表(base/derived table),执行多种类型的算子和操作,理论上可以形成一个复杂的Directed Acyclic Graph (DAG)。如何以正确、高效、可扩展、可容错的方式执行这种复杂DAG,对DE1.0提出了巨大的挑战。4)限制跨平台数据流动
例如为了更好地服务于数据查询应用,可以定义轻量(lightweight)的ETL任务流,以构建起跨数据源和数据平台的数据流动及数据加速等,目前DE1.0的架构都难以支持。PART 02
解决方案:Actor Model
类比Hadoop以Map-Reduce为建模核心、到Spark以Dataset (RDD) 为建模核心的转变,我们也在思考,以查询(query)作为DataExpress的核心实体,是否是最优的设计方案?
对Data Service & Solution (DSS) 部门及DataExpress系统来说,我们最核心的资产和工作对象是海量的数据,具体而言就是成千上万的“表”(包括半结构化的数据集),查询不过是对这些“表”的具体应用之一。很自然地,我们考虑以“表”为DataExpress的建模核心,并采用了Actor Model的编程模型,把每个“表”抽象为一个actor,在Akka Actor Toolkit的基础上,开发了DataExpress2.0(下文简称DE2.0)。2.1
Actor Model
Actor模型是一种并发编程模型 [1]。在这种编程模型下,业务对象被抽象为一个个actor。每个actor有自己的状态(state)、行为(behavior)及消息信箱(mailbox)。Actor之间仅通过发送消息(message)进行交互(如下图所示,图片来自Flink社区 [2]),并通过响应消息来改变内部状态,执行任务,对外提供服务。Actor也可以创建子actor(child actor),从而形成一个树状结构;而actor之间的消息则形成一个网状结构。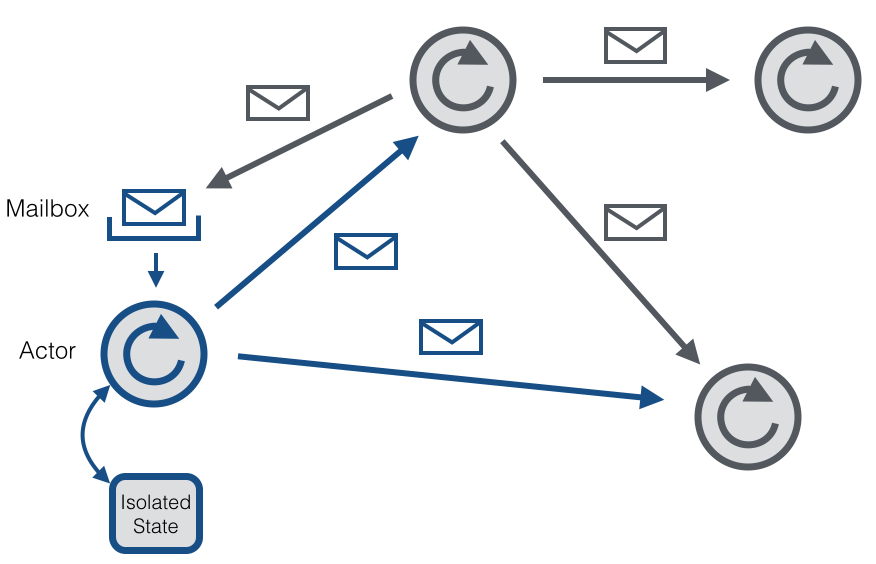
图2(点击可查看大图)
Actor的mailbox可近似认为是一个带某种优先级的FIFO队列(故下文以“消息队列”指代),actor按照某种优先级逐个顺序消费(dequeue)其消息队列中的消息(如下图3所示,图片来自Akka Actor官方文档 [3]),多个actor对各自消息队列的处理可以并发执行。不同于常见的面向过程(Procedure Oriented)和面向对象(Object Oriented)编程模型中的函数调用(function call),以及互斥锁等并发同步机制,由于actor之间并不共享内部状态,而仅通过响应消息来改变内部私有状态,且每个actor对消息的消费(dequeue)是单线程同步的,因此在actor的编程模型下,用户完全不用(显式)加锁,仅通过Fire-and-Forget的非阻塞的异步消息通讯机制,即可安全实现异步并发。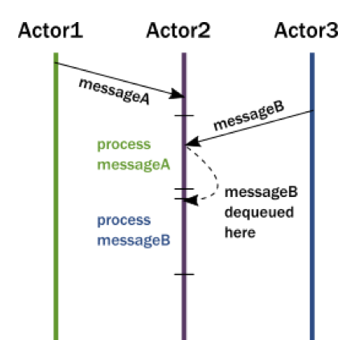
图3(点击可查看大图)
需要强调的是,尽管actor对消息队列的消费以及自身状态的更新是单线程同步的,但由于每个actor可以任意创建子actor或者任务线程(如Scala中的Future)去继续其对消息事件的处理,并在处理结束后通过对父actor发送异步消息来汇总处理结果、更新内部状态,因而actor模型可以充分利用计算资源,快速开发高性能、高并发的分布式应用。2.2
Table as an Actor
在eBay增强商业智能平台Nous中,我们把所有结构、半结构化的数据集(dataset)统称为广义上的“表”(table)。在DataExpress2.0中,“表”可以根据血缘(lineage)关系分为两类:1)用户在统一的元数据管理系统中注册的原始物理表(base table);2)通过对一张或者多张物理表(或派生表)进行某种转换操作(如用户自定义的join/union/project等操作,即custom query)创建出来的派生表(derived table)。派生表可以是概念上虚拟存在的,也可以物化(materialize)为物理表(由于物化的派生表通常用于数据访问加速,类比Kylin中cube的概念,Nous内部也常称之为加速cube)。不论是原始表还是派生表,都有一个全局唯一的table ID.在DataExpress2.0的设计中,我们以table为建模的核心,为每个table创建一个table actor,可以近似认为为每个table在进程内存中创建一个代理(proxy,如下图所示)。所有对该table的访问,都由该table在整个DataExpress2.0集群中唯一的table actor负责处理。我们通过把全局唯一的table ID绑定到table actor,就可以利用Akka Actor Toolkit提供的组件,以位置透明(location transparent)的方式向该table actor发送消息,而无需关心该table actor是否存在、以及具体存在于哪个物理节点。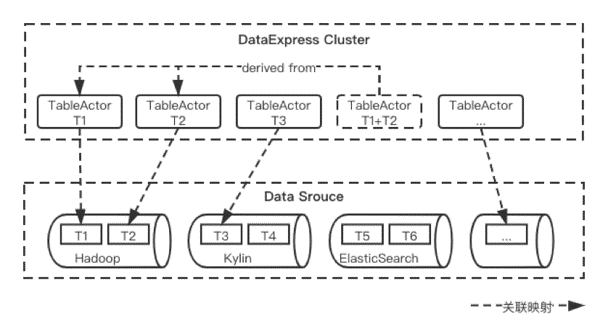
图4(点击可查看大图)
这种“唯一代理”的建模方式,为我们追踪数据血缘、“表”粒度监控访问状态、优化查询性能、构建复杂功能,提供了极大的潜力。我们将在下文中结合Akka Actor Toolkit的功能特性,予以说明。PART 03
Akka Actor Toolkit 简介
Akka is a toolkit for building highly concurrent, distributed, and resilient message-driven applications for Java and Scala. - from Akka official website Akka是一套为JVM开发的Actor模型的开源的库及运行时环境,主要用于开发高并发、高性能、可容错、弹性可扩展的分布式系统。Akka的核心是其Actor模型。需要强调的是,Akka是一套工具集、运行时库(runtime & library),并不像Spring一样是一个框架(framework),因而Akka赋予用户更加充分的架构设计(architecture)的自由,同时也对用户的架构设计能力提出更多挑战。注:Akka Actor基于同一套Actor核心库,提供了多套成熟的API:从语言的角度看,有Scala和Java API,从类型安全的角度看,有Classic Actor和Typed Actor,其中Typed Actor主要针对Classic Actor的缺陷、强化了类型安全。本文对Akka的概念和功能的介绍对所有API都适用,但概念阐述及代码举例时默认以Classic Actor及Scala API为主[4]。
3.1
Akka Actor
Akka Actor遵从了Actor模型的基本特征,有以下特点:- Actor Lifecycle
- Actor Tree and Supervision Hierarchy
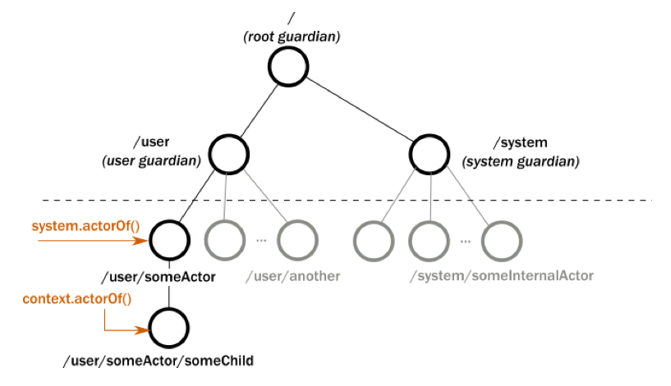
图5(点击可查看大图)
Parent actor负责监控管理child actor, 并可自定义监控策略(supervision strategy),在child actor正常或异常退出的时候,选择适当的应对机制(Resume/Restart/Stop/Escalate等)。当然,即使不同actor tree下的child actor,也可以互相通信、订阅actor退出事件(watch for actor termination)等。这种层级监控机制,使得整个actor系统可以更全面、更方便地捕获并处理异常事件,从而促进整个系统的高容错性。- Actor Reference
- Message Sending
1)Tell: Fire-And-Forget
这是推荐的方式,异步发送消息,消息发送后即转而进行其他处理,不阻塞等待消息回复。2)Ask: Send-And-Receive-Future
同样是异步发送消息,但这种方式会返回一个Scala Future对象,可用于接收消息回复。 此外,消息也可以被转发(forward),如下图所示。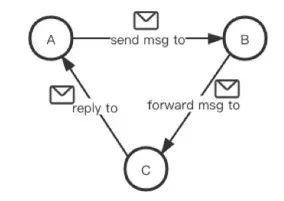
图6(点击可查看大图)
- At-Most-Once Message Delivery
3.2
Akka Actor Toolkit
Akka Actor Toolkit为我们开发高性能分布式应用提供了丰富易用、成熟可靠的组件和工具,并辅以完善的文档和详实的示例 [7]。DataExpress2.0中使用了其中大量的组件(如图7所示),本文仅介绍构建DataExpress2.0分布式服务所依赖的几个关键组件。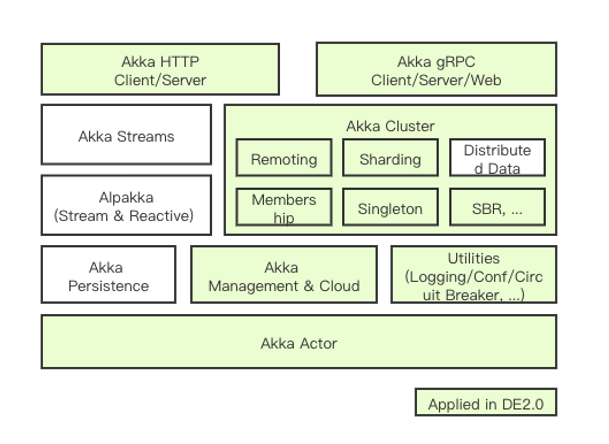
图7(点击可查看大图)
- Akka Cluster
- Akka Cluster Sharding
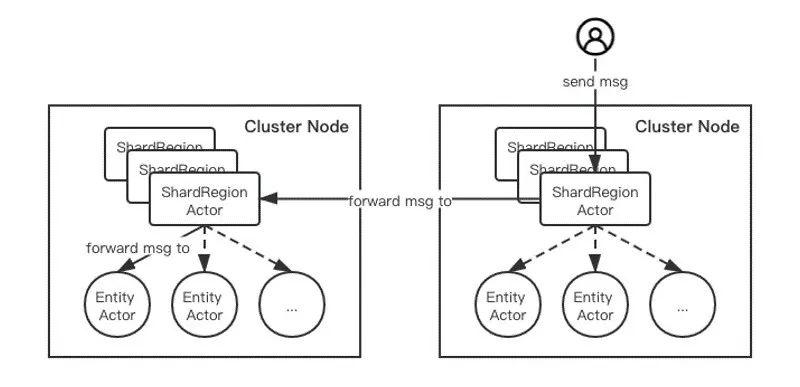
图8(点击可查看大图)
用户甚至不需要关心该entity actor是否已经在进程中物理存在;当用户第一次通过该实体的actor id向该entity actor发送消息时,Akka Cluster Sharding会自动为该实体实例化entity actor,即我们前面提及的惰性创建(lazy creation)。而当该entity actor长久没有收到消息时,很自然地,用户期望能够销毁该entity actor,释放系统资源;但同时,也需要能应对这样的极端情况(corner case), 即在actor销毁的过程中再次收到消息。为了避免此时丢失消息,Akka Cluster Sharding也提供了idle actor优雅退出方案,即Passivation [9]:entity actor在销毁退出的过程中新收到的消息,会被其parent actor,即图8中的ShardRegion actor缓存起来,并在该entity actor销毁完成后,重新为其创建一个新的全局唯一的entity actor(new incarnation),然后将缓存的消息转发给该entity actor,从而尽量避免消息丢失。- Akka Cluster Singleton
- Split Brain Resolver
PART 04
Akka Actor
在 DataExpress2.0 中的应用
DataExpress2.0 (DE2.0) 构建在Akka Actor模型的基础上,并使用了Akka Actor Toolkit中的多个组件,包括Akka Cluster Sharding, Cluster Singleton及其他辅助设施,模块架构如下图所示。
Akka Cluster的上述多种功能,都依赖于集群成员状态(membership)的全局一致性,以保证Leader节点的唯一性。Akka Cluster提供了异常节点检测机制,但无法区分节点宕机(machine crash)和网络分裂(network partition),因此Akka Cluster用户在处理容错(failover)时,必须要考虑脑裂问题(Split Brain) [10]。实际上,对脑裂问题并没有一个万能的银弹方案(silver bullet),常用的几个选择包括Static Quorum, Keep Majoriy, Keep Oldest, Down All等,用户需要根据自己的应用场景取舍选择。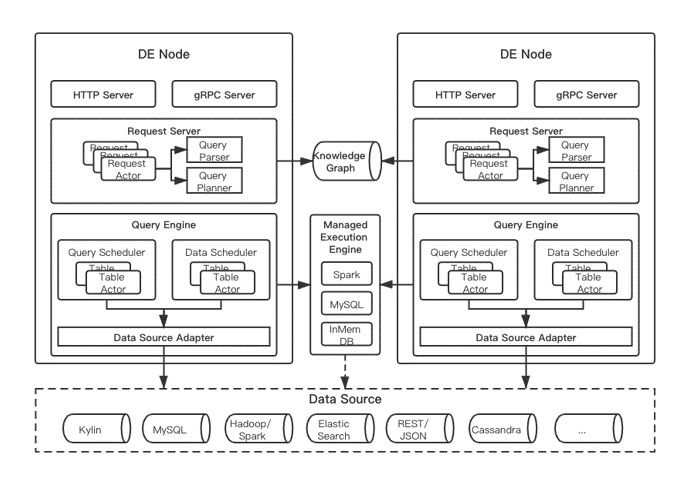
图9(点击可查看大图)
4.1
Akka Actor的应用
在actor模型方面,我们为整个系统抽象出了多种actor,重点是Request Actor和Table Actor。把每个查询请求(query request)抽象为一个Request Actor。该Request Actor有独立的生命周期,可以跨越任意多个请求-响应周期,因而可完成复杂的处理逻辑及会话。比如在DE2.0中,Request Actor支持轮询及异步回调,请求排队、合并、挂起及恢复等,根据请求参数灵活定制超时时间等。此外,如前所述,DE2.0的核心设计是为table抽象出Table Actor:对整个业务领域的每个table,整个集群中存在唯一一个Table Actor用于代理所有对该table的操作(proxy)。其他一些辅助及管理类的对象, 包括Connection Manager, Lock Manager, Task Scheduler, Table Replicator等等,也都通过Akka actor来实现,并充分利用了Akka actor模型带来的便利。4.2
Akka Cluster Sharding
在我们的元数据管理系统中,每个table都有一个全局唯一的id,我们把该table id用作Table Actor的id。我们也为每个用户请求(request)创建一个全局唯一的request id,同样用作Request Actor的id。每个Request/Table Actor都有一个全局唯一的id,便可以通过Akka Cluster Sharding机制对actor进行分区分布,并以位置无关的方式从任意一个集群节点出发,访问到全局唯一的目标Request/Table Actor。当前DE2.0集群中每个节点都包括Request Server及Query Engine两层,部署于同一个Akka JVM节点(后期可能会分拆)。我们在这两层分别为Request Actor及Table Actor创建了单独的Sharding Cluster实现解耦。通过request id及table id,我们可以在任意节点上接收请求(包括用户查询请求和table actor请求),并路由到唯一的目标集群节点上的目标Request/Table Actor进行处理。如前所述,Akka Cluster Sharding也为我们提供了actor惰性创建(lazy creation)及优雅退出(passivation)的方案,从而可以高效利率系统资源。4.3
Akka Cluster Singleton
DataExpress2.0使用Akka Cluster Singleton,用actor模型实现了集群唯一的任务调度器、分布式锁、全局限流器等。其中,对于分布式锁和限流器的某些需求,比如请求排队、超时自动解锁、资源召回(recall)、资源剥夺(revoke)等,通过actor模型自带的消息队列都可以很方便地实现。为了避免单点性能瓶颈,DataExpress2.0只用Cluster Singleton实现元数据管理、系统运行监控类任务,并通过多种方式避免单点性能及单点故障对整个集群性能(performance)和可用性(availability)造成的影响,包括简化singleton actor主消息处理逻辑(复杂处理逻辑代理给child actor及Scala Future线程),用户端建立带超时的缓存以减少调用频率,并通过异步消息及时发布缓存更新等。PART 05
使用Akka Actor的优势
从系统架构上看,使用Akka Actor Toolkit打造的Peer-to-Peer架构的DataExpress服务比较适合我们的应用场景。
整个业务上table的数量在数千到上万之间,经常访问的活跃的表(active table)只占其中较小的比例,仅为每个活跃的表创建唯一一个Table Actor,统一处理所有对该表的请求,并且actor本身也是个轻量级、资源效率较高的实体,从而决定了整个DataExpress2.0集群只需要数个或十数个节点即可满足业务需求。这种Peer-to-Peer的架构通过简单的横向扩缩容(scale out)可以很方便地适应业务的增长,同时高效利用资源。Akka Cluster和Akka Singleton在这种规模较小的集群下可以发挥出较好的性能和稳定性。Actor模型所推崇的“Let it crash”哲学,也使得DataExpress系统可以做到较好的弹性及容错性:面对各种异常事件都能自愈(self-heal)并保持响应(responsive)。 从开发实现来看,由于每个actor都有自己的状态(state)、状态机(behavior)、消息队列(mailbox)、计时调度器(timer & scheduler)等,所以我们可以像开发一个单进程、单线程程序一样围绕每个actor进行线性编程,从而降低并发系统的开发难度;同时,如果业务需求导致单个actor的状态机变得太过复杂,又可以通过创建子actor的方式分解逻辑、降低复杂度。此外,Akka Actor Toolkit提供了大量成熟可靠、接口一致的组件,使得我们在面对新的挑战时都有快速的解决方案。 从系统性能上看,Akka Actor的目标之一是支持高性能、高并发的应用。DataExpress2.0的Table Actor通过创建child actor以及使用Scala Future创建多个任务处理线程的方式,可以极为便捷地实现非阻塞的异步高并发,最大限度挖掘单机计算能力;这也促进了集群规模的缩减,进一步提升了整个系统的稳定性。 从技术赋能上看,通过Akka Cluster Sharding,我们为每个request及table创建了全局唯一的actor作为代理,并以位置无关的方式对其访问。这种位置透明及唯一性给我们带来了极大的便利和能力:任一DataExpress2.0节点都可以作为用户请求的接入节点,并自动把请求路由到目标Request Actor。由于对任一table的请求都由各自Table Actor处理,在此前提上,我们可以在每个Table Actor内对收到的查询进行合并优化,对状态进行统计监控,在多个平台间对数据进行调度复制,对查询结果进行缓存重用等等,无所不能。以查询缓存为例。为了提高查询速度,降低后端数据平台的访问压力,在DataExpress1.0的版本中曾经把近期历史查询缓存在外部Redis集群中。虽然有一定作用,但也遇到了时效性、一致性、外部依赖等问题,通过actor模式都可以较好地解决:- 时效性:每个Table Actor有实时的访问统计及查询性能数据,以及各actor独立的定时器及调度器,因而可以很便捷地定制自己的缓存淘汰及刷新策略,在数据时效性和查询速度之间达到较好的平衡。
- 一致性:简单的缓存方案有可能导致用户视角的数据不一致的问题。比如这么一种场景:用户A对某表进行一次查询query-1, 没有命中cache,因而从数据源查询;随后用户A对该表进行了另外一个查询query-2,命中了某cache;但因缓存的时效性问题,该cache数据有可能跟query-1的查询结果并不一致,给用户造成困惑。如果每个Table Actor对各自的table层级的缓存及查询统一管理,使用简单的策略,即可避免这种不一致性的情况。
- 外部依赖:Table Actor本身是实际访问时按需惰性创建,并支持静默无访问时优雅退出(Passivation[9]),且DataExpress这种聚合查询为主的场景下,查询结果数据量并不大,因此完全可以把缓存构建在DataExpress2.0内部活跃的Table Actor上,而不再使用外部存储,从而减少了对外部服务的依赖性、高效利用内存资源。
- Cross-Platform Query DAG
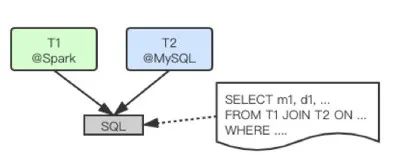
图10(点击可查看大图)
DataExpress2.0通过Query Parser、Query Planner将其转换为如下的执行步骤:1)把MySQL表的(小)数据子集复制到Spark平台;2)与Spark平台上的(大)表执行JOIN操作(eBay数据仓库已经迁移到Hadoop/Spark平台,因而Spark表不需要复制)。如下图所示,实际执行中会为最终JOIN的结果在DataExpress2.0中创建一个虚拟的派生表(virtual derived table,即下图中的表T3)及其Table Actor,并为其派生出一个全局唯一的table id。Query Planner把该查询DAG转换为表依赖树(table dependency tree, derived from what table with what operation),即该表的血缘(Lineage),包括该表所直接依赖的父表、以及生成该表的操作(通常是SQL语句)。查询引擎(Query Engine)把该table dependency tree通过table id及Akka Cluster Sharding机制发送给根节点派生表的Table Actor (即下图中的表T3),派生表的Table Actor会解析依赖关系(resolve dependency tree),包括向父Table Actor(即下图中的表T2)发送数据调度请求,将示例中MySQL表(T2)筛选后(SQL2)的数据子集复制到Spark平台,并为其创建复制表(即图11中的表T2’),用于最终在Spark平台上执行联合查询。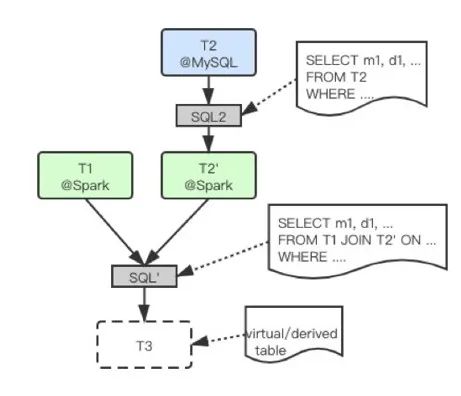
图11(点击可查看大图)
由于需要调度的异构数据集往往是维度表或者(半)聚合表, 且原联合查询语句(SQL)经过Query Planner优化后,会拆分为多条SQL, 并执行谓词下推(predicate pushdown)等优化,实际上DataExpress2.0需要复制的数据集是在原(小)表上执行一条SQL语句之后的结果,因而该数据集规模通常并不大,可以快速调度到ebay内部为OLAP优化的目标Spark平台上去。此外,通过全局唯一的Table Actor代理每个table的访问操作,每个Table Actor实际上会感知、记录、缓存、重用、甚至自动刷新各自table在各个平台上的副本(replica),因而通过重用已有副本的方式,可以大大加速平台间的数据调度。实际上,考虑到用户经常会对多表的联合查询结果做进一步的钻取分析,有些情况下我们会对原查询语句的查询条件做一些放松调整(如扩大日期范围或增加常用维度),并将查询结果(如下图中的派生表T3)固化为某个中间平台上的物理表(如MySQL),加速后续查询;同时支持用户自定义调度刷新策略,周期性地刷新该表。实际上相当于用户快捷地自定义了一个新的cube(类比Kylin中的cube概念)。该加速表的Table Actor会根据调度策略,自动执行数据刷新操作。整个DAG查询执行及优化的诸多细节中,我们都可以发现Table Actor带来的优势。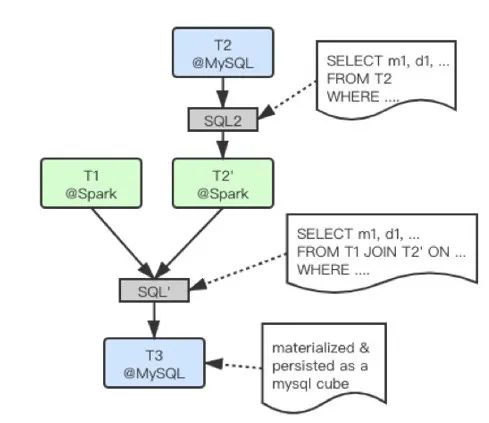
图12(点击可查看大图)
下图展示了一个更为复杂的跨平台DAG查询。为了验证DataExpress2.0的完整的DAG的处理能力而刻意编写的一个低效的查询,同时为了增加复杂度,刻意把某些派生表指派到了特定平台,如T12指派到了MySQL平台,实际中的查询经过Query Planner规划后可以大幅优化,并不会出现下图中低效的场景。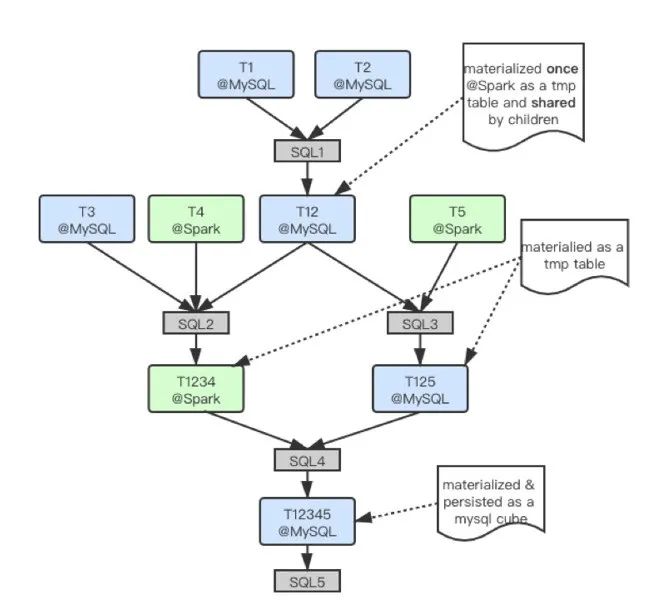
图13(点击可查看大图)
该查询方案主要是增加了多个子查询的共同依赖(如图中的表T12被T1234及T125共同依赖),以及一条子查询中支持多表多平台(如图中的表T1234及其3个不同平台的父表)。通过使用全局唯一的Table Actor的方案,多表共同依赖的父表(T12)仅需一次查询创建(通过图中SQL1操作),子表共享唯一的查询结果;而DAG中可以并行执行的查询(如图中SQL2及SQL3)则会被QueryEngine很自然地并行调度;从而达到整个DAG的执行效率的最优。跨平台DAG查询性能取决于其中执行最慢的操作节点,影响因素包括原表查询、数据复制、执行平台、查询频率、缓存策略等,不好一概而论。在我们实际测试场景中发现,通过异步消息、函数回调等机制串联起来的DAG调度效率极高,DAG本身调度耗时可以忽略不计。此外,上述方案也有很多优化空间,如中间查询引擎的选择等,篇幅所限,不再赘述。PART 06
使用Akka Actor的经验和建议
在我们使用Akka Actor的过程中,面对过诸多新概念、新模式、新选择,也踩过大大小小的一些“坑”,此处摘取几点经验总结,仅供参考。
6.1
Classic Actor vs. Typed Actor
Classic Actor和Typed Actor是基于同一套Actor核心的两套API,两者都已经发布许久。在Akka 2.5.x及其之前的版本中,Akka默认主推Classic Actor;从Akka 2.6.0开始Akka主推Typed Actor。但Akka官方对两者都继续完全支持,且可以共同使用。因为DataExpress2.0项目启动时 Akka 2.6.0 [12]刚发布不久,出于多种考虑因素,我们继续采用了Classic Actor。笔者在使用Classic Actor中感受到的一个主要问题,就是类型安全(type-safty)。比如,Classic Actor的消息处理函数类型定义为: 即可以接收任意类型的消息(Any);具体函数体实现一般通过Scala case class类型匹配(pattern matching)转换到具体的消息类型上。这为用户在各种类型的actor间收发消息带来了极大的便利,但灵活性是把双刃剑。有了这种自由,用户很容易滥发消息,就像在电路板中到处“飞线”一样,各actor通过各种消息编织在一起,形成消息网,导致消息的来源和目的地都不再清晰、且难以调试及维护。更糟糕的是,由于类型向上转换(具体消息类型up-casting到Any),编译器也无法通过编译期检查帮我们捕捉潜在错误,只能由用户自己去调试;JVM语言类型系统的优势不能完全发挥。Typed Actor最大的改变就是显现强化了Actor可以处理的消息类型,从而可以充分发挥类型系统及编译器的优势。但实际使用起来如何,笔者并无深刻的体会。此外,Typed Actor本身也有两种风格的使用方式:Functional vs. Object-Oriented Style
[13]。函数式风格虽然看起来很优雅,但针对大多数程序员的思维习惯、以及要解决的实际问题是否编程友好,需要大家自己去实践中体会。
即可以接收任意类型的消息(Any);具体函数体实现一般通过Scala case class类型匹配(pattern matching)转换到具体的消息类型上。这为用户在各种类型的actor间收发消息带来了极大的便利,但灵活性是把双刃剑。有了这种自由,用户很容易滥发消息,就像在电路板中到处“飞线”一样,各actor通过各种消息编织在一起,形成消息网,导致消息的来源和目的地都不再清晰、且难以调试及维护。更糟糕的是,由于类型向上转换(具体消息类型up-casting到Any),编译器也无法通过编译期检查帮我们捕捉潜在错误,只能由用户自己去调试;JVM语言类型系统的优势不能完全发挥。Typed Actor最大的改变就是显现强化了Actor可以处理的消息类型,从而可以充分发挥类型系统及编译器的优势。但实际使用起来如何,笔者并无深刻的体会。此外,Typed Actor本身也有两种风格的使用方式:Functional vs. Object-Oriented Style
[13]。函数式风格虽然看起来很优雅,但针对大多数程序员的思维习惯、以及要解决的实际问题是否编程友好,需要大家自己去实践中体会。
6.2
语言的选择:Scala vs. Java
Akka Actor基于JVM,支持Scala及Java两种编程语言。Actor之间的交互依赖于消息发送,而不是函数调用;面向对象语言中的关键特性多态(polymorphism)往往基于函数调用,在actor的消息的世界里发挥不出太多作用。而函数式编程所推崇的immutability,特别是Scala中的case class, pattern matching, partial function等非常适合用来处理消息。此外,前面已经多次提及,actor的消息处理线程主要用于处理消息队列、更新自身状态、派送消息和子任务,不适合进行一些计算密集或者IO密集型的任务;因此需要把此类任务委派给child actor去处理,但更快捷的方式是使用Scala的Future,简单几行代码,即可把繁重的任务丢到一个单独的线程及线程池中去处理,避免阻塞主actor对消息的响应;同时Scala Future的回调接口又可以跟actor的异步消息机制完美结合。Akka Actor的优势之一是弹性可容错,而Scala支持的函数式编程范式,把单入口、单出口的函数以streaming的方式串接起来,对异常的捕捉处理非常友好全面,更强化了系统的正确性和容错性。总之,不论是从开发效率,还是运行效率来看,Scala无疑都跟Actor模式结合得更好。因此,如果使用Akka Actor,笔者强烈推荐使用Scala编程语言。实际上,Scala和Akka Actor背后的商业公司已合并为一家 [14],即 lightbend.com, 可见两者的契合度。从另一个角度看,如果选择Scala都能成为障碍,为什么还要使用Akka Actor这种小众的编程模型呢?6.3
严格限定Akka Cluster的边界
由于Akka Cluster支持以位置无关的方式跨越节点发送消息,很容易诱导一些用户把Akka Actor用作分布式RPC通信的基础组件,包括Spark也曾经把Akka Actor用于实现其RPC通信;但由于Akka Actor消息的版本间的二进制兼容性差、不可靠的消息传递、消息包大小限制、序列化性能,以及组件依赖等多种因素,Akka Actor并不适合作为通用RCP通信组件来使用 [15]。此外,即便真正适合使用Akka Actor模型的场景,用户可能也会为了各Akka Cluster间交互方便而直接使用Actor消息进行RPC通信,无意中模糊了各Akka Cluster的范围和边界,从而生硬地拼凑出一个巨大的分布式“怪物”(distributed monolith)。而且考虑到Akka Actor消息在各版本间不保证二进制兼容,通过Akka Actor消息在多个服务间进行通信,会导致服务间强耦合,也不符合微服务的模式(anti-pattern)。对于种种弊端,Akka官方及社区都有一些讨论,因此用户需要谨慎限定Akka Cluster的边界 [16]。6.4
重视脑裂问题(Split Brain)
DataExpress2.0构建在Akka Cluster的基础上,包括Akka Cluster Sharding及Cluster Singleton组件,所有这些都依赖于cluster membership的全局一致性。考虑到我们的集群都部署于同一个数据中心,且集群规模不大,脑裂问题出现的概率似乎微乎其微。但实际使用中发现,如果数据吞吐量较大,特别是多个跨平台的数据调度任务不加限制地并发执行,且在开启了Akka Cluster Auto-Downing选项 [17]的情况下,由于网络拥塞,很容易导致gossip协议通信失败,从而出现集群脑裂。由于DataExpress2.0主要是用于数据读取(以及少量可重入的数据调度任务),因而脑裂问题更多的是影响系统执行效率,而不会导致数据损坏及系统紊乱。但作为一个高可靠、高可用的服务,DataExpress2.0非常重视脑裂问题,并通过采用社区方案快速解决。用户在使用Akka Cluster的时候也应该重视该问题,必要时甚至可以考虑放弃Akka Cluster Sharding功能而采用自研方案。6.5
代码开发中的“小坑”
不论是Akka Actor,还是Scala语言,这些模型或语言不但小众,且都有很多的“语法糖”,使用起来“真香”,但如果没有比较严格的代码规范,很容易写出在新手看来“天书”一样的代码。此外,Scala并不是纯函数式编程语言(支持var变量),叠加Scala的隐式参数(implicit)和Akka的“语法糖”,很容易出现莫名其妙的程序错误,在复杂的动态消息网络下进行调试并不容易,比如一个常用的Akka消息转发的“语法糖”: 如果仔细看forward函数的定义:
如果仔细看forward函数的定义:
 这其中包含了类型丢失(up-casting to Any),隐式参数(implicit context)以及变量引用(context.sender()),稍有不慎,就掉进坑里。但是,一旦趟过重重荆棘,真正掌握了Akka Actor使用的“秘诀”,就能发挥其巨大的威力和强大的生产力。
这其中包含了类型丢失(up-casting to Any),隐式参数(implicit context)以及变量引用(context.sender()),稍有不慎,就掉进坑里。但是,一旦趟过重重荆棘,真正掌握了Akka Actor使用的“秘诀”,就能发挥其巨大的威力和强大的生产力。
PART 07
写在最后
笔者并不是Akka Actor模型的鼓吹者,甚至不是很建议大家在生产环境中使用。
笔者个人非常享受Akka + Scala的架构设计和代码开发的过程,但考虑到国内技术生态的现状,无论是Scala还是Akka Actor,相对其他语言和框架来说都比较小众,人才市场上能够熟练掌握两者的人较少,一家成熟的公司采用任何技术栈都必须要考虑团队协作及软件系统长期的开发维护。此外,并不是所有的场景都适用Actor模型。Akka Actor非常强大,但使用门槛也较高,除非是非常适合Actor模型的场景,否则单纯为了追求技术极致、盲目跟风,会给项目引入较大的风险。笔者很认同论坛上某位同学的观点 [18]:绝大部分场景下你都不需要Actor模型,但是需要这个组合的场景,又会无比契合、绝顶强大。所以,当你厌倦了啰嗦的语言和死板的框架,当你看了本文的建议、对Actor模型蠢蠢欲动的时候,笔者真诚地建议你思考再三,努力说服自己:你的应用场景下是否真的需要Actor模型?是否有其他更简单成熟的选择?如果你始终无法说服自己放弃这个想法,那就勇敢地尝试吧!希望本文能在你实践Akka Actor的道路上提供一些参考,少走一些弯路,感谢阅读! 参考文献- Actor model, https://en.wikipedia.org/wiki/Actor_model
- Flink Internals: Akka and Actors, https://cwiki.apache.org/confluence/display/FLINK/Akka+and+Actors
- How the Actor Model Meets the Needs of Modern, Distributed Systems, https://doc.akka.io/docs/akka/current/typed/guide/actors-intro.html
- Classic Actors, https://doc.akka.io/docs/akka/current/actors.html
- Actor Architecture, https://doc.akka.io/docs/akka/2.5.31/guide/tutorial_1.html
- Interaction Patterns, https://doc.akka.io/docs/akka/current/typed/interaction-patterns.html
- Overview of Akka libraries and modules, https://doc.akka.io/docs/akka/current/typed/guide/modules.html
- Classic Cluster Sharding, https://doc.akka.io/docs/akka/current/cluster-sharding.html
- Passivation, https://doc.akka.io/docs/akka/current/typed/cluster-sharding.html#passivation
- Akka Split Brain Resolver, https://doc.akka.io/docs/akka-enhancements/current/split-brain-resolver.html
- Akka Cluster Custom Downing, https://github.com/sisioh/akka-cluster-custom-downing
- Akka 2.6.0 Released, https://akka.io/blog/news/2019/11/06/akka-2.6.0-released
- Typed Actor Style Guide, https://doc.akka.io/docs/akka/current/typed/style-guide.html
- Lightbend, https://en.wikipedia.org/wiki/Lightbend
- Spark project removed the use of Akka, https://issues.apache.org/jira/browse/SPARK-5293
- Choosing Akka Cluster, https://doc.akka.io/docs/akka/current/typed/choosing-cluster.html#microservices
- Akka Cluster Auto-Downing Removed, https://doc.akka.io/docs/akka/current/project/migration-guide-2.5.x-2.6.x.html#auto-downing-removed
- 为什么Akka(Actor模型)在中国不温不火?https://www.zhihu.com/question/279512440
您可能还感兴趣:
平台迁移那些事 | eBay百亿级流量迁移策略
eBay云计算“网”事|网络重传篇
分享 | eBay TESS,我心中的那朵“云”
前沿 | BERT在eBay推荐系统中的实践
eBay云计算“网”事|网络丢包篇
eBay云计算“网”事 | 网络超时篇
数据之道 | 属性图在增强分析平台中的实践
数据之道 | SLA/SLE监控与告警
数据之道 | 进阶版Spark执行计划图
重磅 | eBay提出强大的轻量级推荐算法——洛伦兹因子分解机
实战 | 利用Delta Lake使Spark SQL支持跨表CRUD操作
 ?点击
?点击
eBay大量优质职位,等的就是你















 2083
2083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









