







笔者在伯克利交流期间上了Hilfinger教授的CS61B: Data Structure and Advanced Programming.
在做最后一个Project GitLet的时候发现了一篇能启发Git本质的文章,现在把它翻译成中文。
原文用的是Functional Data Structure,不太确定是翻译成函数式数据结构还是功能性数据结构,暂时翻译成函数式数据结构。
ps. Prof. Hilfinger的课非常值得一上。
以下是正文:
尽管像Git这样的分散版本控制现在有很大的发展势头,但它们似乎仍比像SVN这样的集中式的版本控制更复杂。
我猜这是因为我们倾向于比较两者来解释Git:当您在SVN中执行X时,您会在Git中执行Y。
我认为我们应该从真正的意义上谈论Git:一种纯粹的函数式数据结构。学习熟练使用Git意味着学习如何操纵该数据结构。
如果您不熟悉函数式数据结构,我这么说似乎对你没有太大帮助。事实证明,为了搞懂它,我们只需要简要介绍该主题。因此让我们现在快速探讨该主题,然后再将讨论带回Git。
预备知识
函数式数据结构本质上是一个不变的数据结构:其值永远不变。但是,与C#的ReadOnlyCollection不同,ReadOnlyCollection类没有任何函数比如插入,函数式数据结构支持诸如插入或删除之类的操作,但它们并不是原地(in place,即不产生新的数据结构,译者按)。而是通过创建全新的更新完的结构来处理这些操作。
例如,一个典型的列表[3,2,1]。如果此列表是可变的,并且我们将值4插入此列表首(头),则它现在成了[4,3,2,1]。我们已对其原地(in place)进行了修改,它成了新的值。旧值[3,2,1]消失了。
现在正在查看此列表的人看到的将是是[4,3,2,1]。而如果有人正在遍历该列表,那么他们现在会得到一个令人愉悦的exception。
在函数式模型中不会发生这种情况。相反,当我们将4插入列表时,它将创建一个新列表[4,3,2,1],而无需修改原始列表。列表[4,3,2,1]和[3,2,1]现在都存在,并且正在查看列表[3,2,1]的任何人仍然可以看到该值。
您可能会认为这似乎效率很低。如果我们可以同时访问列表[4,3,2,1]和[3,2,1],即使我们以后可能不再对[3,2,1]感兴趣,我们总是必须将所有这七个元素存储在内存中,对吗?
实际上,函数式数据结构的效率在很大程度上取决于对它们执行的操作以及使用的内部表示形式(当然,就像普通数据结构所做的一样,但是具有一些不同的优势,成本和权衡)。
对于(单链接)列表,如果我们只想在头部插入,我们可以通过存储以下元素来有效地处理这种情况:
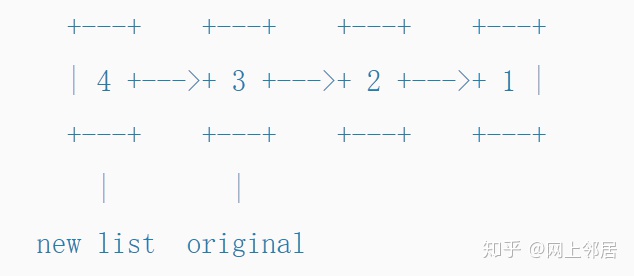
我们将新值4放入新节点,它后面是到列表的其余部分([3,2,1])的一个引用。原始值用原有的从3的节点开始的引用表示。
如果其他人只对节点(3)有引用,他们将永远不会注意到发生了更新(加入了4),这种情况不适用于双向链表。
老实说,即使它们共享内存中的元素,我们也可以独立访问列表[4,3,2,1]和[3,2,1],因为没有就地(in place)修改的操作,我们无法感知两者区别。
实际上,我们可以走得更远:如果其他人想将元素9插入[3,2,1]的开头,则他们可以独立于我们完成此操作:重复使用相同的元素。

我们当然也可以将这样的元素存储到一个不可变的列表中,但这充满了危险:例如,如果我们要更新列表[4,3,2,1]中的元素3,使用列表[9,3,2,1]的人也会被更新。
但是……如果我真的需要更新元素3,将其设置为5,该怎么办?因为我们不允许执行任何就地更新,因此我们必须将一些节点复制到更新后的列表中。这三个操作的结果可能如下所示:

如果我们从每个指针开始,向后看,我们将看到它同时代表了所有四个列表[4,5,2,1],[4,3,2,1],[9,3,2,1]和[3,2,1]。
如果我们确实有兴趣同时存储所有这些值,那么与使用可变列表相比,这种表示方法实际上要紧凑得多。
纯函数数据结构在多线程编程中可能非常有用,因为来自不同线程的更改不会互相干扰。
Git
现在,这与Git和版本控制有什么关系?在版本控制系统中,我们要做的是:
- 要使用新版本更新我们的代码库,并保持旧版本可用。
- 在单个代码库上进行协作,而更新不会以不可预测的方式相互干扰
纯函数数据结构可以让你:
- 更新数据结构,同时保持数据的旧值可用
- 在一个地方更新结构而不干扰其他人对该结构的更新。
如果您现在认为函数式数据结构对于版本控制系统来说似乎是一个很好的选择,那么您是对的。
实际上,我甚至可以说Git基本上是一个纯函数的数据结构,带有允许您对其执行操作的命令行客户端。
为了完成类比,我们需要用commits替换上面列表里的数字。 Git commits是历史记录里你整个工作状态的独立副本;是你工作目录的完整快照。
在示例中我们称为列表的我们可以在Git中称为历史记录(history).
假设我们在master分支中有一个包含commit A,B和C(按顺序)的repository。我们已告知Git在开发过程中将工作目录的整个状态存储三遍。我们可以将这种状态的发展表示为历史记录[C,B,A]。
实际上,每个commit都具有类似于提交信息的元数据,但是为了简单起见,我们将其忽略,因为这无关紧要。以图形形式表示:

Commiting(提交)
如果我们执行另一次commit,这与将其添加到历史记录的头部相同。 Git甚至将名称HEAD用于当前active的commit。
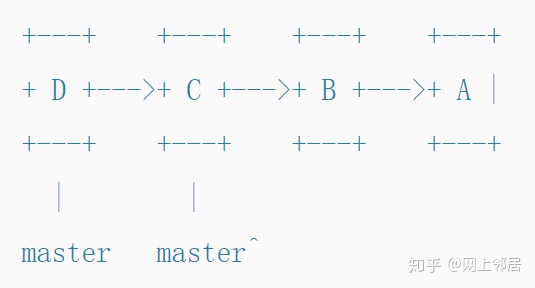
当git执行一次commit时,它将为我们移动当前分支指针,并使master指向历史记录[D,C,B,A]。
我们仍然可以通过master ^(master的父指针)来引用历史记录[C,B,A]。在该状态下工作的其他任何人都不会注意到我们的更改。
Amending(修改)
如果您使用过Git,则可能会意识到可以使用commit --amend更新最近的commit。
但是您真的可以更新一个commit吗?实际上,您不能。 Git只是创建一个新的commit并将分支指针移向它。
我们仍然可以使用git reflog找到旧值,并且可以通过其哈希值(commit使用SHA1 code对内容生成唯一的hash code并可以在git log里看到,译者按)来引用旧值(比如ef4d34)。情况如下所示。
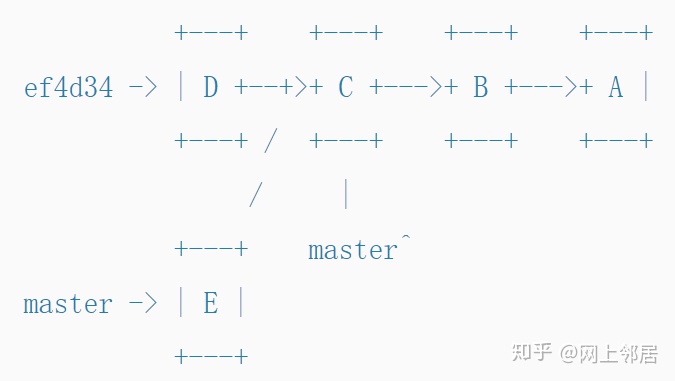
Branching(分支)
如上所示,每次执行commit --amend时,基本上都会创建一个新分支(repository graph中有一个fork)。
分支唯一要做的就是引入一个新名称,我们可以使用它来引用commit。我们甚至可以使用命令git checkout -b branch ef3d34来获取丢弃的提交ef4d34并创建指向它的分支。
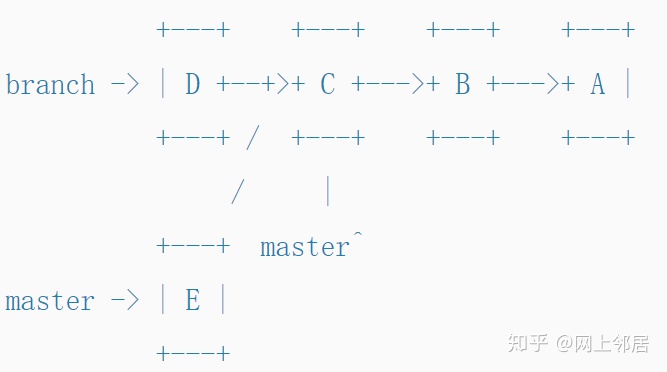
通常,我们通过为当前HEAD创建一个新名称来在Git中进行分支,但是如果您将Git理解为函数式数据结构,就会意识到没有什么可以阻止您在树中的任何commit处创建分支。
Rebasing(变基 别想歪)
当我们在列表示例中更新一个节点再回到列表中时,我们必须在更新元素之前添加列表中的每个节点(在我们的示例中,这是单个节点4,但可以是任意数量的节点)。
在Git中,这称为重播提交(replaying commits),而用于执行此操作的命令称为rebase。
为了更新旧的提交,我们添加了-i标志以执行Git中称为交互式变基的操作。
假设我们要使用新的提交消息来更新提交C。我们通过check out commit D并使用git rebase -i C来实现:
> git checkout D
> git rebase -i C这将打开Git用于提交消息的相同编辑器,并带有以下命令列表:
pick cd3ff32 <C's commit message>
pick a65a671 <D's commit message>
# some helpful comments from git如果我们更改commit C用于edit的命令,Git将允许我们在replay后续commit之前edit该commit。
edit cd3ff32 <C's commit message>
pick a65a671 <D's commit message>当我们保存文件并关闭它时,git将开始rebase。
它会在commit C处立即停止,以允许我们对其进行edit。
Stopped at cd3ff32... <C's commit message>
You can amend the commit now, with
git commit --amend
Once you are satisfied with your changes, run
git rebase --continue基本上,这些message说明了一切。我们可以根据需要自由edit commits。
然后,我们调用commit --amend创建更新的commit,并使用git rebase --continue继续进行rebase。
当我们选择命令pick时,其余的commit将一个接一个地replay(除非您最终遇到merge conflict,在这种情况下,Git将停止并让您在继续之前对其进行修复)。
现在,我们完整的repository如下所示。

上图对您来说应该看起来很熟悉。希望您也理解为什么Git的rebase命令会创建所有新的commits。
Git是一个函数式数据结构,不允许更改任何现有的commit。
由于rebase引入了新的commit链,因此我们希望能够对该新链进行基本的控制。
当然,我们可以这样做:rebase -i,这允许我们重新排序(re-order),压缩(squash)或删除(delete) commits,以及在任何时候引入新commit,例如将一个commit分成多个部分,甚至可以从repository的其他地方开始(使用--onto标志)。
在远程分支的更新基础上向前移植(forward-porting)本地的changes的标准rebase workflow只是rebase更强大功能的特例。
Merging(合并)
到目前为止,我们还没有提到merge。 Git允许我们将两个branches合并为一个:
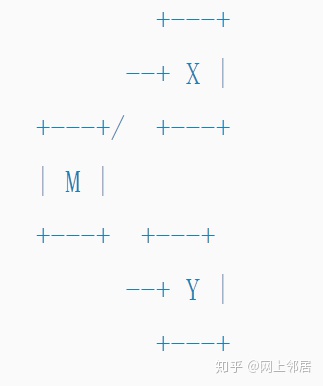
merge为我们的模型引入了更多的复杂性。
现在它不再是一棵树,而是一个非循环图。
这实际上并没有太大变化,但是值得注意的是,尽管rebase看上去很复杂,但是只有merge命令会引入真正额外的概念上的复杂性。
Rebase可以理解为仅在新方向上应用新commits。
但merge是完全不同的操作。
可以像这样将两个部分组合成一个部分的数据结构甚至具有一个特殊的名称:它们是一致的持久的(confluently persistent)。
函数式数据结构的另一个名称是永久性(persistent)。为了不将其与诸如物理磁盘之类的永久性介质上的存储概念混淆,我避免了使用该术语。
结论
Git可以准确地理解为相当简单的函数式数据结构。
我们可以将版本控制作为使用该数据结构的一种新兴属性,而不是用版本控制来解释Git。
我认为以这种方式谈论Git会比将Git与集中式版本控制系统进行比较,能更好地准确传达Git的简单性和性能(power)。
实际上,以这种方式看,我认为Git在概念上比SVN更简单。
Git可能被认为更复杂的唯一原因是,这种简单性使我们能够在实际中实现更有趣的工作流(workflow)。
如果您曾经觉得Git令人生畏,请记住它简单的结构,以及这个事实:在函数式数据结构中插入的任何内容永远不会真正丢失,并可以恢复。 (通过检查您的reflog)















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









