





大纲:
- df.groupby(col,sort=False)
- df.groupby(col)
- df.groupby(col).mean()
df.groupby(col),返回一个按列进行分组的groupby对象;
import 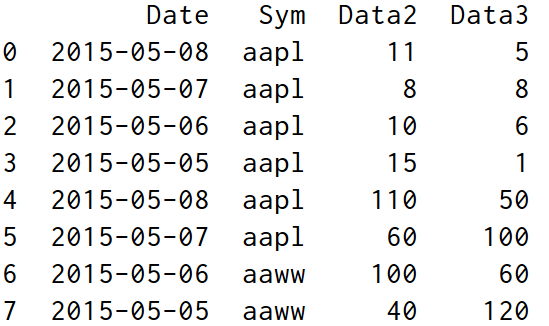
import [
('2015-05-05', Date Sym Data2 Data3
3 2015-05-05 aapl 15 1
7 2015-05-05 aaww 40 120),
('2015-05-06', Date Sym Data2 Data3
2 2015-05-06 aapl 10 6
6 2015-05-06 aaww 100 60),
('2015-05-07', Date Sym Data2 Data3
1 2015-05-07 aapl 8 8
5 2015-05-07 aapl 60 100),
('2015-05-08', Date Sym Data2 Data3
0 2015-05-08 aapl 11 5
4 2015-05-08 aapl 110 50)
]
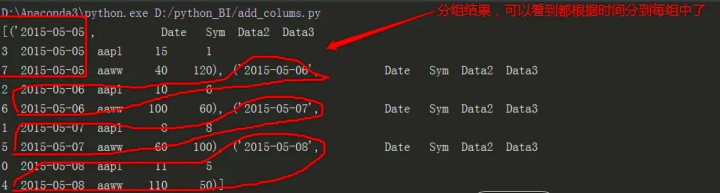
df.groupby(col,sort=False)
import pandas as pd
df2 = pd.DataFrame(
{'Date': ['2015-05-08', '2015-05-07', '2015-05-06', '2015-05-05', '2015-05-08', '2015-05-07', '2015-05-06',
'2015-05-05'],
'Sym': ['aapl', 'aapl', 'aapl', 'aapl', 'aapl', 'aapl', 'aaww', 'aaww'],
'Data2': [11, 8, 10, 15, 110, 60, 100, 40],
'Data3': [5, 8, 6, 1, 50, 100, 60, 120]})
df11 = df2.groupby(df2['Date'],sort=False)
print(list(df11))[
('2015-05-08', Date Sym Data2 Data3
0 2015-05-08 aapl 11 5
4 2015-05-08 aapl 110 50),
('2015-05-07', Date Sym Data2 Data3
1 2015-05-07 aapl 8 8
5 2015-05-07 aapl 60 100),
('2015-05-06', Date Sym Data2 Data3
2 2015-05-06 aapl 10 6
6 2015-05-06 aaww 100 60),
('2015-05-05', Date Sym Data2 Data3
3 2015-05-05 aapl 15 1
7 2015-05-05 aaww 40 120)]
df.groupby(col).mean()
df 

参考:
pandas groupby函数















 4855
4855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









