





在英文实体识别任务中,单词的大小写通常是判断实体的一个重要信号。有不少算法都可以在标准数据集上取得不错的效果,但是文本中字母的大小写不准确时效果会很差。本文介绍一种利用 Truecaser 进行命名实体识别的算法,Truecaser 可以预测句子中每一个字母是大写还是小写。
1.前言
Truecaser 可以判断句子中每个字母的大小写,将没有标好大小写或者大小写错误的句子传入 Truecaser 中,可以转为正确大小写的句子,如下图所示。
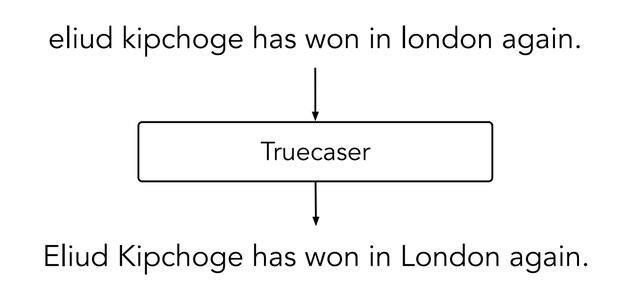
Truecaser
本文介绍一种利用 Truecaser 辅助进行命名实体识别的方法,出自论文《Robust Named Entity Recognition with Truecasing Pretraining》,该论文被 2020 年的 AAAI 收录。
作者认为,在很多语言的命名实体识别 (NER) 任务中,字符的大小写通常是重要的特征,例如英语中人名是大写字母开头的 "my name is Bob"。因此,有不少命名实体识别算法会在大小写特征上出现过拟合现象,当要预测的文本没有准确的大小写时,效果会大打折扣。
为了更好地对未标大小写的文本进行实体识别,作者将一个预训练好的 Truecaser 结合到 BiLSTM-CRF 上,使模型可以自动判别大小写,并将大小写的信息作为特征传递到 BiLSTM-CRF 中。
2.Truecaser 模型
Truecaser 接受一个句子作为输入,并预测句子中每一个字母是大写还是小写,可以看成是字符级别的二分类问题 (U 大写和 L 小写)。其结构如下,首先使用 BiLSTM 得到每一个字母的隐藏层向量,然后用全连接网络预测大小写。
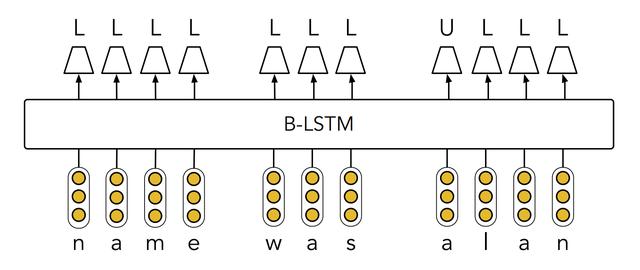
Truecaser 网络结构
对于每一个字符 c,其大小写用下面的公式预测:

Truecaser 预测公式
Truecaser 也会学习得到字符级别的 Embedding,另外 Truecaser 的训练数据也比较容易得到,将标准文本转为小写输入 Truecaser,原来的文本作为预测目标即可。
3.结合 Truecaser 进行命名实体识别
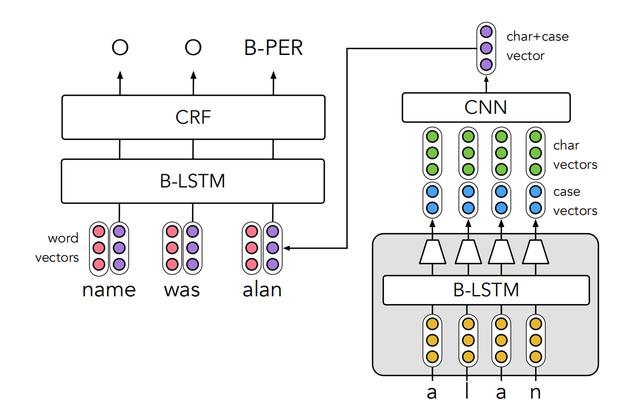
结合 Truecaser 进行命名实体识别
NER 模型采用了 BiLSTM-CRF,对 BiLSTM-CRF 不熟悉的童鞋可以参考一下之前的文章《BiLSTM+CRF 的实现详解》。
BiLSTM-CRF 的输入包括两个部分:预训练的词向量 (如 Glove,Word2Vec 等,上图红色部分) 和单词的 Char Embedding (即单词所有字符的 Embedding,上图紫色部分)。BiLSTM 会将这两种向量拼接在一起,对于第 t 个单词 xt,BiLSTM-CRF 的输入如下:

BiLSTM-CRF 接受的输入
上式中的 f() 用来将单词的所有字符编码成一个 Embedding,即紫色的向量。在论文中是用 CNN 网络作为 f(),也可以使用 BiLSTM。对于单词 i,函数 f() 的输入包括字符 Embedding 和 Truecaser 预测的结果 dc,如下:
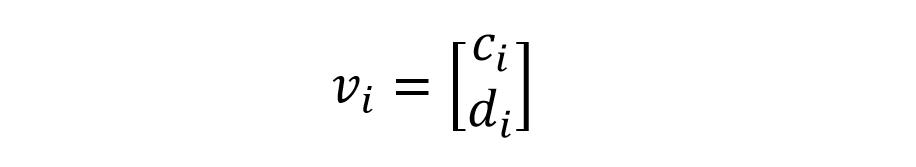
f() 函数的输入
总的来说,模型分为两个部分:
- f(),其输入为单词每一个字符 i 的 Truecaser 预测结果和字符 i 的Embedding,用于获取单词的 char+case vector。
- NER 模型,即 BiLSTM,对于每一个单词 w,其输入为 w 的预训练词向量和 f(w) 的向量。
4.参考文献
Robust Named Entity Recognition with Truecasing Pretraining















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









