







 本文介绍了五种聚类算法:K-means、Mean-Shift、DBSCAN、GMM-EM和层次聚类。K-means算法简单快速,但易受初始点和K值选择影响;Mean-Shift无需预知类数量,但窗口半径选择重要;DBSCAN可处理不规则形状簇,但参数调优复杂;GMM-EM利用高斯混合模型,支持椭圆簇形状,但计算复杂;层次聚类则分为凝聚和分裂两种,不需要预知簇数量,但效率较低。文中还探讨了各算法的优缺点和详细步骤。
本文介绍了五种聚类算法:K-means、Mean-Shift、DBSCAN、GMM-EM和层次聚类。K-means算法简单快速,但易受初始点和K值选择影响;Mean-Shift无需预知类数量,但窗口半径选择重要;DBSCAN可处理不规则形状簇,但参数调优复杂;GMM-EM利用高斯混合模型,支持椭圆簇形状,但计算复杂;层次聚类则分为凝聚和分裂两种,不需要预知簇数量,但效率较低。文中还探讨了各算法的优缺点和详细步骤。


今天的主题是聚类算法,小结一下,也算是炒冷饭了,好久不用真忘了。
小目录:
1.K-means聚类 2.Mean-Shift聚类 3.Dbscan聚类 4.层次聚类 5.GMM_EM聚类【1】.K-means聚类
1.算法介绍
kmeans算法又名k均值算法,K-means算法中的k表示的是聚类为k个簇,means代表取每一个聚类中数据值的均值作为该簇的中心,或者称为质心(质量中心,可以利用球坐标进行三重积分求解),即用每一个的类的质心对该簇进行描述。可以看下图直观点:
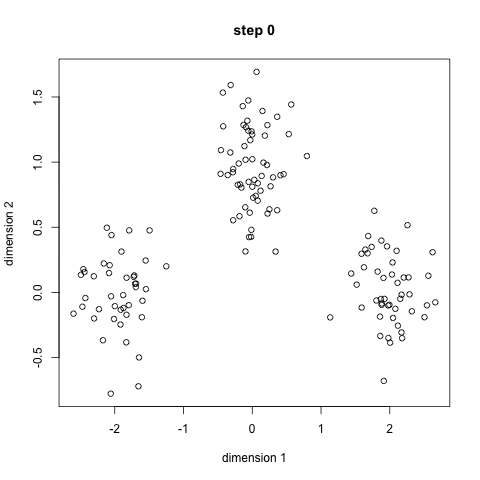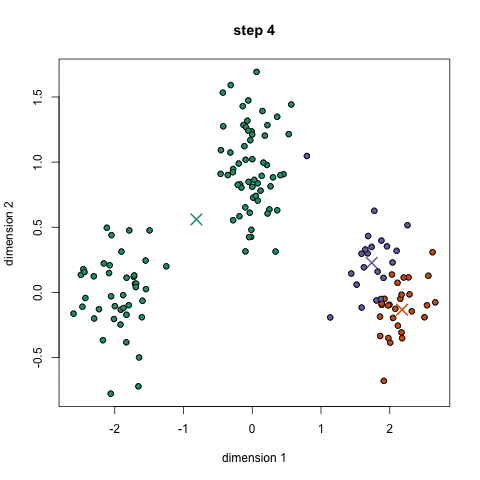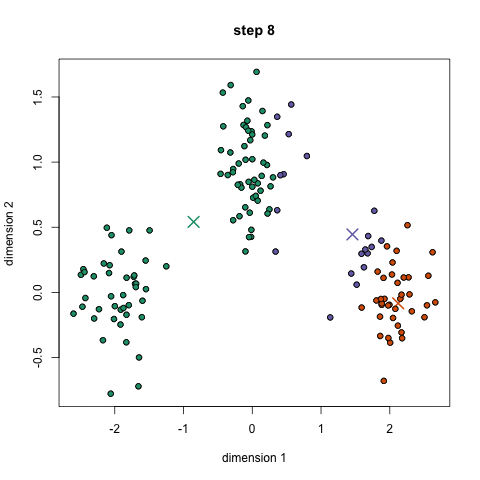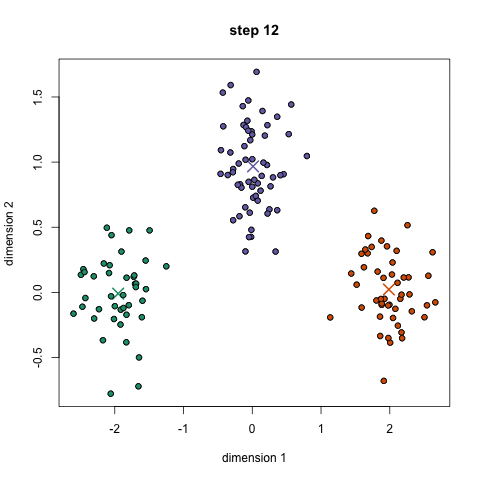
2.算法思想
先从样本集中随机选取 k个样本作为簇中心,并计算所有样本与这 k个“簇中心”的距离,对于每一个样本,将其划分到与其距离最近的“簇中心”所在的簇中,对于新的簇重新计算各个簇的新的“簇中心”,然后再继续距离知道簇中心不发生变化。
根据以上描述,我们可以得到实现kmeans算法的主要四点:
(1)簇个数 k 的选择
(2)各个样本点到“簇中心”的距离
(3)根据新划分的簇,更新“簇中心”
(4)重复上述2、3过程,直至"簇中心"没有移动
3.优缺点
优点:
1.容易实现,计算速度快
缺点:
1.可能收敛到局部最小值,在大规模数据上收敛较慢;我们必须提前知道数据有多少类/组。
2.K值需要预先给定,属于预先知识,很多情况下K值的估计是非常困难的,对于像计算全部微信用户的交往圈这样的场景就完全的没办法用K-Means进行。对于可以确定K值不会太大但不明确精确的K值的场景,可以进行迭代运算,然后找出Cost Function最小时所对应的K值,这个值往往能较好的描述有多少个簇类。
3.K-Means算法对初始选取的聚类中心点是敏感的,不同的随机种子点得到的聚类结果完全不同
4.K-Means算法对离群点的数据进行聚类时,K均值也有问题,这种情况下,离群点检测和删除有很大的帮助。(异常值对聚类中心影响很大,需要离群点检测和剔除)
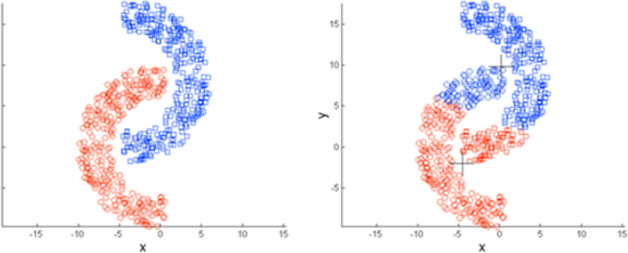
4.K-Means算法并不是适用所有的样本类型。它不能处理非球形簇、不同尺寸和不同密度的簇。如下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7313
7313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









