





问题背景:如题这个问题涉及到一个技术方案的选择,我们纠结于选择函数指针方案还是选择函数调用方案,为了支撑架构选择,做了一些试验。
理论分析:直观上看应该是函数调用开销更小。函数指针调用方案中需要先访问数据区,再访问函数,增加指令开销,同时,数据取值与函数指令加载必须串行执行,影响CPU流水性能;函数调用方案可以做内联优化。
首先,为了防止gcc进行内联优化,设计func.c供主程序进行跨文件访问,func.c如下:
int a = 1;
void func0()
{
a++;
}
void func1()
{
a++;
}
void func2()
{
a++;
}
...
void func9()
{
a++;
}func.h为func对外提供的接口,func.h如下:
void func0();
void func1();
void func2();
...
void func9();构造调用函数,直接进行文件调用的代码hello.c如下:
#include <stdio.h>
#include <time.h>
#include "func.h"
#define N 100000000
int main()
{
clock_t start, end;
start = clock();
for(int i = 0; i < N; i++)
{
func0();
func1();
func2();
func3();
func4();
func5();
func6();
func7();
func8();
func9();
}
end = clock();
printf("%ld", end - start);
}与之对比的用函数指针进行调用的代码hellocompare.c如下:
#include <stdio.h>
#include <time.h>
#include "func.h"
#define N 100000000
typedef void (*ffunc)();
int main()
{
ffunc fffunc[10] = {func0, func1, func2, func3, func4, func5, func6, func7, func8, func9};
clock_t start, end;
start = clock();
for(int i = 0; i < N; i++)
{
fffunc[0]();
fffunc[1]();
fffunc[2]();
fffunc[3]();
fffunc[4]();
fffunc[5]();
fffunc[6]();
fffunc[7]();
fffunc[8]();
fffunc[9]();
}
end = clock();
printf("%ld", end - start);
}编译:
gcc -O0 -o a0 hello.c func.c func.h
gcc -O0 -o b0 hellocompare.c func.c func.h
类似地,O1 O2 O3优化命名为a1/b1 a2/b2 a3/b3,运行5次取平均,得到下表:
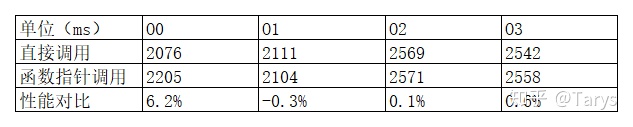
忽略掉1%以下的的情况,我们可以认为O1 O2 O3优化下的两种方式没有区别。在O0下,也就是说,不带任何优化,函数指针调用方式会损失6%的性能,证实了本文开头的分析。
这个小实验到这里还不算完,有两个问题:
- O1究竟做了什么,让两种方式性能没差别;
- 为什么优化等级高的程序,在这个场景下反而性能会变差。
问题1:
通过gcc -O1 -S hello.c func.c func.h,能看到生成的汇编,发现两种方式的汇编代码一模一样。O0下的直接调用的汇编代码:
movl $0, %eax #,
call func0@PLT #函数指针调用汇编代码:
movq -96(%rbp), %rdx # fffunc, _1
movl $0, %eax #,
call *%rdx # _1果然,多了一行额外的指令。
问题2:
老夫愚钝,汇编语言已经还给了大学老师,短时间内无望搞清楚了。
综上,O0下,函数指针调用有6%损失,但O0以上与直接调用的性能没有差别。所以在O0以上,我们应只考虑内联优化带来的巨大收益。














 3121
3121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









