






最后这篇我们来一起看看Redis相关的两个应用:
Redis消息队列
分布式锁
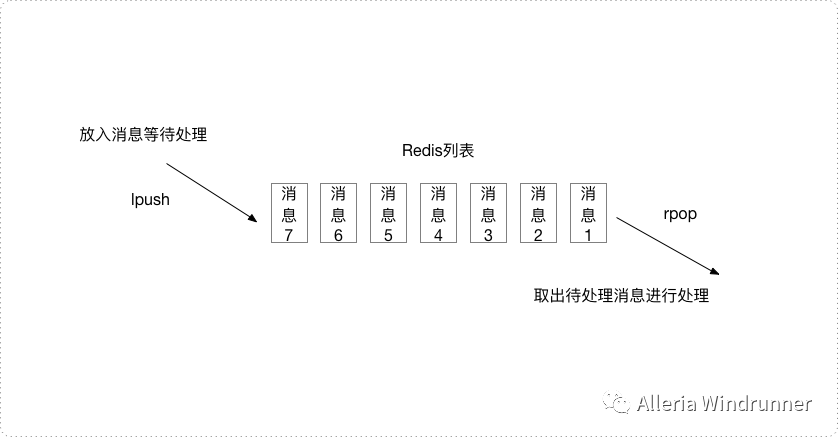
队列模式
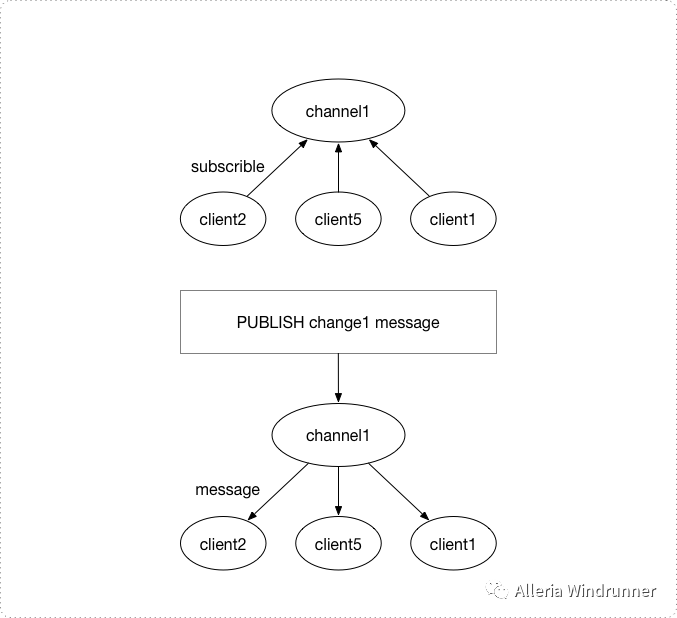
发布订阅模式
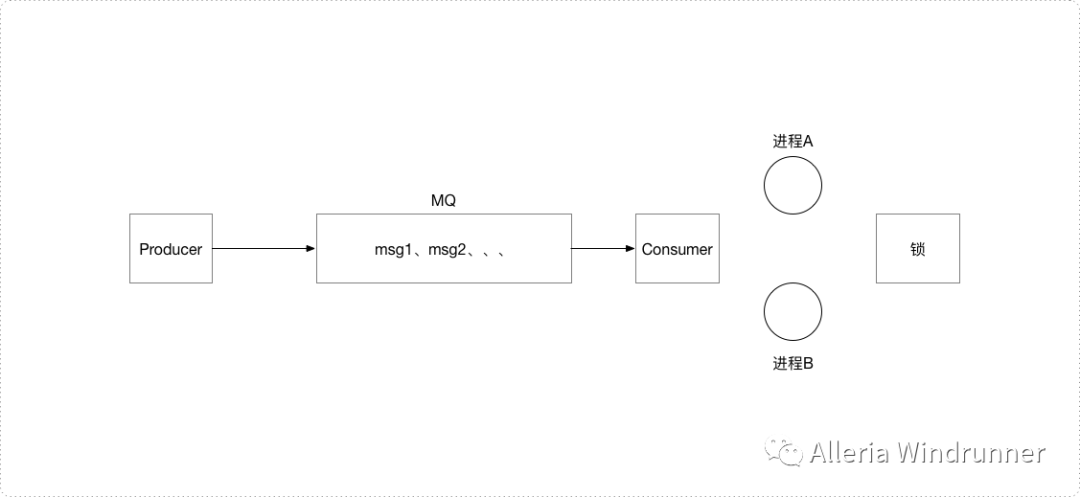
防止用户重复下单
MQ消息去重
订单操作变更
库存超卖
哪些情况下我们需要使用锁,从上面业务场景我们可以抽象出如下业务模型:
- 共享资源
- 一次请求(处理)拥有唯一的Id
那么解决方案是什么?我们需要解决共享资源的互斥,共享资源的串行化问题,那么这其实就是锁的问题。
关于锁的处理又可以分为以下几种类型:
- 单应用中使用锁
- 分布式应用中使用锁
在单应用中使用锁我们可以使用最基础的synchronized或者高级一点的ReentrantLock。而在分布式应用中我们只能使用分布式锁。
Redis的分布式锁
首先我们来说一下Redis分布式锁实现的原理:利用Redis的单线程特性对特性的共享资源进行串行化处理。获取锁
获取锁的实现方式有以下两种:使用set命令实现
使用setnx命令实现
/*** 使用redis的set 命令实现获取分布式锁* @param lockKey 可以就是锁* @param requestId 请求ID,保证同一性 uuid+threadID* @param expireTime 过期时间,避免死锁* @return*/public boolean getLock(String lockKey,String requestId,int expireTime) { //NX:保证互斥性 // hset 原子性操作 String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime); if("OK".equals(result)) { return true; } return false;}public boolean getLock(String lockKey,String requestId,int expireTime) { Long result = jedis.setnx(lockKey, requestId); if(result == 1) { //成功设置 失效时间 jedis.expire(lockKey, expireTime); return true; } return false;}释放锁
常见的释放锁的方式有两种:del命令实现
redis+lua脚本实现
/*** 释放分布式锁* @param lockKey * @param requestId */public static void releaseLock(String lockKey,String requestId) { if (requestId.equals(jedis.get(lockKey))) { jedis.del(lockKey); }}
另外一种实现方式:public static boolean releaseLock(String lockKey, String requestId) { String script = "if redis.call('get', KEYS[1]) == ARGV[1] then returnredis.call('del', KEYS[1]) else return 0 end"; Object result = jedis.eval(script, Collections.singletonList(lockKey),Collections.singletonList(requestId)); if (result.equals(1L)) { return true; } return false;}生产环境中的分布式锁
落地生产环境用分布式锁,一般采用开源框架,比如Redisson。下面来讲一下Redisson对Redis分布式锁的实现。具体的实现方式如下: 首先我们加入jar包的依赖:<dependency> <groupId>org.redissongroupId> <artifactId>redissonartifactId> <version>2.7.0version>dependency>public class RedissonManager { private static Config config = new Config(); //声明redission对象 private static Redisson redisson = null; //实例化redisson static{ config.useClusterServers() // 集群状态扫描间隔时间,单位是毫秒 .setScanInterval(2000) //cluster方式至少6个节点(3主3从,3主做sharding,3从用来保证主宕机后可以高可用) .addNodeAddress("redis://127.0.0.1:6379" ) .addNodeAddress("redis://127.0.0.1:6380") .addNodeAddress("redis://127.0.0.1:6381") .addNodeAddress("redis://127.0.0.1:6382") .addNodeAddress("redis://127.0.0.1:6383") .addNodeAddress("redis://127.0.0.1:6384"); //得到redisson对象 redisson = (Redisson) Redisson.create(config);} //获取redisson对象的方法 public static Redisson getRedisson(){ return redisson; }}public class DistributedRedisLock { //从配置类中获取redisson对象 private static Redisson redisson = RedissonManager.getRedisson(); private static final String LOCK_TITLE = "redisLock_"; //加锁 public static boolean acquire(String lockName){ //声明key对象 String key = LOCK_TITLE + lockName; //获取锁对象 RLock mylock = redisson.getLock(key); //加锁,并且设置锁过期时间3秒,防止死锁的产生 uuid+threadId mylock.lock(2,3,TimeUtil.SECOND); //加锁成功 return true; } //锁的释放 public static void release(String lockName){ //必须是和加锁时的同一个key String key = LOCK_TITLE + lockName; //获取所对象 RLock mylock = redisson.getLock(key); //释放锁(解锁) mylock.unlock(); }}public String discount() throws IOException{ String key = "test123"; //加锁 DistributedRedisLock.acquire(key); //执行具体业务逻辑 dosoming //释放锁 DistributedRedisLock.release(key); //返回结果 return soming;}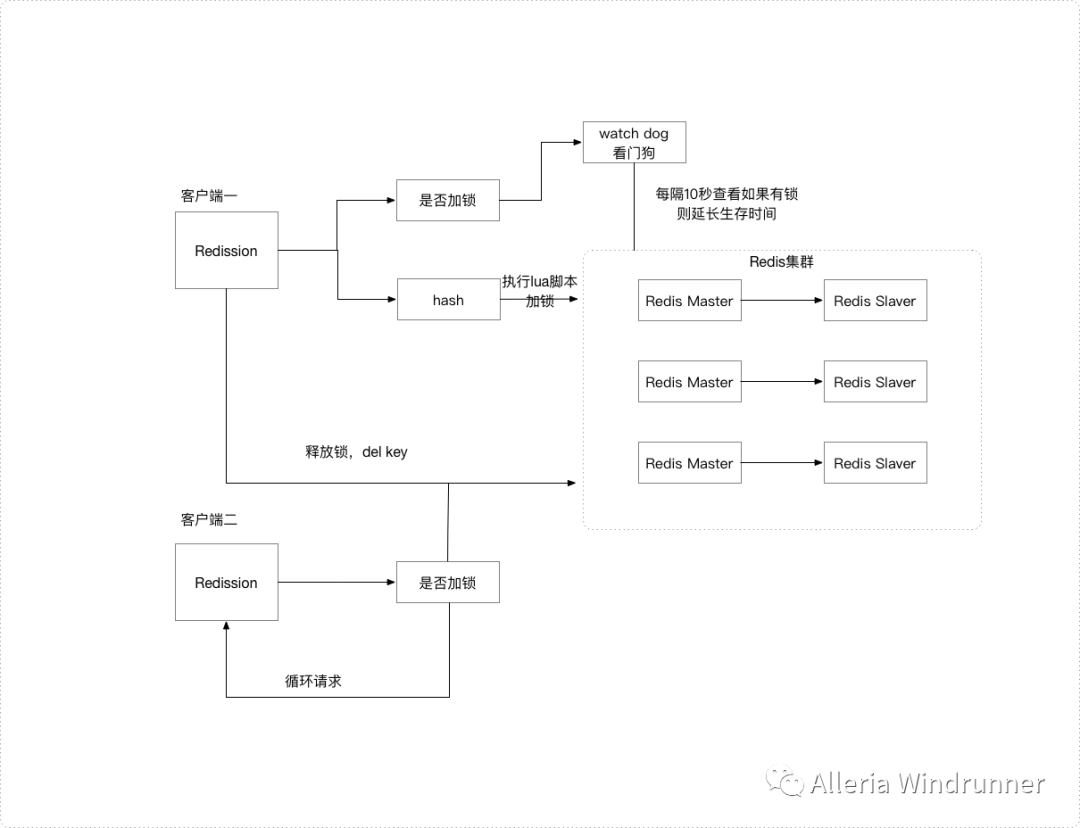
加锁机制
如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。发送lua脚本到redis服务器上,脚本如下:"if (redis.call('exists',KEYS[1])==0) then "+"redis.call('hset',KEYS[1],ARGV[2],1) ; "+"redis.call('pexpire',KEYS[1],ARGV[1]) ; "+"return nil; end ;" +"if (redis.call('hexists',KEYS[1],ARGV[2]) ==1 ) then "+"redis.call('hincrby',KEYS[1],ARGV[2],1) ; "+"redis.call('pexpire',KEYS[1],ARGV[1]) ; "+"return nil; end ;" +"return redis.call('pttl',KEYS[1]) ;"incrby myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1myLock:{"8743c9c0-0795-4907-87fd-6c719a6b4586:1":2 }#如果key已经不存在,说明已经被解锁,直接发布(publish)redis消息 "if (redis.call('exists', KEYS[1]) == 0) then redis.call('publish', KEYS[2], ARGV[1]); return 1; end;" +# key和field不匹配,说明当前客户端线程没有持有锁,不能主动解锁。"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +# 将value减1"return nil;end; local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +# 如果counter>0说明锁在重入,不能删除key"if (counter > 0) then redis.call('pexpire', KEYS[1], ARGV[2]); return 0; " +# 删除key并且publish 解锁消息"else redis.call('del', KEYS[1]); redis.call('publish', KEYS[2], ARGV[1]); return 1; end; return nil;














 3174
3174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









