






大家好,今日我们继续讲解VBA数组与字典解决方案,今日讲解第54讲内容:利用字典和数组,提取C列相同但B列不相同的数据,回填时按行分开。
其实字典本身就是一个数组,一个看视很简单的数组,有两个元素KEYS和ITEMS,在讲字典时经常会用到它自身的一个特性:用exists非常方便的判断出一个值是否在字典中存在,也给我们的实际工作处理带来了很多遐想的空间。各种组合可以灵活运用,今日要讲的实例是将一个工作表中C列相同但B列不同的值提取出来并按行回填。
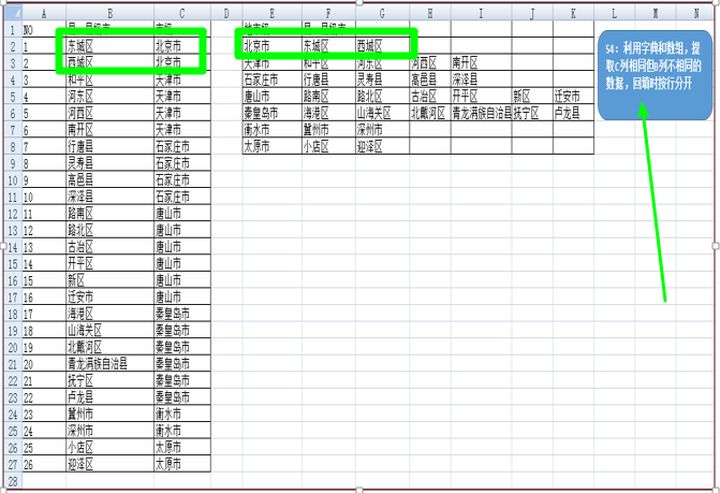
数据如下:

我们看列的数据:对于C列相同的值我们将提取出B列不同的值,如北京,对应的东城区和西城区,天津对应的是和平区、河东区、河西区、南开区等等,那么如何让VBA代码自动完成这种计算呢?我们今日将利用字典来完成,同时为了读者朋友在实际工作中不同的需求,我在程序设计时留出些余地给大家发挥。下面看我给出的代码设计:
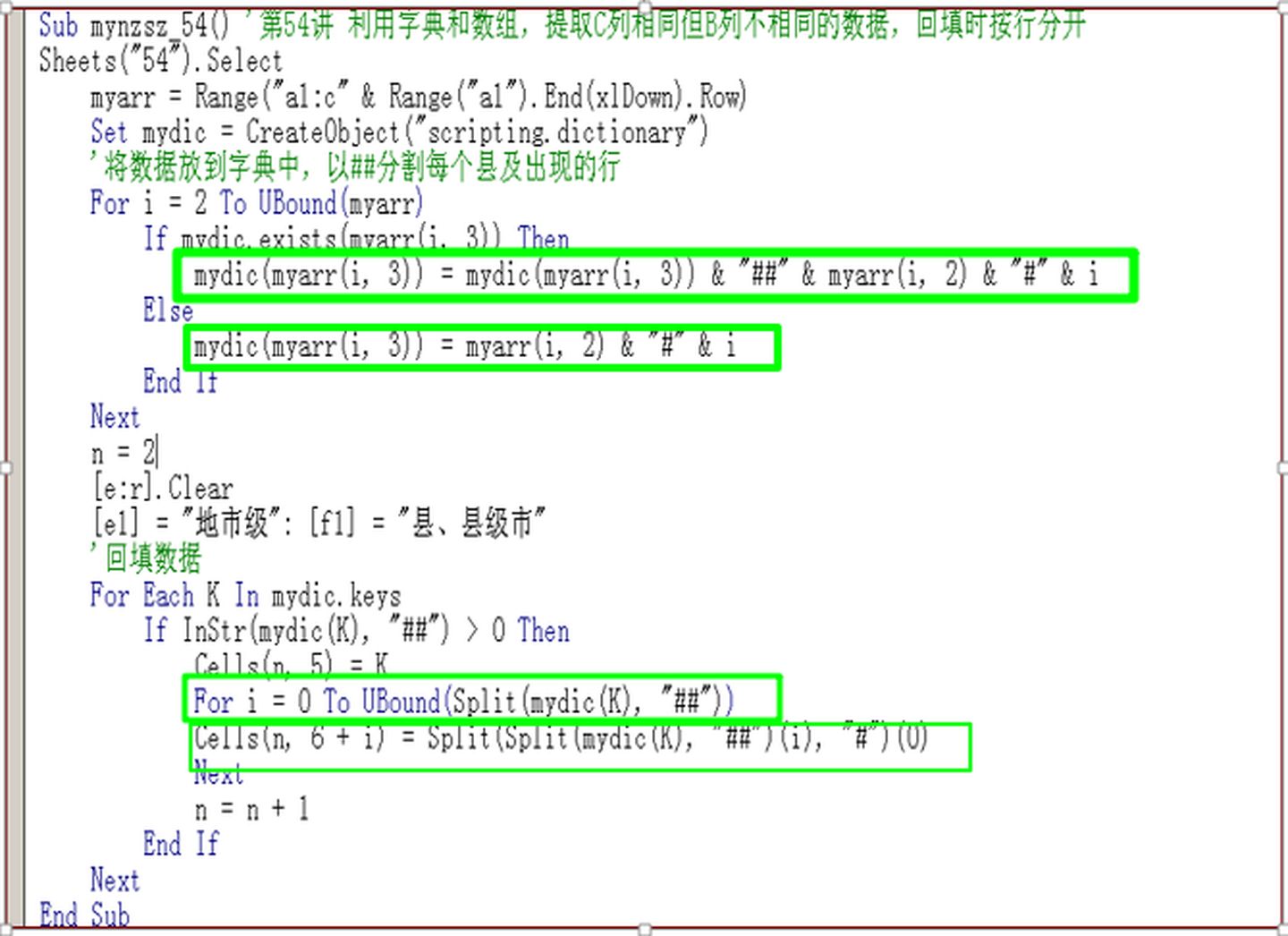
Sub mynzsz_54() '第54讲 利用字典和数组,提取C列相同但B列不相同的数据,回填时按行分开
Sheets("54").Select
myarr = Range("a1:c" & Range("a1").End(xlDown).Row)
Set mydic = CreateObject("scripting.dictionary")
'将数据放到字典中,以##分割每个县及出现的行
For i = 2 To UBound(myarr)
If mydic.exists(myarr(i, 3)) Then
mydic(myarr(i, 3)) = mydic(myarr(i, 3)) & "##" & myarr(i, 2) & "#" & i
Else
mydic(myarr(i, 3)) = myarr(i, 2) & "#" & i
End If
Next
n = 2
[e:r].Clear
[e1] = "地市级": [f1] = "县、县级市"
'回填数据
For Each K In mydic.keys
If InStr(mydic(K), "##") > 0 Then
Cells(n, 5) = K
For i = 0 To UBound(Split(mydic(K), "##"))
Cells(n, 6 + i) = Split(Split(mydic(K), "##")(i), "#")(0)
Next
n = n + 1
End If
Next
End Sub
代码截图:
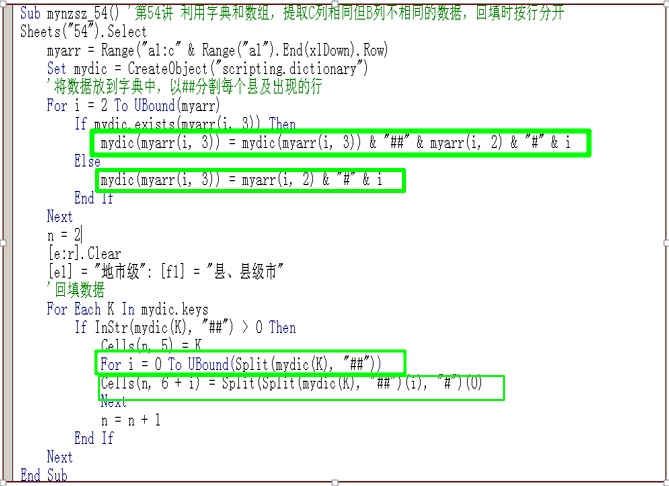
代码解析:
1 上述代码实现了C列数据相同,B列数据的按行输出。
2 myarr = Range("a1:c" & Range("a1").End(xlDown).Row)
上述代码将数据装入数组
3 Set mydic = CreateObject("scripting.dictionary")
'将数据放到字典中,以##分割每个县及出现的行
For i = 2 To UBound(myarr)
If mydic.exists(myarr(i, 3)) Then
mydic(myarr(i, 3)) = mydic(myarr(i, 3)) & "##" & myarr(i, 2) & "#" & i
Else
mydic(myarr(i, 3)) = myarr(i, 2) & "#" & i
End If
Next
上述代码将数据组合成类似于:东城区#2##西城区#3、和平区#4##河东区#5##河西区#6##南开区#7
4 For Each K In mydic.keys
If InStr(mydic(K), "##") > 0 Then
Cells(n, 5) = K
For i = 0 To UBound(Split(mydic(K), "##"))
Cells(n, 6 + i) = Split(Split(mydic(K), "##")(i), "#")(0)
Next
n = n + 1
End If
Next
上述代码利用split函数,首先在键的集合中建立一个For Each循环;对于对应于键的每一个键值进行判断。
如果存在“##”,那么此键值(这个键值此时是一个字符串),将被按“##”分割成一个数组,这个数组是一个一维数组,如“和平区#4##河东区#5##河西区#6##南开区#7”被分割成(”和平区#4”,”河东区#5”,”河西区#6”,南开区#7”)这样一个数组,然后在每个数组的元素中进行循环,对于每一个数组元素以“#”分割成数组,如上面的第一个数组元素:”和平区#4”,分割成:(”和平区”,”4”),然后取序号为0的元素就是”和平区”了,这就是上面两重循环的意义。Split(mydic(K), "##")(i) 即是取Split()形成的一维数组的第i个元素。
这里,我在循环中预留了接口,就是数组的组合中组合进去了行数,在提取中并没有用到行数,在实际的工作中我们可以根据实际的需要进行修正。
这里,把Split()的用法再引申一点:Split(“字符串”,”#”,2) 表示的意义是:将“字符串”按”#”分割成2个元素的一维数组。
下面看代码的运行结果:
今日内容回向:
1 如何实现提取C列相同但B列不相同的数据,回填时按行分开?
2 SPLIT()可以实现二维数组吗?如何理解上面的两重循环?
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









