






SoC设计与应用技术领导厂商Socionext Inc.(以下“Socionext”,或“公司”)宣布,联合大阪大学数据能力科学研究所长原教授研究小组共同开发新型深度学习算法,该算法无需制作庞大的数据集,只需通过融合多个模型便可在极度弱光的条件下进行精准检测物体及图像识别。Socionext笹川幸宏先生和大阪大学长原教授在8月23日至28日(英国夏令时间)举办的欧洲计算机视觉国际会议(ECCV 2020)上报告了这一研究成果。
近年来尽管计算机视觉技术取得了飞速发展,但在低照度环境下车载摄像头、安防系统等获取的图像质量仍不理想,图像辨识性能较差。不断提升低照度环境下图像识别性能依旧是目前计算机视觉技术面临的主要课题之一。CVPR2018中一篇名为《Learning to See in the Dark》的论文曾介绍过利用图像传感器的RAW图像数据的深度学习算法,但这种算法需要制作超过200,000张图像和150多万个批注数据集才能进行端到端学习,既费时又费钱,难以实现商业化落地(如下图1)。
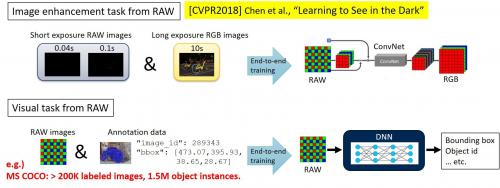
图1:《Learning to See in the Dark》及RAW 图像识别课题
为解决上述课题,Socionext与大阪大学联合研究团队通过迁移学习(Transfer Learning)和知识蒸馏(Knowledge Distillation)等机器学习方法,提出采用领域自适应(Domain Adaptation)的学习方法,即利用现有数据集来提升目标域模型的性能,具体内容如下(如图2):
(1)使用现有数据集构建推理模型;
(2)通过迁移学习从上述推理模型中提取知识;
(3)利用Glue layer合并模型;
(4)通过知识蒸馏建立并生成模型。
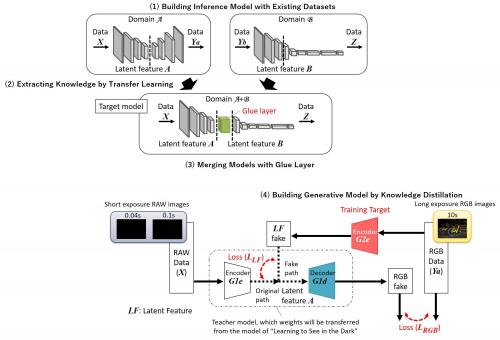
图2:本次开发的领域适应方法(Domain Adaptation Method)
此外,结合领域自适应方法和物体检测YOLO模型,并利用在极端弱光条件下拍摄的RAW图像还可构建“YOLO in the Dark”检测模型。YOLO in the Dark模型可仅通过现有数据集实现对RAW图像的对象检测模型的学习。针对那些通过使用现有YOLO模型,校正图像亮度后仍无法检测到图像的(如下图a),则可以通过直接识别RAW图像确认到物体被正常检测(如下图b)。同时测试结果发现,YOLO in the Dark模型识别处理时所需的处理量约为常规模型组合(如下图c)的一半左右。

图3:《YOLO in the Dark》效果图
本次利用领域自适应法所开发的“直接识别RAW图像”可不仅应用于极端黑暗条件下的物体检测,还可应用于车载摄像头、安防系统和工业等多个领域。未来,Socionext还计划将该技术整合到公司自主研发的图像信号处理器(ISP)中开发下一代SoC,并基于此类SoC开发全新摄像系统,进一步提升公司产品性能,助力产业再升级。(一鸣)














 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









