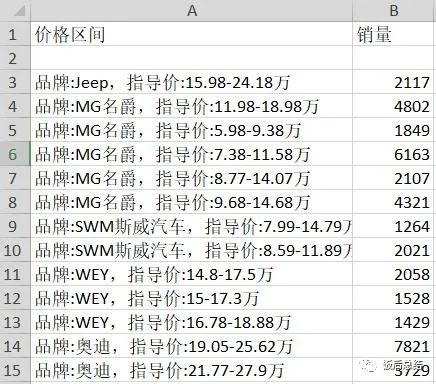
等表明表格格式字段,将数据进行获取,保存在.csv/.xlsx文件内。注意需要根据页面编码,改变编码格式,此例中为UTF-8。import requestsurl="https://www.icauto.com.cn/rank/"response= requests.get(url)response.encoding='utf-8'print(response.text) # 测试页面反爬/页面编码# -*_ coding:UTF-8 -*-import requestsfrom lxml import etreefrom openpyxl import workbook # 写入Excel表所用from openpyxl import load_workbook # 读取Excel表所用url = "https://www.icauto.com.cn/rank/rank_294.html"response = requests.get(url)response.encoding = 'utf-8'tree = etree.HTML(response.content)table = tree.xpath("//table//tr[position()>=1]")wb = workbook.Workbook() # 创建Excel对象ws = wb.active # 获取当前正在操作的表对象ws.append(['车名', '价格区间', '销量']) # 文件标题for i in table: # 遍历tr列表 # 获取当前tr标签下的第一个td标签,并用text()方法获取文本内容,赋值给p p2 = ''.join(i.xpath(".//td[2]//text()")) # 车名 p3 = ''.join(i.xpath(".//td[3]//text()")) # 价格 p4 = ''.join(i.xpath(".//td[4]//text()")) # 销量 # 往表中写入标题行,以列表形式写入! ws.append([p2, p3, p4]) data = { '车名': ''.join(p2.split()), '品牌': ''.join(p3.split()), '销量': ''.join(p4.split()) } print(data)wb.save('50wzy.xlsx') # 保存文件
以下是获取数据库以动态更新数据的脚本。 from pyecharts import options as optsfrom pyecharts.charts import Bar, Line, Pie, Tabimport pymysqlconn = pymysql.connect( host='192.168.20.18', port=3306, user='root', password='toor', db='engin_train_db', charset='utf8')months = ["Jan","Feb","Mar","Apr","May","Jun","Jul"]# 获取游标cursor = conn.cursor(pymysql.cursors.DictCursor)# 执行sql语句sql = 'select * from prall;'rows = cursor.execute("SELECT 月份,SUM(销量) as sum FROM brall GROUP BY 月份;")listsTable = cursor.fetchall()sells=[]for listTable in listsTable: sells.append(int(listTable["sum"]))def bar_datazoom_slider() -> Bar: c = ( Bar() .add_xaxis(months) .add_yaxis("月销售量", sells) .set_global_opts( title_opts=opts.TitleOpts(title="SUV月销售量"), datazoom_opts=[opts.DataZoomOpts()], ) ) return cdef line_markpoint() -> Line: c = ( Line() .add_xaxis(months) .add_yaxis("月销售量", sells) .set_global_opts(title_opts=opts.TitleOpts(title="SUV月销量变化")) ) return ctab = Tab()tab.add(bar_datazoom_slider(), "SUV月销售量")tab.add(line_markpoint(), "SUV月销售量变化")tab.render("suv-per-month111.html")
使用Python进行可视化 在参考多种实现方式的前提下,参考使用pyecharts开源作为本项目的可视化基础,加载pyecharts库函数,根据不同类型的图表加载不同类的库,但在未连接数据库的情况下,需要手动添加数组/列表,或将爬虫数据存储的列表分别读取,作为图表的各类别项,再使用遍历进行写入。经过参数调整,可以于库函数全局变量、或是类别局部变量调整进行自定义,改变图表属性。下例为Bar()柱状图: def bar_datazoom_slider():柱状图表内缩放属性; def line_markpoint():折线图表内标记点属性; Bar()/Line().add为变量调整; .render()渲染画图,输出图像保存为html文件。 from pyecharts import options as optsfrom pyecharts.charts import Bar, Line, Pie, Tabmonths = ["2020-07","2020-06","2020-05","2020-04","2020-03","2020-02","2020-01","2019-12","2019-11","2019-10","2019-09","2019-08","2019-07","2019-06","2019-05","2019-04","2019-03","2019-02","2019-01"]sells = ["1664826","1720593","1673900","1536600","1039532","216481","1696520","2213089","2056669","1927669","1930637","1652908","1527912","1727910","1561172","1574877","2019443","1219497","2021089"]def bar_datazoom_slider() -> Bar: c = ( Bar() .add_xaxis(months) .add_yaxis("2019/1月-2020/7月汽车总销售量", sells) .set_global_opts( title_opts=opts.TitleOpts(title="各月销售量"), datazoom_opts=[opts.DataZoomOpts()], ) ) return cdef line_markpoint() -> Line: c = ( Line() .add_xaxis(months) .add_yaxis("月销售总量", sells) .set_global_opts(title_opts=opts.TitleOpts(title="汽车月总销量变化")) ) return ctab = Tab()tab.add(bar_datazoom_slider(), "各月销售量")tab.add(line_markpoint(), "各月销售量变化")tab.render("tab-per-month.html")
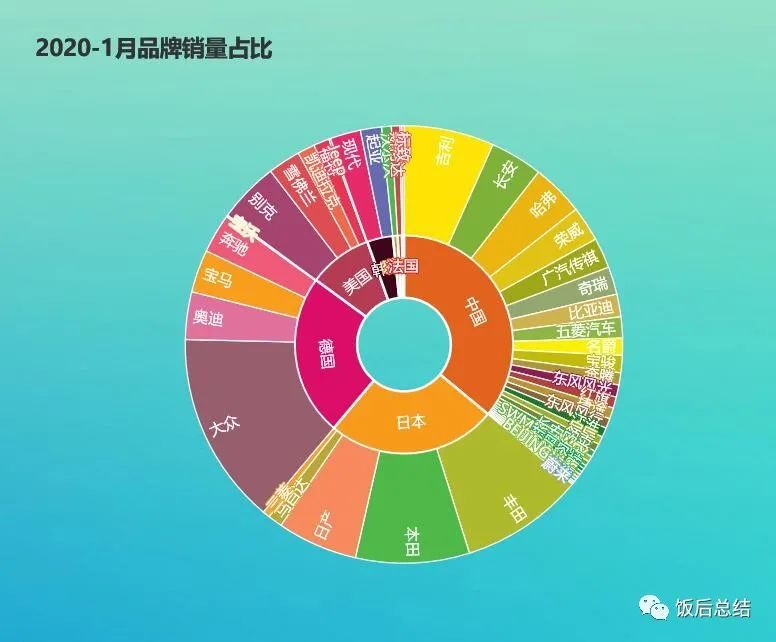
以下是饼状图,显示数据占比情况: from pyecharts import options as optsfrom pyecharts.charts import Piefrom pyecharts.faker import Fakerimport xlrddata = xlrd.open_workbook(r'C:/Users/Admin/PycharmProjects/project1/suv-per-month/202006/202006.xlsx')# print(data)table = data.sheets()[0]print(table.nrows)print(table.ncols)months = []sells = []for i in range(2, table.nrows): a = table.row_values(i) month = a[0] months.append(month) sell = a[1] sells.append(sell)# print(months)# print(sells)c = ( Pie() .add( "", [list(z) for z in zip(months, sells)], radius=["40%", "70%"], center=["60%", "60%"], ) .set_global_opts( title_opts=opts.TitleOpts(title="SUV总销量品牌占比"), legend_opts=opts.LegendOpts(orient="vertical", pos_top="10%" , pos_left="2%"), ) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}", is_show=False)) .render("suv-per-month-chart-202006.html"))
HTML+CSS+JAVASCRIPT前端开发 以下是首页动态按钮控件所属的CSS(BUTTON.css)与设计框架代码,插入背景图片,调取“https://assets.pyecharts.org/assets/echarts.min.js”的支持文件。参考由pyecharts生成的.html文件,自定义图表属性,并对整体性进行设计。本项目由于存在调用熟练度不高问题,所以不将其他图表进行展示,需要参考项目可以直接使用pyecharts生成的.html文件。 *{ margin: 0; padding:0;}body{ display: flex; justify-content: center; align-content: center; min-height: 100vh;}.container{ width:1100px; display: flex; justify-content: space-around; flex-wrap: wrap;}.container a{ position: relative; padding: 15px 30px; text-decoration: none; margin: 20px; letter-spacing: 2px; color:#FFFFFF; transition: .5s;}.container a:nth-child(1){ background: linear-gradient(120deg,#03a9f4,#f441a5,#ffeb3b,#03a9f4); background-size: 200%;}.container a:nth-child(2){ background: linear-gradient(120deg,#03a9f4,#f441a5,#ffeb3b,#03a9f4); background-size: 200%;}.container a:nth-child(3){ background: linear-gradient(120deg,#03a9f4,#f441a5,#ffeb3b,#03a9f4); background-size: 200%;}.container a:nth-child(4){ background: linear-gradient(120deg,#03a9f4,#f441a5,#ffeb3b,#03a9f4); background-size: 200%;}.container a:nth-child(5){ background: linear-gradient(120deg,#03a9f4,#f441a5,#ffeb3b,#03a9f4); background-size: 200%;}.container a:hover{ background-position: right; transform:translateY(-5px);}.container a::after{ content:""; position: absolute; top:0; left: 0; width: 50%; height: 100%; background: rgba(255,255,255,.2);}.container a::before{ content: ""; position:absolute; bottom: 0; left:5%; width: 90%; height: 4px; border-radius: 50%; transform:scale(0); transition:.5s;}.container a:hover::before{ transform: scale(1); bottom:-15px;}<html><head><meta charset="utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no"><title>homepagetitle><style type="text/css"> {margin: auto;padding: 0;} body { background-image: url("pics/629055.jpg"); background-repeat: no-repeat; background-size: cover; font-size:14px; } h3{ font-size:40px; color:#41457C; text-align:center; padding-top:20px; font-weight:normal; }style><script type="text/javascript" src="https://assets.pyecharts.org/assets/echarts.min.js">script>head><link rel="stylesheet" href="css/BUTTON.css"> link><body> <div class="siteHeader" style="text-align: center; height: 190px"><h3><strong>汽车销量统计平台strong>h3> <div class="container"> <a href="per-month/sumsell.html"><strong>销售总量strong>a> <a href="per-month/car-per-month.html"><strong>轿车strong>a> <a href="per-month/suv-per-month.html"><strong>SUVstrong>a> <a href="per-month/mpv-per-month.html"><strong>MPVstrong>a> div> div> <div class="container" style="position: absolute;right:1250px;top:200px;width:200px"> <a href="per-month/brands/car-brands1.html"><strong>品牌占有率strong>a> div> <div class="container" style="position: absolute;left:1250px;top:200px;width: 222px"> <a href="per-month/brands/price-tag/5wzy.html"><strong>各价位预算推荐strong>a> div> <div class="container" style="position: absolute;top:200px"> <a href="login.html"><strong>登录strong>a> div> body>html>

以上即为实训项目简述,之后会记录一个集成度和美观度更高的非大数据处理项目,为恶意流量识别平台的设计项目,包含简单的数据处理步骤和思路。 |






















 7536
7536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









