






写在前面
前段时间在网上看到一道很有意思的面试题,里面涉及到String的很多知识,非常有意思。做过Java开发的小伙伴们应该都知道,在我们日常的编码工作中,用到最多的对象的非String莫属,也就是我们常说的”字符串“。首先先看下题目
String的基本特性
首先我们先对String的基本特性有一个简单的认识
String是被声明为final的,不可被继承
实现了Serializable,可以被序列化
实现了Comparable接口,可以比较大小
以上三个特性非常的简单,我这里就只是简单的罗列一下,不做过多的解释。
重点我要说以下三个特性
存储结构的变化
String在JDK8及以前内部定义了final char[] value用于存储字符串数据,JDK9之后(包含JDK9)时改为byte[] 这个是字符串在JDK8以后一个非常重大的改动,我们可以在String的源代码中很清楚的看到,那为什么要做这样的改动呢?jdk的官方文档给了很好的解释,我们一起来看一下:http://openjdk.java.net/jeps/254

不可变性
首先来看一段代码
@Testpublic void test1() throws Exception { // 字面量定义的方式,"abc"存储在字符串常量池中 String s1 = "abc"; String s2 = "abc"; // true System.out.println(s1 == s2); s1 = "hello"; // false System.out.println(s1 == s2); s1 += "def"; // false System.out.println(s1 == s2); s1 = s1.replace("a","m"); // false System.out.println(s1 == s2);}下面是上述代码中变量在内存中的变化

上述代码证明了字符串常量池中是不允许放相同的字符串的,如果出现两个相同的字符串赋给不同的变量,那么两个变量指向的地址值一定是相同的。
当对字符串重新赋值时,需要重新指定内存区域赋值,不能使用原有的value进行赋值
当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值
当调用String的replace()方法修改指定字符串或字符串时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值
字符串常量池
字符串常量池是一个固定大小的Hashtable,默认值大小长度是 1009。 如果放进字符串常量池的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长度太长后直接会造成的影响就是当调用String.intern()时性能大幅下降。 ( 当调用intern()时会立刻在字符串常量池中生成对应的字符串,并将生成的地址返回,后面会详细讲)。我们可以使用下面的JVM参数来设置StringTable的大小-XX:StringTableSize同时也可以使用下面来查看当前Java进程对应的StringTableSize的大小
jinfo -flag StringTableSize xx(进程号)JDK6:StringTable是固定的,长度为1009,所以如果常量池中字符串过多就会导致效率下降很快.StringTableSize大小设置没有要求
JDK7:StringTable的长度默认为60013,StringTableSize大小设置没有要求。
JDK8及以后:设置StringTable的长度有要求,最小值为1009
以上就是字符串的比较重要的特性~下面来看一看String的内存分配
String的内存分配
在日常开发中,我们声明字符串对象可以通过很多种方式,其中使用到字符串常量池的方式有下面两种
通过字面量的方式给字符串赋值,此时字符串值声明在字符串常量池中
String str = "abc";使用String提供的intern()方法
字符串常量池在不同的JDK版本中的位置是不一样的
JDK6及以前:字符串常量池存放在永久代中
JDK7:字符串常量池存放在Java堆中,并且所有的字符串都保存在堆中
JDK8:字符串常量池在Java堆中
那为什么字符串常量池的位置要进行调整呢?下面是官方给出的解答
https://www.oracle.com/java/technologies/javase/jdk7-relnotes.html#jdk7changes

从上面的解释中可以看出,官方并不想将字符串常量池放到永久代中,那原因是什么呢,我总结一下结论
永久代的空间默认较小,当使用频繁大量的使用字符串对象或者占用空间非常大的字符串对象时,会出现内存溢出的情况
方法区的Full GC频率较低且开销较大
针对上述两种情况,将字符串常量池放到堆空间中都可以较完美的解决。
字符串的拼接操作
在日常开发中,字符串的拼接是我们非常常见的一种对字符串的操作,下面我们就针对不同方式的字符串拼接所产生对象的内存分布做一下深入的分析常量与常量的拼接结果在常量池,编译器优化。下面是一段代码:
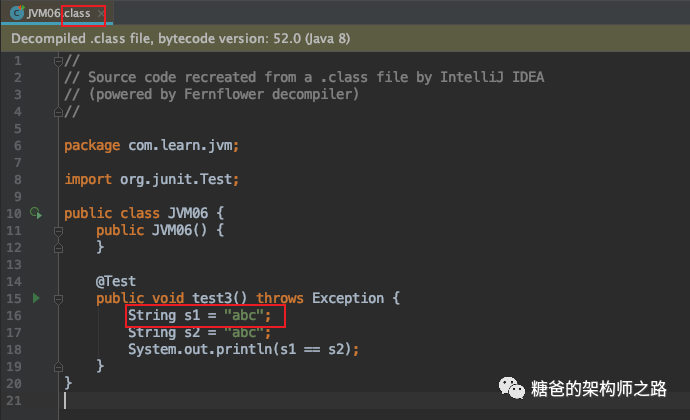
@Test public void test3() throws Exception { String s1 = "a" + "b" + "c"; String s2 = "abc"; // true System.out.println(s1 == s2); }我们将其编译为字节码文件后,再反编译成Java代码就会发现,s1在编译时期就已经被拼接成字符串“abc”了
拼接时只要有一个是变量,结果就在堆中.变量拼接的原理是StringBuilder
先看一段代码
@Testpublic void test4() throws Exception {String s1 = "a";String s2 = "b";String s3 = "ab";String s4 = s1 + s2;// false System.out.println(s3 == s4);}上面代码是两个变量在进行拼接操作,那么如何查看s1和s2在底层到底是如何拼接的呢?我们可以通过查看字节码的方式一探究竟。
查看字节码的方式可以通过命令行的方式将java文件编译成字节码
java -p xxx.java(Java文件)也可以通过工具,这里我用的是jclasslib,关于这个工具网上有很多介绍,idea也有集成它对应的插件,这里不做过多介绍,下面是编译之后的字节码,我们逐行的分析一下
// 1.将a、b、ab从字符串常量池中加载后存储到局部变量表中的s1、s2和s3变量中 0 ldc #5 2 astore_1 3 ldc #6 5 astore_2 6 ldc #7 8 astore_3// 2.构建StringBuilder并初始化(调用构造器方法) 9 new #8 12 dup13 invokespecial #9 >// 3.将s1和s2变量加载到操作数栈中,并调用StringBuilder的append方法进行拼接操作16 aload_117 invokevirtual #10 20 aload_221 invokevirtual #10 // 4.拼接完成后,调用StringBuilder的toString()方法24 invokevirtual #11 27 astore 429 getstatic #3 32 aload_333 aload 435 if_acmpne 42 (+7)38 iconst_139 goto 43 (+4)42 iconst_043 invokevirtual #4 46 return通过上述对字节码的分析,我们可以看到通过StringBuilder的拼接操作,我们最终会调用StringBuilder的toString()方法

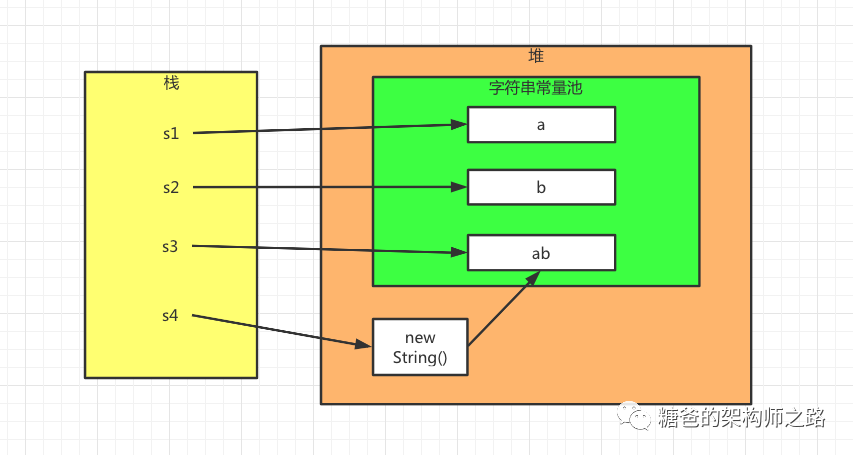
所以,代码String s4 = s1 + s2相当于在堆中新分配了内存空间,而并不是直接指向常量池中的“ab”。其内存分布图如下:
这里要特别注意一下,这里的变量不包括final修饰的变量,看下面代码
@Testpublic void test5() throws Exception { final String s1 = "a"; final String s2 = "b"; String s3 = "ab"; String s4 = s1 + s2; // true System.out.println(s3 == s4);}如果拼接符号左右两边都是字符串常量或常量引用(final),则仍然适用编译器优化,即非StringBuilder的方式
如果拼接结果调用intern()方法,则主动将常量池中还没有的字符串对象放入常量池中,并返回此对象的地址.
看下面代码
@Testpublic void test3() throws Exception { String s1 = "javaEE"; String s2 = "hadoop"; String s3 = "javaEEhadoop"; String s4 = "javaEE" + "hadoop"; String s5 = s1 + "hadoop"; String s6 = "javaEE" + s2; String s7 = s1 + s2; // 如果拼接符号的前后出现了变量,则相当于在堆空间中new String() // true,编译器优化 System.out.println(s3 == s4); // false System.out.println(s3 == s5); // false System.out.println(s3 == s6); // false System.out.println(s5 == s6); // false System.out.println(s5 == s7); // false System.out.println(s6 == s7); String s8 = s6.intern(); // true -> 常量池中已存在javaEEhadoop,直接返回地址 System.out.println(s3 == s8);}@Testpublic void test6() throws Exception { String src = ""; for (int i = 0; i < 100000; i++) { // 每次循环都会创建一个Stringbuilder和String src = src + "a"; }}@Testpublic void test7() throws Exception { // 只需要创建一个StringBuilder StringBuilder src = new StringBuilder(); for (int i = 0; i < 100000; i++) { src.append("a"); }}上述代码是使用了两种方式拼接字符串,通过计算方法的执行时间,可以看出StringBuilder拼接所花费的时间要远远小于通过“+”拼接字符串的时间。为什么会这样呢?
StringBuilder的append()方法始终只创建过一个StringBuilder对象。使用String的字符串拼接方式每次循环都会创建一个StringBuilder和String对象,操作繁琐
使用String的字符串拼接方式每次循环都会创建一个StringBuilder和String对象,内存占用空间大,如果进行GC,需要花费额外的时间。
另外,在进行拼接操作时,可以在初始化StringBuilder就指定char数组的长度,避免在拼接过程中频繁的扩容导致的内存开销。
关于intern()
intern()方法是String中的一个本地方法,我们先看一下官方对这个方法的解释

上述红色框中的内容是官方给出的intern()方法的定义。在这里我做一下说明:
当intern()方法被调用后, 如果常量池中已经包含了一个与当前字符串相等(equal to)的字符串,则直接将常量池中的字符串返回,不会再重新创建。否则,这个字符串对象将被添加到常量池中并且将添加后的对象的引用地址返回。 对于任意两个字符串来说,当且仅当equal方法返回true时,s.intern() == t.intern() 返回true。 通过上面官方给的描述,我们可以得出结: 如果在任意字符串上调用String.intern()方法,那么其返回结果所指向的那个类实例,必须和直接以常量形式出现的字符串实例完全相同。即下面的代码一定返回true("a" + "b" + "c").intern() == "abc"String s1 = "abc";String s2 = new String("abc").intern();String s3 = new StringBuilder("abc").toString().intern();System.out.println(s1 == s2);System.out.println(s1 == s3);System.out.println(s2 == s3);new String("ab")会创建几个对象
先看代码
public static void main(String[] args) { String s1 = new String("ab"); }以上代码中,当执行new String()方法时,会创建几个对象?想要搞清楚这个问题,我们可以通过查看字节码的方式:
// new关键字在堆空间中创建String对象 0 new #2 3 dup // 加载常量池中的“abc”字符串 4 ldc #3 // 调用构造方法 6 invokespecial #4 > // 存放到局部变量表的s1变量中 9 astore_110 return上面的字节码可以看出,当调用new String("abc")时,会创建两个对象,分别是通过new String()在堆中创建的字符串对象和在字符串常量池中创建的“abc”。
new String("a") + new String("b")public static void main(String[] args) { String s2 = new String("a") + new String("b");}对于这个问题,我们依然可以通过查看字节码的方式:
// 创建StringBuilder对象 0 new #2 3 dup // 初始化StringBuilder 4 invokespecial #3 > // new String("a") 7 new #4 10 dup// 从常量池中加载“a”11 ldc #5 // 调用String构造器进行初始化13 invokespecial #6 >// 调用拼接方法16 invokevirtual #7 // new String("b")19 new #4 22 dup23 ldc #8 25 invokespecial #6 >28 invokevirtual #7 // 调用StringBuilder的to String()方法.31 invokevirtual #9 34 astore_135 return之前提到在StringBuilder的toString方法中,会通过new String()的方式构建一个新的字符串,下面我们来看一下toString()方法的字节码执行指令
// 创建String对象 0 new #80 3 dup 4 aload_0 5 getfield #234 8 iconst_0 9 aload_010 getfield #233 13 invokespecial #291 >16 areturn通过上面的字节码执行指令,我们可以得出一个结论。即在上述toString()调用,在字符串常量池中,是没有生成"ab"的
我们来总结一下上面两个小节
new String("ab")
字符串对象
字符串常量池-> "ab"
new String("a") + new String("b")
字符串a对象
字符串常量“a”
字符串b对象
字符串常量“b”
StringBuilder对象
StringBuilder对象中调用的toString()方法时创建的字符串对象
关于面试题的解析
有了上面的知识储备,我们再回头看开篇的题目。就会显得从容很多,首先我公布下答案
public static void main(String[] args) { String s = new String("a"); s.intern(); String s2 = "a"; System.out.println(s == s2); String s3 = new String("a") + new String("b"); s3.intern(); String s4 = "ab"; System.out.println(s3 == s4); }第一个打印:
false
第二个打印:
JDK6:false
JDK7及以后:true
下面我们来详细分析一下
通过上面的介绍,我们已经知道了new String(“ab”),其中s变量指向的应该是在堆空间中创建的字符串对象,并不是直接指向到常量池中的“a”,所以s和s2指向的地址是不一致的,答案自然是false。
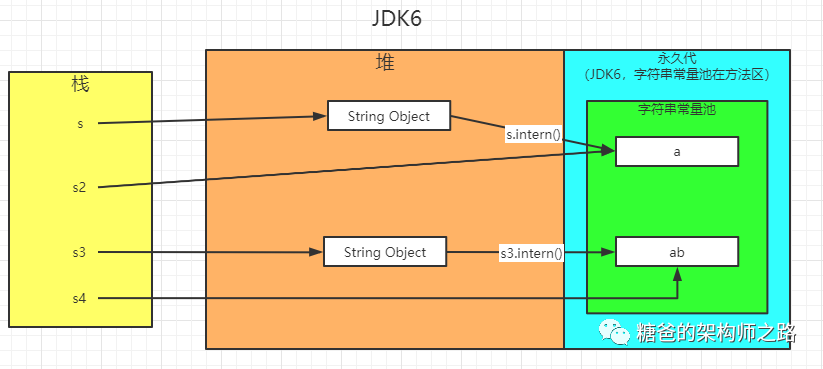
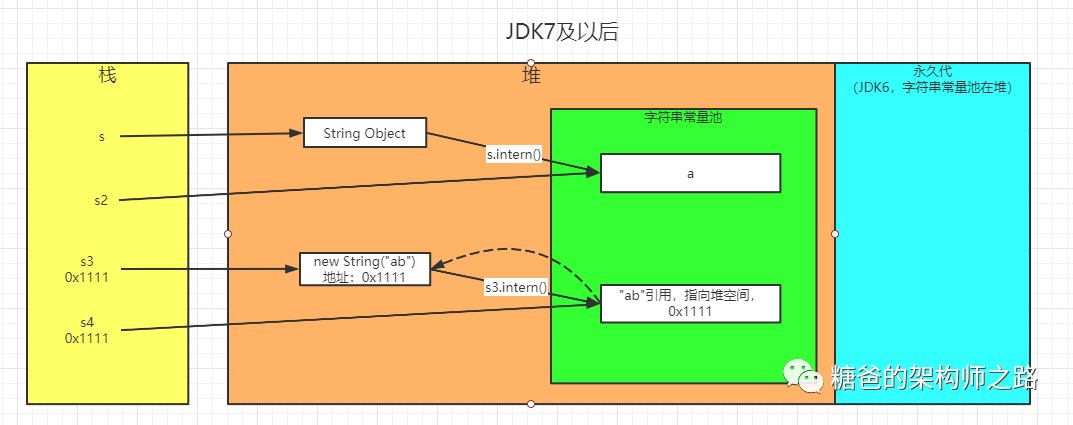
那么第二个打印为什么根据JDK版本的不同得出不同的答案呢?首先我们根据上面的知识可以得出s3指向的是StringBuilder.toString()之后在堆中创建的字符串对象的地址,但此时字符串常量池中是没有“ab”对象的,之后s3.intern()方法执行后,便会在字符串常量池中创建一个字符串“ab”,并将“ab”的地址返回。关键点就在这里,在JDK6时,调用intern()方法,不管堆空间是否存在new String("ab"),都会在常量池中创建一个新的对象,因此也就有一个新的地址。但在JDK7之后(包含JDK7),当堆空间存在new String("ab")时,为了优化内存空间,当调用intern()方法时,并不会在常量池创建一个新的"ab"对象,而是创建一个指向堆空间new String("ab")的引用。所以在JDK7及以后,s3和s4变量指向的其实都是new String("ab")在堆空间分配的内存区域,所以当s3和s4的内存地址是相同的。下面是不同版本下s1、s2、s3、s4的内存分布图
public static void main(String[] args) { String x = "ab"; String s = new String("a") + new String("b"); String s2 = s.intern(); System.out.println(s2 == x); System.out.println(s == x); }上述代码,无论使用JDK的哪个版本,打印都为true和false,这是什么原因呢?难道不符合上面我们说过的内容么?答案是否定的。这里第二个打印都为false的原因是因为“ab”字符串被首先声明出来了,并且在执行intern()方法前就“ab”就已经存在,所以不会再次创建。也就不会出现JDK7之后的内存优化导致的引用地址的问题了。
以上我们可以看出,intern()方法起到了非常重要的作用,所以我们来总结一下:在JDK1.6中,将这个字符串对象尝试放入字符串常量池中
如果常量池中有,则不会放入,返回已有的字符串常量吃中的对象的地址
如果没有,会把此对象复制一份,放入字符串常量池中,并返回字符串常量池中的对象地址
JDK1.7及以后,将这个字符串对象尝试放入字符串常量池中
如果字符串常量池汇总有,则并不会放入,返回已有的字符串常量池中的对象的地址
如果没有,则会把对象的引用地址复制一份,放入字符串常量值中,并返回字符串常量池中的引用地址
public class JVM14 { static final int MAX_COUNT = 1000 * 10000; static final String arr[] = new String[MAX_COUNT]; public static void main(String[] args) { Integer[] data = new Integer[]{1,2,3,4,5,6,7,8,9,10}; long start = System.currentTimeMillis(); for (int i = 0; i // arr[i] = new String(String.valueOf(data[i % data.length])); // arr[i] = new String(String.valueOf(data[i % data.length])).intern(); } long end = System.currentTimeMillis(); System.out.println("花费的时间为:" + (end - start)); try { Thread.sleep(1000000); } catch (InterruptedException e) { e.printStackTrace(); } System.gc(); }}arr[i] = new String(String.valueOf(data[i % data.length]));
arr[i] = new String(String.valueOf(data[i % data.length])).intern();
首先我们使用内存监控工具JProfiler分别看一下内存的使用情况
未调用intern()方法,话费时间为4948.

调用intern()方法,话费时间为816.

显然第一种方式更耗时并且占用更多的内存空间。为什么会出现这样的现象呢?
当执行第一种方法构建字符串时,常量池中时没有分配常量的,每执行一次循环,堆空间中就创建一个字符串对象,并且被数组中的一个元素引用。因此,循环1千万次后,堆空间中就会有1kw个字符串对象存在,并且在GC时因为被GC Roots引用(这里的GC Roots是arr[] ),所以无法被垃圾回收。导致内存膨胀。 当执行第二种方法构建字符串时,由于调用了intern(),常量池中会分配对应的字符串对象,此时数组指向的地址即为字符串常量中的地址,所以虽然每次执行循环也会在堆中创建字符串对象,但是因为调用了intern()方法,堆空间中的字符串对象最终没有被引用,当堆空间占用达到一定的比例时,GC会回收掉不再被使用的字符串对象,所以释放了大量的空间,也就看到了我们最终的结果。最后,我们也可以通过JVM参数来验证我们的观点。使用下面的命令可以查看JVM中字符串常量池中对象的统计数据
-XX:+PrintStringTableStatisticspublic class JVM14 { static final int MAX_COUNT = 1000 * 10000; static final String arr[] = new String[MAX_COUNT]; public static void main(String[] args) { Integer[] data = new Integer[]{1,2,3,4,5,6,7,8,9,10}; long start = System.currentTimeMillis(); for (int i = 0; i // arr[i] = new String(String.valueOf(data[i % data.length])); // arr[i] = new String(String.valueOf(data[i % data.length])).intern(); } }}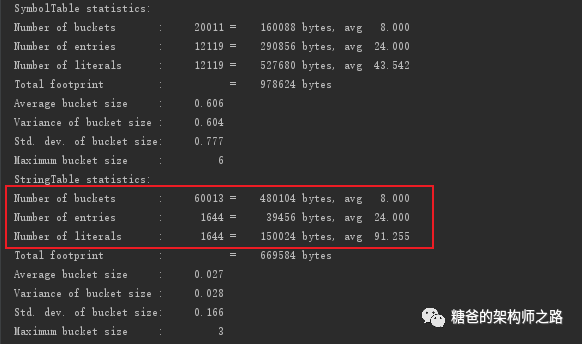



















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









