






本文作者:热心群众
[回顾]本栏目还有如下几篇文章的质疑没有得到正面回应:
1.[质疑][ECCV2016] 突(秃)发!很秃然,消失的头发
Deep Automatic Portrait Matting (ECCV2016 spotlight)
作者:Xiaoyong Shen (沈小勇), Xin Tao, Hongyun Gao, Chao Zhou, Jiaya Jia(贾佳亚)
主要单位:香港中文大学
2.[质疑][CVPR2019]Σ(⊙▽⊙竟然还有续集!
Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration(CVPR2019 Oral)
作者:Yang He(何洋), Ping Liu, Ziwei Wang, Zhilan Hu, Yi Yang (杨毅)
主要单位:悉尼科技大学
3.[质疑][CVPR2020]只有强者才能“抠”脚
Attention-Guided Hierarchical Structure Aggregation for Image Matting (CVPR2020 poster)
作者:Yu Qiao (乔羽),Yuhao Liu (刘宇豪),Xin Yang (杨鑫), Dongsheng Zhou, Mingliang Xu, Qiang Zhang, Xiaopeng Wei (魏小鹏)
主要单位:大连理工大学
另外为更好提升本栏目质量,如果对本栏目有建议,烦请移步:
如何更好地公开质疑AI论文?www.zhihu.comHybridPose: 6D Object Pose Estimation under Hybrid Representations
Chen Song(宋晨), Jiaru Song, Qixing Huang(黄其兴)
[paper][code]
作者单位均来自:
得克萨斯大学奥斯汀分校(The University of Texas at Austin)

上面引用 @Yulong 大佬写的的一段典故(引经据典)正所谓:数据千万条,划分第一条,测试不规范,模型两行泪。本次要质疑的这篇论文,问题就出在了数据集划分的环节上。
关于6D Object Pose Estimation的简要介绍可以移步:[link]
本文工作是基于CVPR2019的PVNet的基础上提出的一种基于预测多种表示的6D姿态估计方法,文中宣称在Occlusion Linemod数据集上达到了79.2%的ADD(-S)准确率,远远超过了当前最好的方法:

一般来说,如果有这么夸张的提升,要么是文章存在问题,要么是有革命性的进展。如果是革命性进展,那么必然是极好的。那么首先来确定一些细节——
数据集的划分

已开源的代码也石锤了这个操作:
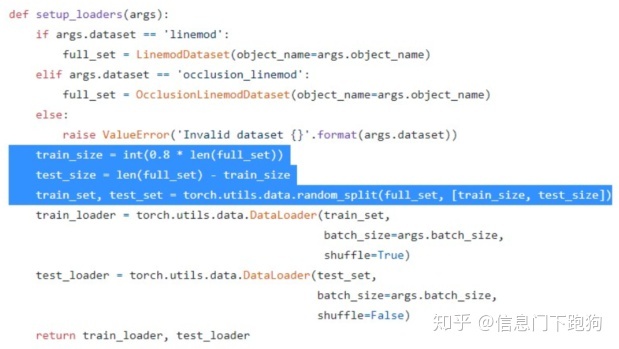
一般来说在这个数据集的baseline方法全是在每个物体的 15%的真实数据训练(可能加合成数据),在剩下85%的真实数据上进行测试,而且基本都是用的 BB8(ICCV’17)那篇文章中产生的 split,是一致的,并且 baseline 方法中关于实验部分有明确提及这一划分。但是这篇文章却变成了随机划分 80%训练,20%测试。
关键词:
baseline: 15%用来训练,85%用来测试
本文:80%用来训练,20%用来测试
在 Occlusion Linemod 上,这篇文章的划分也存在问题。Occlusion Linemod 因为和 Linemod 的物体是一样的,所以整个 Occlusion Linemod 就是测试集,文中比较的 baseline 方法都是在Linemod 上训练(可能加合成数据),在整个 Occlusion Linemod 上进行测试。注意在这里Occlusion Linemod 其实是 Linemod 的一个序列,为有遮挡的物体提供了可以测试的标注,但是这个序列是不会参与训练的。然而,这篇文章里却变成了在测试集上随机划分 80%训练,在剩下 20%测试。这么一看,文中宣称的惊为天人的提升就很容易解释了,比baseline多用了一部分测试集做训练,而少了一部分测试集做测试”,这对比实验因此也是毫无意义的,不公平的对比,宣称提升再多也是不可信的。
实际上不仅仅是我们注意到这个问题,在github上也有其他人发现了这个问题。同时作者Chen Song在github已经承认了自己划分数据集时的错误操作,表示会重新做实验。需要赞一个的是作者Chen Song在github上的态度是非常诚恳,值得赞扬的。
具体可以参考如下issue:https://github.com/chensong1995/HybridPose/issues/31https://github.com/chensong1995/HybridPose/issues/32

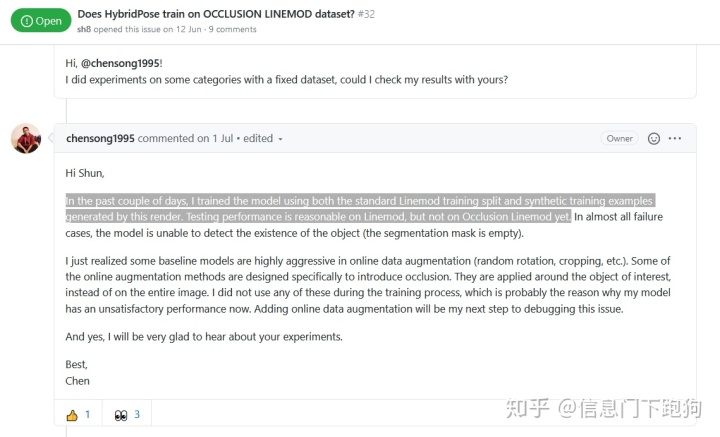
注意到上图中,距离作者在github上的回应已经过去整整一个月了,请问您说好的重新实验做得咋样呐?
由于该文存在严重对比不公平的问题,我建议从CVPR2020中撤稿——
这里插几句——
这篇工作是follow PVNet的,然而本文作者黄其兴老师本身就是PVNet的作者。这项“自己”follow “自己”的工作为什么也会在划分数据集这样基本的问题上出现重大错误呢?提升那么夸张难道不自己review一下是不是哪里出现问题呢?
顺便一提的是,今天是VALSE 2020的开幕,黄其兴老师也讲了这篇文章:
[video] 坐标:100:52

—————————倡议——————————
再次呼吁一下大家投稿~如果要提供信息,务必在保护自身信息安全的情况下提供信息!投稿方式私信和邮件runningdog_ai@126.com均可,再次感谢大家对AI社区的热爱。
太阳快落下去了,你们的孩子居然不害怕? “当然不害怕,她知道明天太阳还会升起来的。”——三体·黑暗森林














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









