






0x00 前言
之前我们介绍了简单线性回归,其输入特征只有一维,即:;推广到多维特征,即多元线性回归:。
但是在线性回归的背后是有一个很强的假设条件:数据存在线性关系。但是更多的数据之间具有非线性关系。因此对线性回归法进行改进,使用多项式回归法,可以对非线性数据进行处理。
0x01 什么是多项式回归
研究一个因变量与一个或多个自变量间多项式的回归分析方法,称为多项式回归(Polynomial Regression)。多项式回归是线性回归模型的一种,其回归函数关于回归系数是线性的。其中自变量x和因变量y之间的关系被建模为n次多项式。
如果自变量只有一个时,称为一元多项式回归;如果自变量有多个时,称为多元多项式回归。在一元回归分析中,如果变量y与自变量x的关系为非线性的,但是又找不到适当的函数曲线来拟合,则可以采用一元多项式回归。
由于任一函数都可以用多项式逼近,因此多项式回归有着广泛应用。
下面举个例子:
对于下面这种非线性关系的数据,使用直线拟合会显得很牵强。
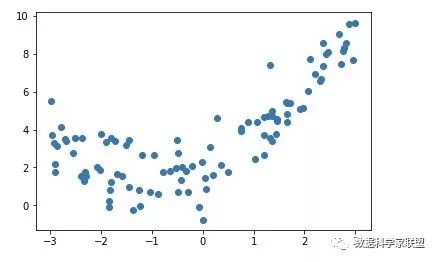
画一个曲线,拟合度更好。
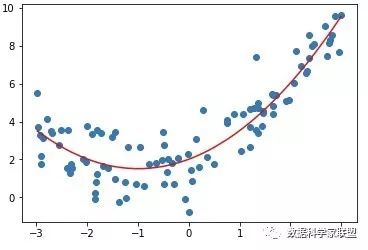
如果只有一个特征,则可以写出表达式:。
0x02 多项式回归实现思路
首先来准备一下数据,创建一个一元二次方程,并增加一些噪音:
import numpy as npimport matplotlib.pyplot as pltx = np.random.uniform(-3, 3, size=100)X = x.reshape(-1, 1)y = 0.5 + x**2 + x + 2 + np.random.normal(0, 1, size=100)plt.scatter(x, y)plt.show()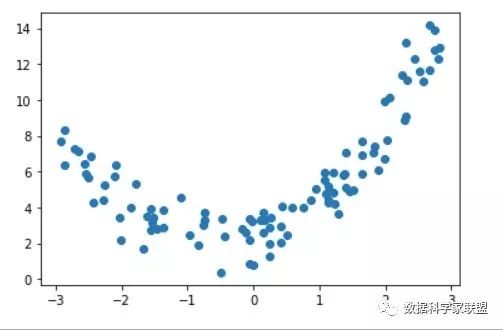
如果直接使用线性回归去拟合数据,则可以得到:
from sklearn.linear_model import LinearRegressionlin_reg = LinearRegression()lin_reg.fit(X, y)y_predict = lin_reg.predict(X)plt.scatter(x, y)plt.plot(x, y_predict, color='r')plt.show()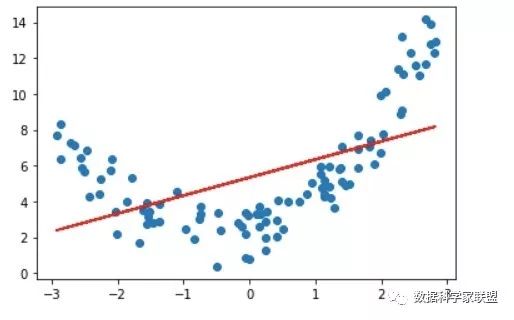
很显然,拟合效果并不好。那么解决呢?
多项式回归的思路是:添加一个特征,即对于X中的每个数据进行平方。
# 创建一个新的特征(X**2).shape# 凭借一个新的数据数据集X2 = np.hstack([X, X**2])# 用新的数据集进行线性回归训练lin_reg2 = LinearRegression()lin_reg2.fit(X2, y)y_predict2 = lin_reg2.predict(X2)plt.scatter(x, y)plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')plt.show()
其第一个系数是前的系数,第二个系数是前面的。输出其截距。
lin_reg2.coef_# 输出:array([0.90802935, 1.04112467])lin_reg2.intercept_# 输出:2.37835600837686020x03 sklearn中的多项式回归
3.1 一元多项式回归
对于上一小节生成的虚拟数据,使用sklearn中的多项式回归。多项式回归可以看作是对数据进行预处理,给数据添加新的特征,所以调用的库在preprocessing中:
from sklearn.preprocessing import PolynomialFeatures# 这个degree表示我们使用多少次幂的多项式poly = PolynomialFeatures(degree=2) poly.fit(X)X2 = poly.transform(X)X2.shape# 输出:(100, 3)# 查看数据X2[:5,:]
X2的结果第一列常数项,可以看作是加入了一列x的0次方;第二列一次项系数(原来的样本X特征),第三列二次项系数(X平方前的特征)。
特征准备好之后进行训练:
from sklearn.linear_model import LinearRegressionreg = LinearRegression()reg.fit(X2, y)y_predict = reg.predict(X2)plt.scatter(x, y)plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')plt.show()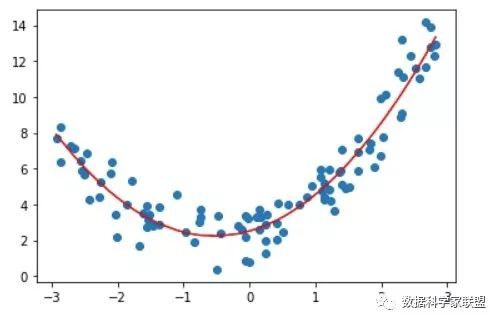
得到的系数和截距与上一小节中的结果是相同的:
reg.coef_# array([0. , 0.90802935, 1.04112467])reg.intercept_# 2.37835600837686163.2 多元多项式回归
之前使用的都是1维数据,如果使用2维3维甚至更高维呢?
import numpy as npX = np.arange(1, 11).reshape(5, 2)# 5行2列 10个元素的矩阵X.shapefrom sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures()poly.fit(X)# 将X转换成最多包含X二次幂的数据集X2 = poly.transform(x)# 5行6列X2.shapeX2# 输出:array([[ 1., 1., 2., 1., 2., 4.], [ 1., 3., 4., 9., 12., 16.], [ 1., 5., 6., 25., 30., 36.], [ 1., 7., 8., 49., 56., 64.], [ 1., 9., 10., 81., 90., 100.]])可以看出当数据维度是2维的,经过多项式预处理生成了6维数据。
第一列很显然是0次项系数;第二列和第三列就是原本的X矩阵;第四列是第二列(原X的第一列)平方的结果;第五列是第二、三两列相乘的结果;第六列是第三列(原X的第二列)平方的结果。
由此可以猜想一下如果数据是3维的时候是什么情况:
poly = PolynomialFeatures(degree=3)poly.fit(x)x3 = poly.transform(x)x3.shape# (5, 10)array([[ 1., 1., 2., 1., 2., 4., 1., 2., 4., 8.], [ 1., 3., 4., 9., 12., 16., 27., 36., 48., 64.], [ 1., 5., 6., 25., 30., 36., 125., 150., 180., 216.], [ 1., 7., 8., 49., 56., 64., 343., 392., 448., 512.], [ 1., 9., 10., 81., 90., 100., 729., 810., 900., 1000.]])过PolynomiaFeatures,将所有的可能组合,升维的方式呈指数型增长。这也会带来一定的问题。
0x04 Pipeline
在具体编程实践时,可以使用sklearn中的pipeline对操作进行整合。
首先我们回顾多项式回归的过程:
- 将原始数据通过
PolynomialFeatures生成相应的多项式特征 - 多项式数据可能还要进行特征归一化处理
- 将数据送给线性回归
Pipeline就是将这些步骤都放在一起。参数传入一个列表,列表中的每个元素是管道中的一个步骤。每个元素是一个元组,元组的第一个元素是名字(字符串),第二个元素是实例化。
from sklearn.pipeline import Pipelinefrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import StandardScalerpoly_reg = Pipeline([ ('poly', PolynomialFeatures(degree=2)), ('std_scale', StandardScaler()), ('lin_reg', LinearRegression())]) poly_reg.fit(X, y)y_predict = poly_reg.predict(X)plt.scatter(x, y)plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')plt.show()0xFF 小结
其实多项式回归在算法并没有什么新的地方,完全是使用线性回归的思路,关键在于为数据添加新的特征,而这些新的特征是原有的特征的多项式组合,采用这样的方式就能解决非线性问题。
这样的思路跟PCA这种降维思想刚好相反,而多项式回归则是升维,添加了新的特征之后,使得更好地拟合高维数据。
浅析多项式回归与sklearn中的Pipeline
0x00 前言
之前我们介绍了简单线性回归,其输入特征只有一维,即:;推广到多维特征,即多元线性回归:。
但是在线性回归的背后是有一个很强的假设条件:数据存在线性关系。但是更多的数据之间具有非线性关系。因此对线性回归法进行改进,使用多项式回归法,可以对非线性数据进行处理。
0x01 什么是多项式回归
研究一个因变量与一个或多个自变量间多项式的回归分析方法,称为多项式回归(Polynomial Regression)。多项式回归是线性回归模型的一种,其回归函数关于回归系数是线性的。其中自变量x和因变量y之间的关系被建模为n次多项式。
如果自变量只有一个时,称为一元多项式回归;如果自变量有多个时,称为多元多项式回归。在一元回归分析中,如果因变量y与自变量x的关系为非线性的,但是又找不到适当的函数曲线来拟合,则可以采用一元多项式回归。
由于任一函数都可以用多项式逼近,因此多项式回归有着广泛应用。
下面举个例子:
对于下面这种非线性关系的数据,使用直线拟合会显得很牵强。
画一个曲线,拟合度更好。
如果只有一个特征,则可以写出表达式:。
0x02 多项式回归实现思路
首先来准备一下数据,创建一个一元二次方程,并增加一些噪音:
import numpy as npimport matplotlib.pyplot as pltx = np.random.uniform(-3, 3, size=100)X = x.reshape(-1, 1)y = 0.5 + x**2 + x + 2 + np.random.normal(0, 1, size=100)plt.scatter(x, y)plt.show()如果直接使用线性回归去拟合数据,则可以得到:
from sklearn.linear_model import LinearRegressionlin_reg = LinearRegression()lin_reg.fit(X, y)y_predict = lin_reg.predict(X)plt.scatter(x, y)plt.plot(x, y_predict, color='r')plt.show()很显然,拟合效果并不好。那么解决呢?
多项式回归的思路是:添加一个特征,即对于X中的每个数据进行平方。
# 创建一个新的特征(X**2).shape# 凭借一个新的数据数据集X2 = np.hstack([X, X**2])# 用新的数据集进行线性回归训练lin_reg2 = LinearRegression()lin_reg2.fit(X2, y)y_predict2 = lin_reg2.predict(X2)plt.scatter(x, y)plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')plt.show()其第一个系数是前的系数,第二个系数是前面的。输出其截距。
lin_reg2.coef_# 输出:array([0.90802935, 1.04112467])lin_reg2.intercept_# 输出:2.37835600837686020x03 sklearn中的多项式回归
3.1 一元多项式回归
对于上一小节生成的虚拟数据,使用sklearn中的多项式回归。多项式回归可以看作是对数据进行预处理,给数据添加新的特征,所以调用的库在preprocessing中:
from sklearn.preprocessing import PolynomialFeatures# 这个degree表示我们使用多少次幂的多项式poly = PolynomialFeatures(degree=2) poly.fit(X)X2 = poly.transform(X)X2.shape# 输出:(100, 3)# 查看数据X2[:5,:]X2的结果第一列常数项,可以看作是加入了一列x的0次方;第二列一次项系数(原来的样本X特征),第三列二次项系数(X平方前的特征)。
特征准备好之后进行训练:
from sklearn.linear_model import LinearRegressionreg = LinearRegression()reg.fit(X2, y)y_predict = reg.predict(X2)plt.scatter(x, y)plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')plt.show()得到的系数和截距与上一小节中的结果是相同的:
reg.coef_# array([0. , 0.90802935, 1.04112467])reg.intercept_# 2.37835600837686163.2 多元多项式回归
之前使用的都是1维数据,如果使用2维3维甚至更高维呢?
import numpy as npX = np.arange(1, 11).reshape(5, 2)# 5行2列 10个元素的矩阵X.shapefrom sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures()poly.fit(X)# 将X转换成最多包含X二次幂的数据集X2 = poly.transform(x)# 5行6列X2.shapeX2# 输出:array([[ 1., 1., 2., 1., 2., 4.], [ 1., 3., 4., 9., 12., 16.], [ 1., 5., 6., 25., 30., 36.], [ 1., 7., 8., 49., 56., 64.], [ 1., 9., 10., 81., 90., 100.]])可以看出当数据维度是2维的,经过多项式预处理生成了6维数据。
第一列很显然是0次项系数;第二列和第三列就是原本的X矩阵;第四列是第二列(原X的第一列)平方的结果;第五列是第二、三两列相乘的结果;第六列是第三列(原X的第二列)平方的结果。
由此可以猜想一下如果数据是3维的时候是什么情况:
poly = PolynomialFeatures(degree=3)poly.fit(x)x3 = poly.transform(x)x3.shape# (5, 10)array([[ 1., 1., 2., 1., 2., 4., 1., 2., 4., 8.], [ 1., 3., 4., 9., 12., 16., 27., 36., 48., 64.], [ 1., 5., 6., 25., 30., 36., 125., 150., 180., 216.], [ 1., 7., 8., 49., 56., 64., 343., 392., 448., 512.], [ 1., 9., 10., 81., 90., 100., 729., 810., 900., 1000.]])过PolynomiaFeatures,将所有的可能组合,升维的方式呈指数型增长。这也会带来一定的问题。
0x04 Pipeline
在具体编程实践时,可以使用sklearn中的pipeline对操作进行整合。
首先我们回顾多项式回归的过程:
- 将原始数据通过
PolynomialFeatures生成相应的多项式特征 - 多项式数据可能还要进行特征归一化处理
- 将数据送给线性回归
Pipeline就是将这些步骤都放在一起。参数传入一个列表,列表中的每个元素是管道中的一个步骤。每个元素是一个元组,元组的第一个元素是名字(字符串),第二个元素是实例化。
from sklearn.pipeline import Pipelinefrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import StandardScalerpoly_reg = Pipeline([ ('poly', PolynomialFeatures(degree=2)), ('std_scale', StandardScaler()), ('lin_reg', LinearRegression())]) poly_reg.fit(X, y)y_predict = poly_reg.predict(X)plt.scatter(x, y)plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')plt.show()0xFF 小结
其实多项式回归在算法并没有什么新的地方,完全是使用线性回归的思路,关键在于为数据添加新的特征,而这些新的特征是原有的特征的多项式组合,采用这样的方式就能解决非线性问题。
这样的思路跟PCA这种降维思想刚好相反,而多项式回归则是升维,添加了新的特征之后,使得更好地拟合高维数据。














 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









