





EM算法学习(三)
在前两篇文章中,我们已经大致的讲述了关于EM算法的一些基本理论和一些基本的性质,以及针对EM算法的缺点进行的优化改进的新型EM算法,研究之后大致就能够进行初步的了解.现在在这最后一篇文章,我想对EM算法的应用进行一些描述:
EM算法在多元正态分布缺失的数据下一般都是有较为广泛的应用,所以在这样典型的应用情境下,我将主要研究EM算法在二元正态分布下的应用.
1:二元正态分布的介绍:
设二维的随机变量(X,Y)的概率密度为:
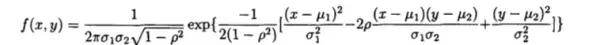
其中u1,u2,p,&1,&2都是常数,并且&1>0,%2>0,-1
因为接下来的推导需要几个性质,现在先给出几个重要的性质:
性质1:二元正态分布的边际分布
证:
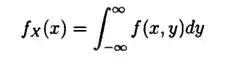
由于
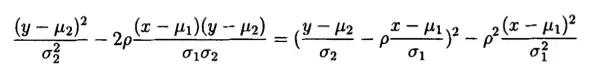
于是得到:
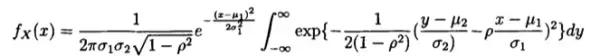
在这里设一个参数t:
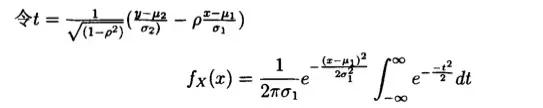
即可以得到:
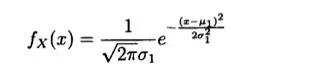
同理:
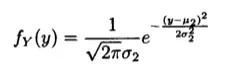
哼,证明证明出来了
性质2:正态分布的条件分布仍是正态分布
二元正态分布(X,Y) ~N(u,M),其中:
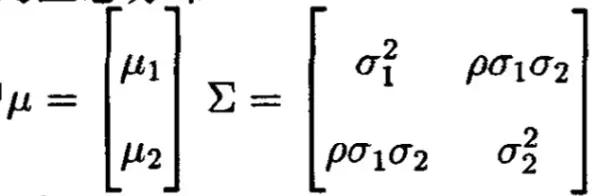
求证:
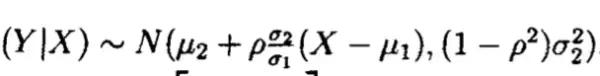
证明过程如下:

2:对于二元正态分布均值的MCEM估计:
设总体Z=(X,Y)~N(u,M),其中:
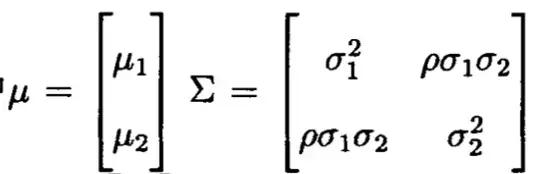
现在有如下的观测数据:
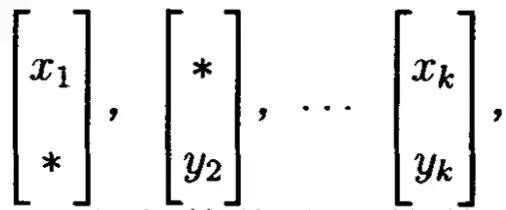
显然这个数据是缺失的,如果数据完整的话,那么这个参数估计起来很简单,用极大似然估计就OK,但是这样的数据不完整的情况下,用极大似然估计求参数是非常困难的,现在我们知道EM算法对于缺失数据是非常有利的,现在我们用EM算法来求:
假设协方差矩阵
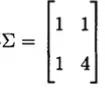
估计未知参数:

首先以u=[2,4]为例产生二元正态分布随机数,并将产生的随机数扣掉一部分数据,将扣掉的这一部分数据当成未知的缺失数据M=[M1,M2],剩下的数据作为观测数据Z=[X,Y]
假设在第K+1次迭代中有u的估计值u(k)=[u1(k),u2(k)],在上边的性质中,可以应用得到:
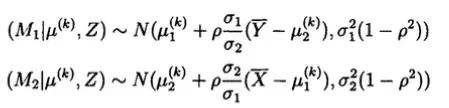
然后按照上边的条件分布生成n个随机数:
M1=(m1(1),m1(2),……..m1(n))
M2=(m2(1),m2(2)…….m2(n))
计算E步,得出Q函数:

这样M1与观察数据构成完全数据(M1(K),X),在M步中,对于函数Q的未知参数u1求导进行极大似然估计,想当是对在完全数据下的u1求极大似然估计,即:
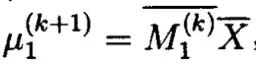
这里的M1表示在完全数据下的均值,u2的估计值求法与此相似.
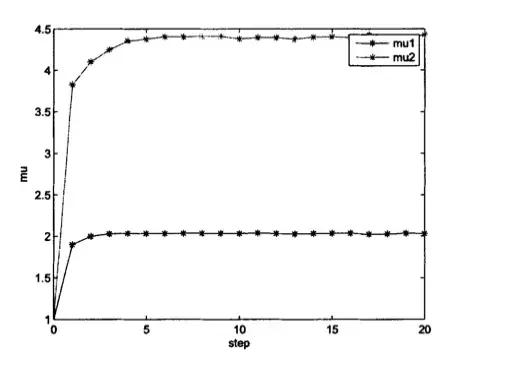
有兴趣的同学可以用MATLAB这样的工具试一试,实验室的小伙伴试验后表示在u1,u2初始值都为1,迭代20次以后,最终都会收敛,u1=2.0016,u2=3,9580
3:高斯混合分布的定义;
混合模型是指随机变量X的概率密度函数为下式:
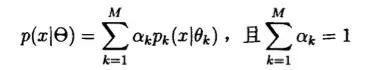
这个式子表现的是这个混合模型有M个分支组成,每个分支的权值为ak,当每个分支的分布都是高斯分布时,则称混合分布为有M个分支的高斯混合分布(GMM)
现在进行假设:
设样本观测值为X={x1,x2,,,,,xN},由上边的式子的到,高斯分布混合分布的对数似然函数可以写成:
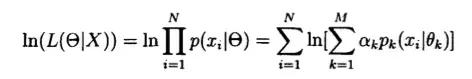
我们现在进行简化:
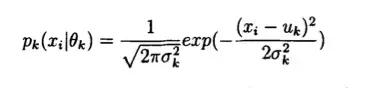
把上式中的累加求和去掉,,如果直接对对数似然函数求导来寻求极值是不可行的。但是如果我们知道每一个观测值甄具体是来自M个分支的哪一个分支的,则问题的难度就会下降很多。因此,从这个想法出发,我们引进隐含变 量y,它是这么定义的:设Y={y1,y2,,,,yN}且y(i)∈{1,2,…,M},i= 1,2,…,N。则当y(i)=k时,表示第i个样本观测值x(i)是由高斯混合分布的第k个分支产生的。因此,引入变量y后,对数似然函数可以改写成为:
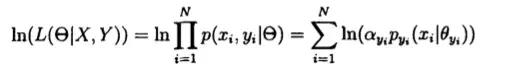
改写似然函数之后,我们就可以考虑用EM算法来对模型进行参数估计。
在算法的E步中,需要求完全数据的对数似然函数的期望。假设在第t一
1次迭代开始时,X已知,而Y是变量,对Y积分有:
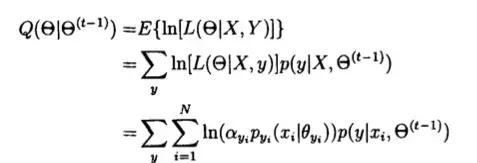
已知第i个观察x(i)来自第K个分支的概率为p,因此下边的式子可以写为:
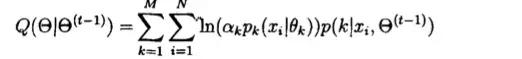
而由贝叶斯公式可知
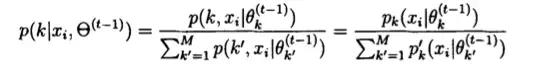
在接下来M步中,我们要求极大化式函数:
首先为了求u(k),可以将Q对u(k)进行求偏导并令其为零,即:
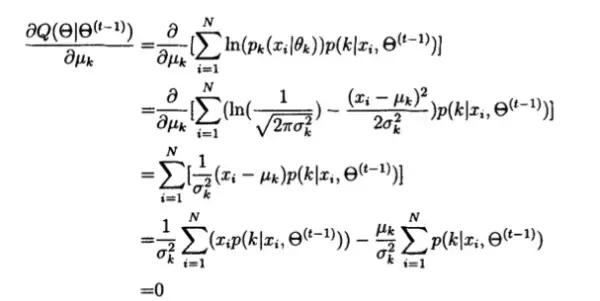
可得:
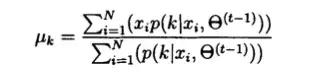
同理求&k平方:
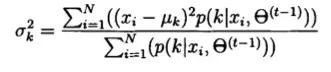
最后,为了求ak,我们引入拉格朗日乘子:
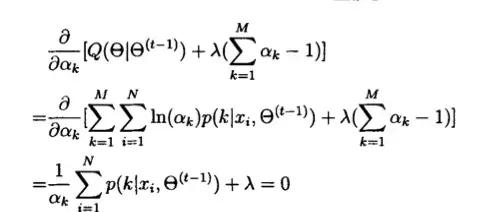
因此有:
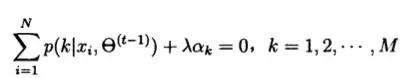
将这个式子进行求和得到:
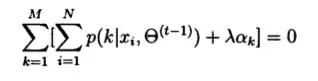
最后将入=-N带入上式,得到:
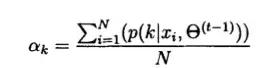
至此,我们得到所有参数的更新公式,通过编程可以实现迭代得到参数估 计。
4:至于HMM隐马尔科夫模型算法,我也是正在学习,以后再专门一篇文章进行讲述
总结:在写这一系列文章中,发现了EM算法当前存在的一些问题,但是自己的能力实在不行,比如尽管提到了使用N-R和aitken算法进行加速,但是计算还是太复杂,更有意思的是如何巧妙地拓展参数空间进行加速收敛.还有在高斯混合模型研究中,本文是因为事先知道GMM分支的数量来 进行估计的,但是如果给的是一堆杂乱的数据,需要解决如何确定分支的问题,才能更好的拟合样本,这是一个有待考虑的问题 .最后还有EM算法在其他模型中的应用,在其他方向的应用,如不止可以用来进行参数估计,还
可以进行假设检验等。
通过近期对EM算法的研究,可以看出EM算法在处理数据缺失问题中优势明显,算法和原理简单,收敛稳定,适用性广,当然其也存在诸多缺点(比如收敛速度慢;E步、M步计算困难)等,但是相信随着更多的学者对EM算法进行深入的研究,EM算法会得到更大的推广和改进,这些问题也都会逐步得到解决。
也希望这方面的相关人士可以给我一些指教,不胜感激.















 6005
6005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









