





由于标题长度的限制, 全称应该是:
解决python3 UnicodeEncodeError: 'gbk' codec can't encode character 'xXX' in position XX
最近在发送请求的时候,报以上的错误. 这个请求特别简单, 就是获取百度首页的内容:
import requests
r = requests.get('https://www.baidu.com')
resp = r.text
print(resp)错误信息让人很困惑,为什么用的是'utf-8'解码,错误信息却提示'gbk'错误呢?
百度首页的编码格式在源代码中可以看到:
<meta http-equiv="content-type" content="text/html;charset=utf-8">这说明网页的确用的是utf-8,为什么会出现Error呢?
在python3里,有几点关于编码的常识
1.字符就是unicode字符,字符串就是unicode字符数组
如果用以下代码测试,
print('b'=='u0062')会发现结果为True,足以说明两者的等价关系。
2. str转bytes叫encode,bytes转str叫decode,如上面的代码就是将抓到的字节流给decode成unicode数组
根据上面的错误信息分析了字节流中出现xe7的特殊字符,怀疑是它无法被解码。
用以下代码测试后
print(b'xe7'.decode('utf-8'))果然报错: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe7 in position 0: unexpected end of data
知道原因后,google了一下解决方法,其实print()函数的局限就是Python默认编码的局限,因为系统是win7的,python的默认编码不是'utf-8',改一下python的默认编码成'utf-8'就行了
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
r = requests.get('https://www.baidu.com')
resp = r.text
print(resp)运行后不报错了,但是居然有好多乱码(英文显示正常,中文则显示乱码)!!又一阵折腾后发现是控制台的问题,具体来说就是我在cmd下运行该脚本会有乱码,而在IDLE下运行却很正常。
由此我推测是cmd不能很好地兼容utf8,而IDLE就可以,甚至在IDLE下运行,连“改变标准输出的默认编码”都不用,因为它默认就是utf8。如果一定要在cmd下运行,那就改一下编码,比如我换成“gb18030”,依然有乱码:
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码添加了一行代码, 修改了响应的编码格式, r.encoding = 'utf-8', 问题解决.
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
r = requests.get('https://www.baidu.com')
r.encoding = 'utf-8'
resp = r.text
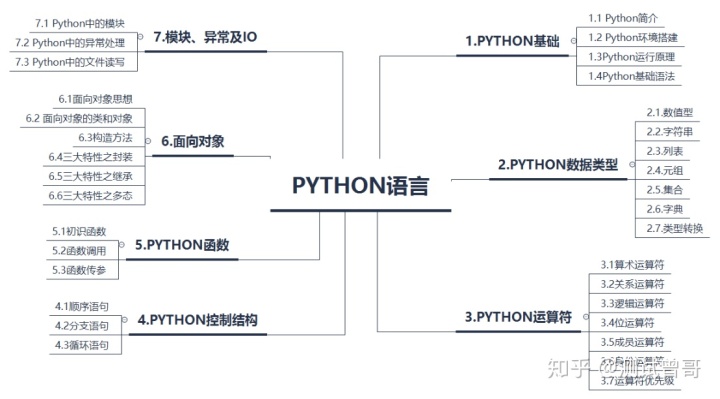
print(resp)【重要消息】感谢知友您能够看到这部分内容,本文是软件测试系列知识中python脚本语言中的一篇,笔者认为本部分全面的知识应该包含如下图所示的内容:
如果知友对这部分内容感兴趣,可以持续关注小编的账号,除此之外,小编还录制了不少这方面的技术视频,知友如果有需要,可以私聊本小编获取哦!















 73
73











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









