






一 实验目的
通过用逻辑回归算法对鸢尾花数据进行分类,帮助学生掌握逻辑回归算法的原理和使用场景、掌握导入数据、预处理数据、模型训练、模型评估、模型优化、可视化方法。
二 实验内容
逻辑回归算法是应用非常广泛的一个数据挖掘算法,它将数据拟合到一个logistic函数中,从而能够完成对事件发生的概率进行预测。
本实验用Sklearn模块的LogisticRegression类对鸢尾花数据集训练一个逻辑回归模型。
三 实验数据
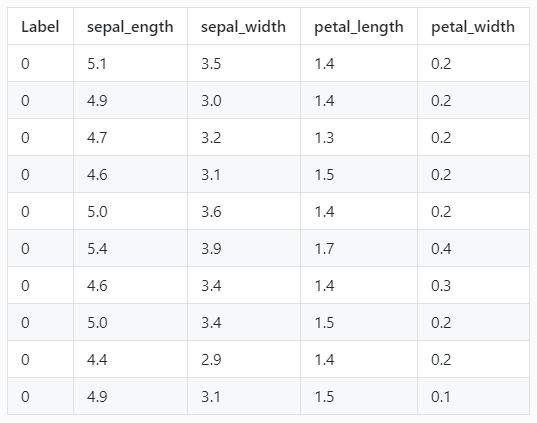
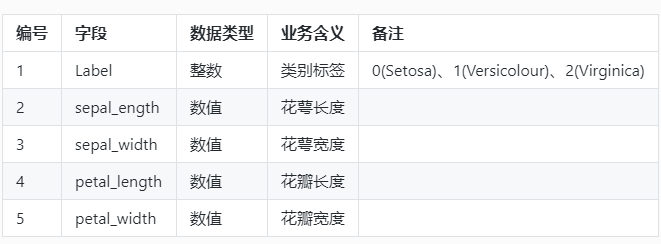
本实验所用数据集是鸢尾花卉数据集,保存在 iris.csv文件中,该数据集有150行5列,第一行是标题,其他每行表示一个样本。第一列是标签,后面4列是特征。每个样本有一个类别标签和个四个特征组成,四个特征分别是:
花萼长度(sepal_length)
花萼宽度(sepal_width)
花瓣长度(petal_length)
花瓣宽度(petal_width)
分为3个类别,三个类别分别用整数表示:0(Setosa),1(Versicolour),2(Virginica)。
前10条数据如下表所示:
字段说明
五 实验环境
实验环境是Spyder的Python语言编辑器。
Python语言3.6版本。
scikit-learn 0.21.2版本
六 实验步骤
1 导入软件包
import pandas as pd
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")设置控制台显示格式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5693
5693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









