





 本文解析了《建筑防烟排烟系统技术标准》及《汽车库、修车库、停车场设计防火规范》中的关键规定,包括排烟防火阀的设置位置、排烟风机的控制方式及其连锁关闭条件。
本文解析了《建筑防烟排烟系统技术标准》及《汽车库、修车库、停车场设计防火规范》中的关键规定,包括排烟防火阀的设置位置、排烟风机的控制方式及其连锁关闭条件。


一、《建筑防烟排烟系统技术标准》GB51251-2017
4.4.10 排烟管道下列部位应设置排烟防火阀: 1 垂直风管与每层水平风管交接处的水平管段上; 2 一个排烟系统负担多个防烟分区的排烟支管上; 3 排烟风机入口处; 4 穿越防火分区处。【解读】“排烟防火阀”共有以上四种设置部位。
二、《建筑防烟排烟系统技术标准》GB51251-20175.2.2 排烟风机、补风机的控制方式应符合下列规定:
1 现场手动启动;
2 火灾自动报警系统自动启动;
3 消防控制室手动启动;
4 系统中任一排烟阀或排烟口开启时,排烟风机、补风机自动启动;5 排烟防火阀在280℃时应自行关闭,并应连锁关闭排烟风机和补风机。
2、综合起来说,对于车库而言,下“图一”中任何一个排烟防火阀在280℃时应能自行关闭,并应连锁关闭排烟风机。
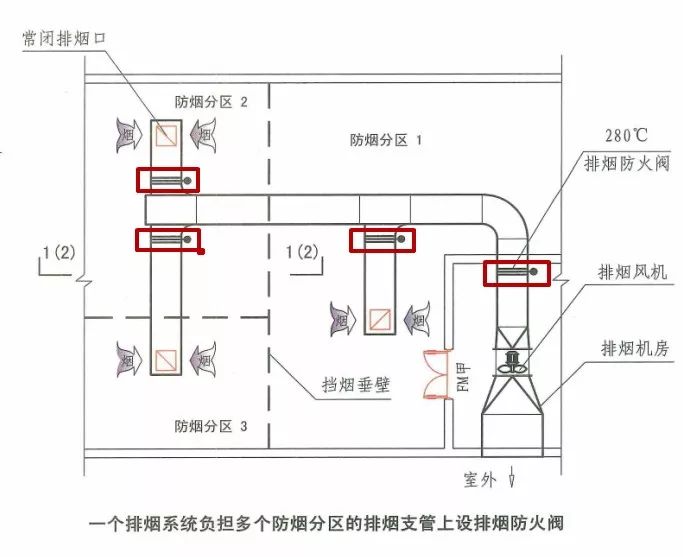
对于车库与非车库机械排烟系统,应由哪些排烟防火阀连锁关闭排烟风机,是有较大区别的。



















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









