





1.1、按照CentOS中Hadoop之HDFS的安装和配置搭建环境之后,发现启动的时候报:
2020-08-03 22:09:39,841 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Encountered exception loading fsimageorg.apache.hadoop.hdfs.server.common.IncorrectVersionException: Unexpected version of storage directory /home/hadoop/tmp/dfs/name. Reported: -63. Expecting = -60. at org.apache.hadoop.hdfs.server.common.StorageInfo.setLayoutVersion(StorageInfo.java:178) at org.apache.hadoop.hdfs.server.common.StorageInfo.setFieldsFromProperties(StorageInfo.java:131) at org.apache.hadoop.hdfs.server.namenode.NNStorage.setFieldsFromProperties(NNStorage.java:635) at org.apache.hadoop.hdfs.server.namenode.NNStorage.readProperties(NNStorage.java:664) at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:389) at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:228) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1152) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:799) at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:614) at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:676) at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:844) at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:823) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1547) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1615)解决方法:
hdfs-site.xml
<configuration> <property> <name>dfs.replicationname> <value>2value> property> <property> <name>dfs.namenode.http-addressname> <value>192.168.225.133:50070value> property> <property> <name>dfs.name.dirname> <value>/home/hadoop/data/hadoopfs/namevalue> property> <property> <name>dfs.data.dirname> <value>/home/hadoop/data/hadoopfs/datavalue> property>configuration>core-site.xml
<configuration> <property> <name>fs.defaultFSname> <value>hdfs://hadoop-master:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/home/hadoop/tmpvalue> property> <property> <name>io.file.buffer.sizename> <value>131072value> property>configuration>启动
# 格式化hadoop namenode –format/usr/local/hadoop/bin/hdfs namenode -format# 启动 -- 这里直接执行就可以start-dfs.sh# 验证jps界面访问:
http://192.168.225.133:50070/1.2、异常:
2020-08-04 02:00:37,011 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/hadoop/data/hadoopfs/data/java.io.IOException: Incompatible clusterIDs in /home/hadoop/data/hadoopfs/data: namenode clusterID = CID-cc346a2f-1d0b-49d3-9899-f8ed3e8fdd84; datanode clusterID = CID-9f0a79f5-7478-440a-aa71-e44436d3bed2 at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:779) at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:302) at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:418) at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:397) at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:575) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1570) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1530) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:354) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:219) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:674) at java.lang.Thread.run(Thread.java:745)2020-08-04 02:00:37,018 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool ID needed, but service not yet registered with NN, trace:解决方法:
清空集群每个节点目录的文件:/home/hadoop/data/hadoopfs/data/并执行:hadoop namenode -format2、集群配置
192.168.225.133 hadoop-master192.168.225.134 hadoop-slave免密登录
# --- hadoop-master# 生成密钥(Overwrite (y/n)? y )ssh-keygen -t rsa -P ""# (> 为替换 >> 为追加)cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys# 按照提示执行,需要输入一次密码ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@hadoop-slave# 测试ssh @hadoop-slave# ----hadoop-slave# 生成密钥(Overwrite (y/n)? y )ssh-keygen -t rsa -P ""# (> 为替换 >> 为追加)cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys# 按照提示执行,需要输入一次密码ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@hadoop-master# 测试ssh @hadoop-master同时修改hdfs-site.xml和slaves文件
# 修改hdfs-site.xml --- 可以不用配置SecondaryNameNode# 增加 dfs.namenode.secondary.http-address 192.168.225.134:50090# slaves文件 --- 统一配置hadoop-masterhadoop-slaveyarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.resourcemanager.hostnamename> <value>hadoop-mastervalue> property>configuration>3.最终
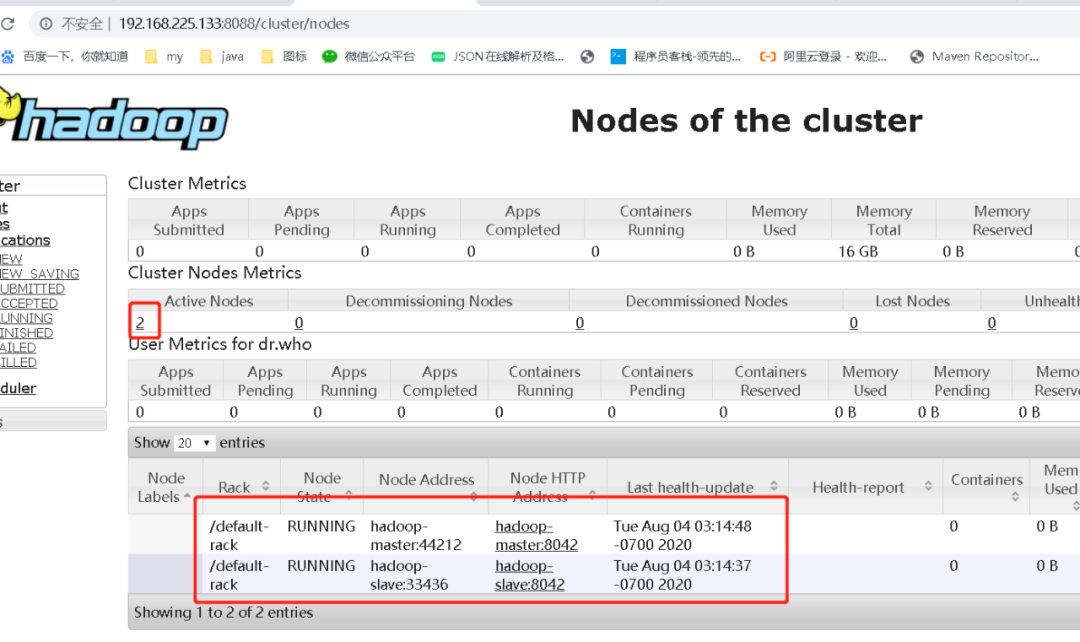
# 访问下面连接http://192.168.225.133:50070/dfshealth.html#tab-datanodehttp://192.168.225.133:8088/cluster/nodes# 如果达不到下面的效果,就需要执行:# 清空集群每个节点目录的文件:/home/hadoop/data/hadoopfs/data/# 并执行:hadoop namenode -format
附带:yarn-site.xml
NodeManager相关配置参数(1) yarn.nodemanager.resource.memory-mb参数解释:NodeManager总的可用物理内存。注意,该参数是不可修改的,一旦设置,整个运行过程中不可动态修改。另外,该参数的默认值是8192MB,即使你的机器内存不够8192MB,YARN也会按照这些内存来使用(傻不傻?),因此,这个值通过一定要配置。不过,Apache已经正在尝试将该参数做成可动态修改的。默认值:8192(2) yarn.nodemanager.vmem-pmem-ratio参数解释:每使用1MB物理内存,最多可用的虚拟内存数。默认值:2.1(3) yarn.nodemanager.resource.cpu-vcores参数解释:NodeManager总的可用虚拟CPU个数。默认值:8(4) yarn.nodemanager.local-dirs参数解释:中间结果存放位置,类似于1.0中的mapred.local.dir。注意,这个参数通常会配置多个目录,已分摊磁盘IO负载。默认值:${hadoop.tmp.dir}/nm-local-dir(5) yarn.nodemanager.log-dirs参数解释:日志存放地址(可配置多个目录)。默认值:${yarn.log.dir}/userlogs(6) yarn.nodemanager.log.retain-seconds参数解释:NodeManager上日志最多存放时间(不启用日志聚集功能时有效)。默认值:10800(3小时)(7) yarn.nodemanager.aux-services参数解释:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:""














 2789
2789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









