







一、1.感知机模型:
感知器模型是SVM、神经网络、深度学习等算法的基础;感知器模型就是试图找到一条直线,能够把所有的“+1”类和“-1”类分隔开,如果是高维空间中,感知器模型寻找的就是一个超平面,能够把所有的二元类别分割开。感知器模型的前提是:数据是线性可分的。
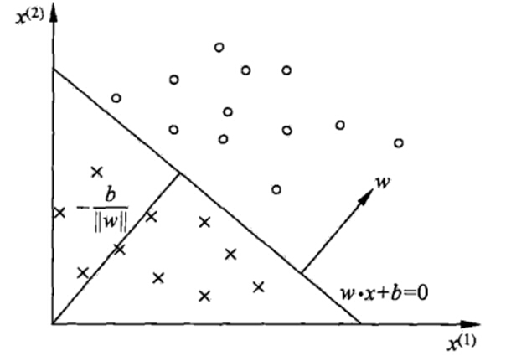
目标是找到一个超平面,即:
感知器模型为:
感知器模型正确分类(预测和实际类别一致):yθx>0(y为实际值,θx为预测值),错误分类(预测和实际类别不一致):yθx<0;所以我们可以定义我们的损失函数为:期望使分类错误的所有样本(k条样本)到超平面的距离之和最小。
即:
简化损失函数:因为此时分子和分母中都包含了θ值,当分子扩大N倍的时候,分母也会随之扩大,也就是说分子和分母之间存在倍数关系,所以可以固定分子或者分母为1,然后求另一个即分子或者分母的倒数的最小化作为损失函数,简化后的损失函数为(分母为1):
直接使用梯度下降法就可以对损失函数求解,不过由于这里的k是分类错误的样本点集合,不是固定的,所以我们不能使用批量梯度下降法(BGD)求解,只能使用随机梯度下降(SGD)或者小批量梯度下降(MBGD);一般在感知器模型中使用SGD来求解。
二、1.SVM(支持向量机)
支持向量机(Support Vecor Machine, SVM)本身是一个二元分类算法,是对感知器算法模型的一种扩展,现在的SVM算法支持线性分类和非线性分类的分类应用,并且也能够直接将SVM应用于回归应用中,同时通过OvR或者OvO的方式我们也可以将SVM应用在多元分类领域中。在不考虑集成学习算法,不考虑特定的数据集的时候,在分类算法中SVM可以说是特别优秀的。
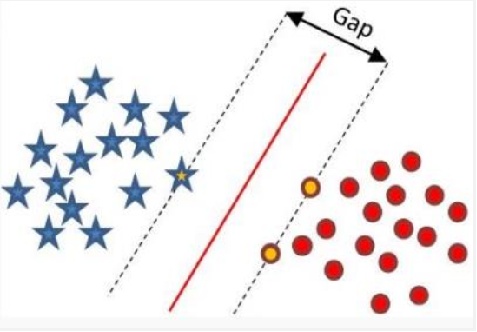
在感知器模型中,算法是在数据中找出一个划分超平面,让尽可能多的数据分布在这个平面的两侧,从而达到分类的效果,但是在实际数据中这个符合我们要求的超平面是可能存在多个的。

SVM思想:在感知器模型中,我们可以找到多个可以分类的超平面将数据分开,并且优化时希望所有的点(预测正确的点)都离超平面尽可能的远,但是实际上离超平面足够远的点基本上都是被正确分类的,所以这个是没有意义的;反而比较关心那些离超平面很近的点,这些点比较容易分错。所以说我们只要让离超平面比较近的点尽可能的远离这个超平面,那么我们的模型分类效果应该就会比较不错。SVM其实就是这个思想。

名词概念:
- 线性可分(Linearly Separable):在数据集中,如果可以找出一个超平面,将两组数据分开,那么这个数据集叫做线性可分数据。
- 线性不可分(Linear Inseparable):在数据集中,没法找出一个超平面,能够将两组数据分开,那么这个数据集就叫做线性不可分数据。
- 分割超平面(Separating Hyperplane):将数据集分割开来的直线/平面叫做分割超平面。
- 支持向量(Support Vector):离分割超平面最近的那些点叫做支持向量。
- 间隔(Margin):支持向量数据点到分割超平面的距离称为间隔。
支持向量到超平面的距离为:在SVM中支持向量到超平面的函数距离一般设置为1
∵
∵
∴
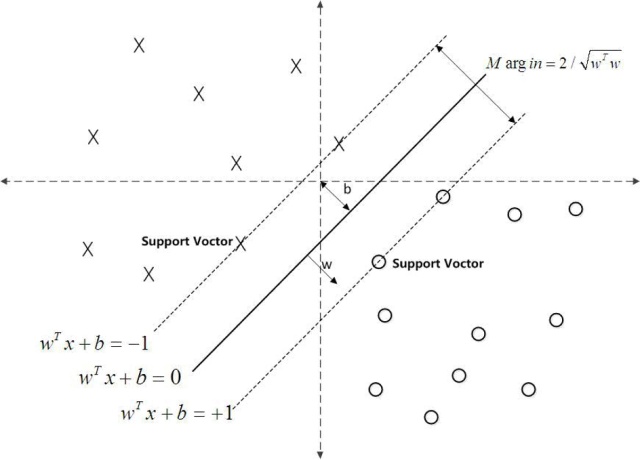
SVM模型是让所有的分类点在各自类别的支持向量远离超平面的一侧,同时要求支持向量尽可能的远离这个超平面,用数学公式表示如下:
W^{T}=(w_1,w_2,...,w_n)
(s.t: 指”受限制于...“)
则SVM原始目标函数/损失函数为:
将此时的目标函数和约束条件使用KKT条件转换为拉格朗日函数,从而转换为无约束的优化函数。
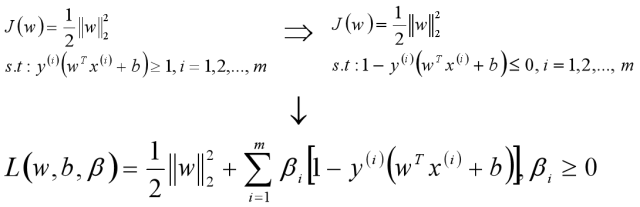
引入拉格朗日乘子后,优化目标变成:
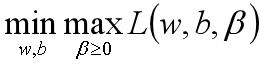
根据拉格朗日对偶化特性,将该优化目标转换为等价的对偶问题来求解,从而优化目标变成:
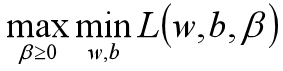
所以对于该优化函数而言,可以先求优化函数对于w和b的极小值,然后再求解对于拉格朗日乘子β的极大值。
首先求让函数L极小化的时候w和b的取值,这个极值可以直接通过对函数L分别求w和b的偏导数得到:
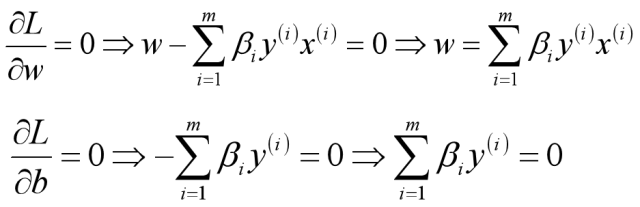
将求解出来的w和b带入优化函数L中,定义优化之后的函数如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









