





最近在win10下部署caffe ssd遇到了很多的坑,网上的很多资料有些细节不是很详细,或者不是很匹配。这里将我的具体步骤写下来,以供参考。
配置环境
- 系统:windows 10 64位
- GPU:GTX 750 Ti
- CUDA:9.0
- cudnn:7.0
- Python:Anaconda 2.7 version
- 编译:Visual Studio 2013
步骤一:安装
Visual Studio 2013,Anaconda 2.7 version 这些网上的安装教程很多,随便找一个就行。
CUDA以及cudnn的安装,我是参考以下教程:
CSDN-专业IT技术社区-登录blog.csdn.net到第二步就行,第三步安装TensorFlow-gpu与我们无关,不用看。
总结:这一步比较简单,只要一步步照做,不太会有出问题的地方。
步骤二:下载与编译
下载caffe-ssd-microsoft:
地址:https://github.com/conner99/caffe
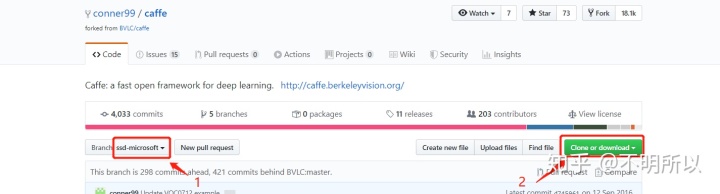
有git就用git下载,没有就下载ZIP。
这部分内容我主要参照了以下这篇文章的第三部分下载并编译caffe-ssd-microsoft。
CSDN-专业IT技术社区-登录blog.csdn.net但是编译的时候,我还是会报错,最后编译成功我主要做了以下几件事情,大家如果也遇到相关问题可以试一试。
- 如果遇到错误:error: too few arguments in function call cudnn.hpp 114;它的解决方法是:双击这个错误,找到报错的地方,做如下图的修改。(这里缺少了一个参数,可能是因为版本不一样)(神奇的是这个错误解决了,很多错误就消失了)

2. 如果遇到错误:MSB3073;它的解决方法是:在CommonSettings.props中的<CuDnnPath></CuDnnPath>之间不要输入任何路径。(参考资料)
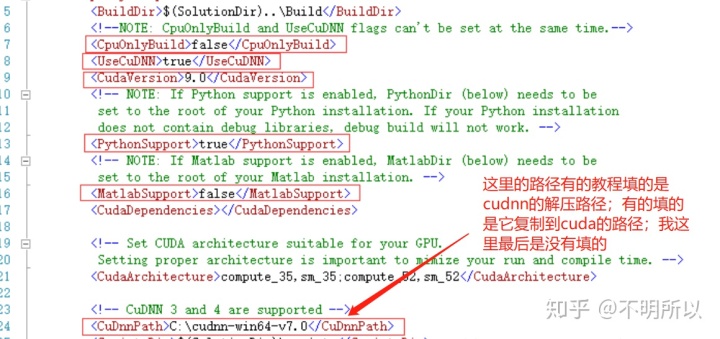
3. 以管理员身份运行VS2013。
4. 每次修改了一些东西,再次编译的时候先右击清理,再重新编译。(参考资料)
到这里如果你还没有编译成功,不要着急,多试几次。因为我也遇到过,第一天编译成功,第二天又编译失败的。所以又花了些许时间,最后也没改什么,就是清理——>重新编译就成功了。网上也有人说是网的问题,也不知道对不对,反正多试试。
总结:这部分问题比较多,遇到问题就网上搜,很多人也会遇到相同的问题,但是别人的方法不一定适合你,多去试一试,总会对的。
步骤三:制作数据集
制作数据集部分,网上有很多资料,但是讲的都不是特别的清楚。这里我主要参考以下文章。但后来我发现有些部分可以更加简便,所以这一部分我将详细地叙述。
CSDN-专业IT技术社区-登录blog.csdn.netcaffe的训练数据集是lmdb格式的,这里默认我们的数据集已经转化为VOC的数据格式。
我们将我们的VOC数据集保存在与windows同级的data目录下的VOC0712文件夹下,为了方便将它起名为VOC2007。如下图所示。
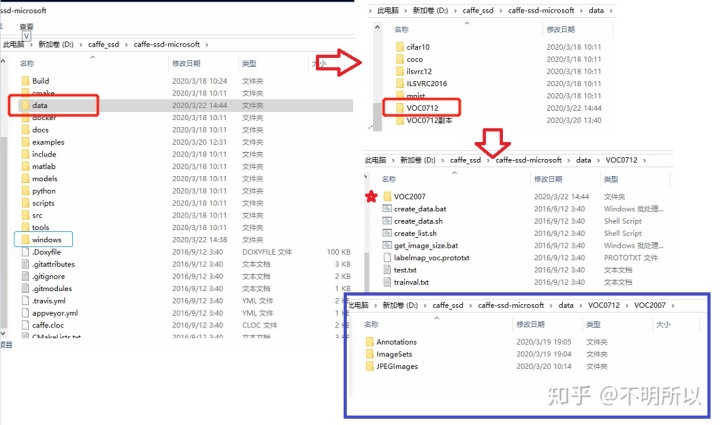
1)利用dataVOC0712下的create_list.sh建立trainval.txt和test.txt
windows下,create_list.sh脚本文件不能直接运行,这里我们借助于Git。(安装使用教程)
create_list.sh里面的内容如下,改动的地方(3个)已经中文标注出来了。
#!/bin/bash
root_dir=D:/caffe_ssd/caffe-ssd-microsoft/data/VOC0712 #改成自己的地址
sub_dir=ImageSets/Main
bash_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in VOC2007 # 我把VOC2012去了,若你没有命名为VOC2007这里也要改
do
if [[ $dataset == "test" && $name == "VOC2012" ]]
then
continue
fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir/$name/$sub_dir/$dataset.txt
img_file=$bash_dir/$dataset"_img.txt"
cp $dataset_file $img_file
sed -i "s/^/$name/JPEGImages//g" $img_file
sed -i "s/$/.jpg/g" $img_file
label_file=$bash_dir/$dataset"_label.txt"
cp $dataset_file $label_file
sed -i "s/^/$name/Annotations//g" $label_file
sed -i "s/$/.xml/g" $label_file
paste -d' ' $img_file $label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
#这一段全部注释掉了
# Generate image name and size infomation.
# if [ $dataset == "test" ]
# then
# $bash_dir/../../build/tools/get_image_size $root_dir $dst_file #$bash_dir/$dataset"_name_size.txt"
# fi
# Shuffle trainval file.
if [ $dataset == "trainval" ]
then
rand_file=$dst_file.random
cat $dst_file | perl -MList::Util=shuffle -e 'print shuffle(<STDIN>);' > $rand_file
mv $rand_file $dst_file
fi
done
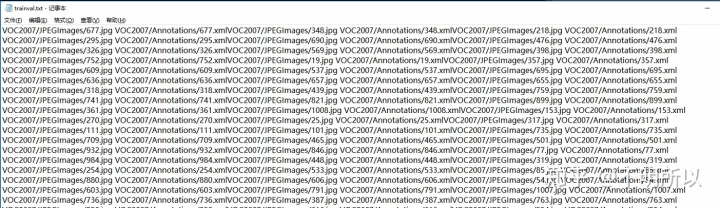
然后在Git里面运行该脚本文件。获得VOC0712目录下的文件trainval.txt和test.txt,如下图所示。
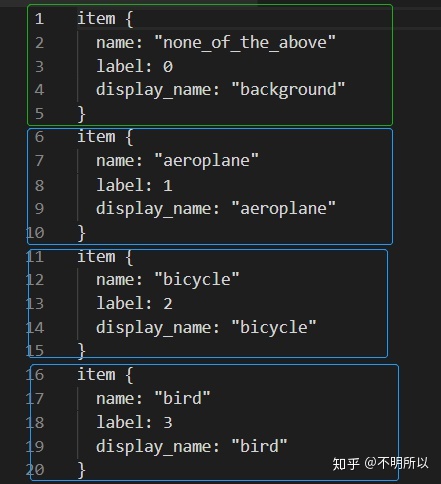
2)获得labelmap_voc.prototxt文件。在VOC0712目录下新建立一个文本文档,重命名为labelmap_voc.prototxt。里面的内容如下图,第一个类是背景,下面的为你训练数据集的种类,有几类写几个item。或者也可以用参考文章里面的方法生成labelmap_voc.prototxt文件。
3) 获得test_name_size.txt文件。双击运行在VOC0712目录下get_image_size.bat文件,文件内容如下:
cd D:caffe_ssdcaffe-ssd-microsoft #修改成自己的根目录,就是data的上级目录
.Buildx64Releaseget_image_size.exe .dataVOC0712 .datatest.txt .datatest_name_size.txt
pause

生成的文件如上,前面一个为测试集中图片的名字,后面为图像的长宽。
4)生成训练集和测试集
在dataVOC0712下新建create_data.bat, 内容如下:
set root_dir=D:caffe_ssdcaffe-ssd-microsoft #改成自己的根目录
cd %root_dir%
set redo=1
set data_root_dir=.dataVOC0712
set mapfile=%data_root_dir%labelmap_voc.prototxt
set anno_type=detection
set db=lmdb
set min_dim=0
set max_dim=0
set width=0
set height=0
set "extra_cmd=--encode-type=jpg --encoded"
if %redo%==1 (
set "extra_cmd=%extra_cmd% --redo"
)
for %%s in (trainval test) do (
echo Creating %%s lmdb...
python %root_dir%scriptscreate_annoset.py ^
--anno-type=%anno_type% ^
--label-map-file=%mapfile% ^
--min-dim=%min_dim% ^
--max-dim=%max_dim% ^
--resize-width=%width% ^
--resize-height=%height% ^
--check-label %extra_cmd% ^
--shuffle ^
%data_root_dir% ^
%data_root_dir%%%s.txt ^
%data_root_dir%%%s_%db%
)
pause
双击该文件,但是可能会报错。大部分我们都能在网上找到对应的对策,进行更改。
其中有一个类似于下图的错误:

解决方法如下:
修改在根目录下scripts目录中create_annoset.py中第160行的内容如下。

在VOC0712中生成了test_lmdb以及trainval_lmdb两个文件夹,这就是我们训练时要用的数据。
步骤四:训练
将train.prototxt, test.prototxt, deploy.prtotxt, solver.prototxt(文章提供了相关材料的下载,链接: https://pan.baidu.com/s/1jfi_t0fjDh630OMl8Q7AWQ 提取码: 5piq)拷贝到modelsVGGNetVOC0712SSD_300x300下. 并根据需求修改。
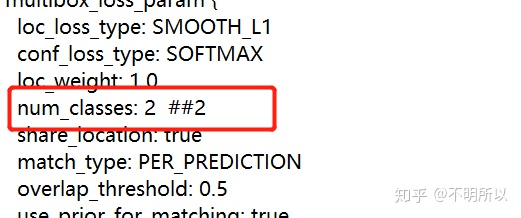
train.prototxt :根据GPU,设置其中batch_size的大小。如果数字过大,会报错。我这里设置了4。source也是训练数据集的相对地址。另外也要改一下类别数量。

test.prototxt 基本同上。
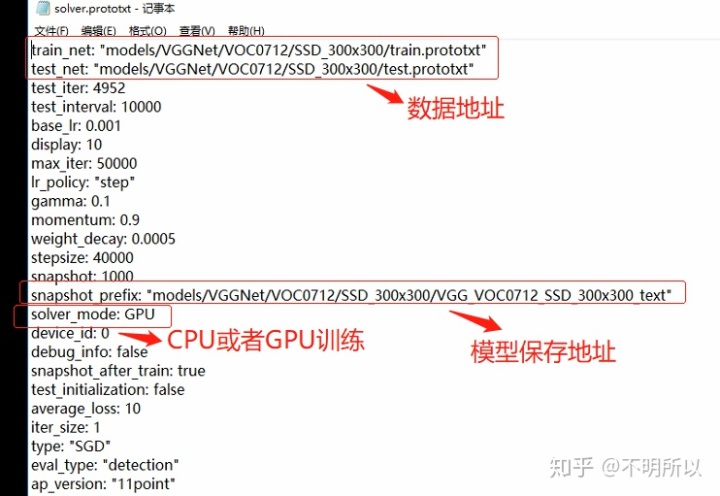
solver.prototxt如下:
一切准备好了就可以开始训练了。
在examplesssdVOC0712下新建ssd_pascal_VOC0712.bat, 内容如下:
cd D:caffe_ssdcaffe-ssd-microsoft #改成自己地址
.Buildx64Releasecaffe.exe train --solver=.modelsVGGNetVOC0712SSD_300x300solver.prototxt
pause
双击训练,这样就可以开始训练啦~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









