






关注公众号:SQL数据库开发,了解更多SQL高级知识
集合的定义
集合是由一个和多个元素构成的整体,在SQL Server中的表就代表着事实集合,而其中的查询就是在集合的基础上生成的结果集。SQL Server的集合包括交集(INTERSECT),并集(UNION),差集(EXCEPT)。
交集INTERSECT
可以对两个或多个结果集进行连接,形成“交集”。返回左边结果集和右边结果集中都有的记录,且结果不重复(这也是集合的主要特性)
交集限制条件
- 子结果集要具有相同的结构。
- 子结果集的列数必须相同
- 子结果集对应的数据类型必须可以兼容。
- 每个子结果集不能包含order by 和 compute子句。
交集示例
我们用以下两个表中的数据作为示例
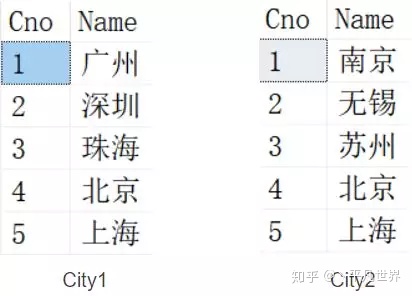
取以上两个表的交集,我们可以这样写SQL
SELECT 结果如下:
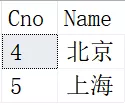
其中北京和上海是上面两个表共有的结果集。
这和我们的内连接(INNER JOIN)有点类似,以上SQL也可以这样写
SELECT 结果与上面结果相同。
并集UNION
可以对两个或多个结果集进行连接,形成“并集”。子结果集所有的记录组合在一起形成新的结果集。其中使用UNION可以得到不重复(去重)的结果集,使用UNION ALL可能会得到重复(不去重)的结果集。
并集限制条件
- 子结果集要具有相同的结构。
- 子结果集的列数必须相同
- 子结果集对应的数据类型必须可以兼容。
- 每个子结果集不能包含order by 和 compute子句。
UNION示例
还是以上面的City1和City2为例,取两个表的并集,我们可以这样写SQL:
SELECT 结果如下:
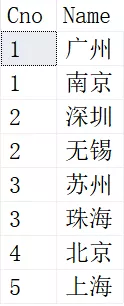
我们看到,北京和上海去掉了重复的记录,只保留了一次
UNION ALL示例
我们再看看使用UNION ALL会怎么样?
SELECT 结果如下:
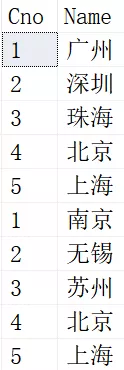
与上面的UNION相比,UNION ALL仅仅是对两个表作了拼接而已,北京和上海依然在下面重复出现了,而且细心的读着应该发现了,UNION还会对结果进行排序,而UNION ALL不会。
差集EXCEPT
可以对两个或多个结果集进行连接,形成“差集”。返回左边结果集合中已经有的记录,而右边结果集中没有的记录。
差集限制条件
- 子结果集要具有相同的结构。
- 子结果集的列数必须相同
- 子结果集对应的数据类型必须可以兼容。
- 每个子结果集不能包含order by 和 compute子句。
差集示例
以City1和City2为例,我们想取City1(左表)和City2(右表)的差集,可以这样写SQL:
SELECT 结果如下:
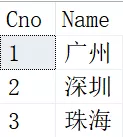
我们看到,因为北京和上海在两个表都存在,差集为了只显示左表中有的,而右表中没有的,就把这两个给过滤掉了。
此外我们常说的关联条件其实也是集合的一种,是通过子表的笛卡尔积按不同的关联条件过滤之后得到的结果集。有兴趣的同学可以阅读一下《Microsoft SQL SERVER 2008技术内幕 T-SQL查询》,这本书中有关于集合论的具体阐述。
批注
集合是我们数据处理过程中的理论基础,可以通过集合的观点去很好的理解不同的查询语句。每一个物理表就是一个集合,当我们要对表进行操作的时候,将它们看成对集合的操作就很好理解了。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









