






问题引入
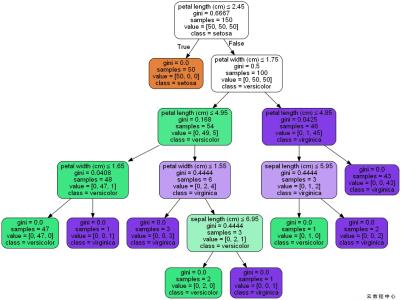
笔者在所有的面试中都会被问答到项目中的具体特征的情况,包括特征是如何得到的,为啥这个特征有效,做了哪些特征筛选,特征重要性是如何看的,和线性回归、逻辑回归这种广义线性模型不一样,简单的决策树的特征重要性又没有类似线性回归的系数可以用来说明特征重要性,那么,树模型的特征重要性是怎么计算的呢?
问题解答
对于简单的的决策树,sklearn中是使用基尼指数来计算的,也就是基尼不纯度,决策树首先要构造好后才可以计算特征重要性,当然,我们在构建树的过程中已近计算好了特征重要性的一些值,如基尼指数,最后我们得到特征重要性的话,就直接将基尼指数做些操作就可以了。在sklearn中,feature_importances_应当就是这个Gini importance,也是就
N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)其中,N是样本的总数,N_t是当前节点的样本数目,N_t_L是结点左孩子的样本数目,N_t_R是结点右孩子的样本数目。impurity直译为不纯度(基尼指数或信息熵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









