






> Photo taken by Justin Jairam from @jusspreme
在您自己的数据科学项目上工作是学习一些新技能和磨练现有技能的绝好机会,但是如果您想使用行业中使用的技术,例如Hadoop,分布式集群上的Spark,Hive等,以及 他们都融合了吗? 我相信这是建立自己的基础架构时价值的来源。

> Big Data Landscape
您会熟悉这些技术,了解它是如何工作的来龙去脉,调试并体验不同类型的错误消息,并真正了解该技术在整个系统中的工作方式,而不仅仅是与之交互。 如果通常还使用自己的私有数据或机密数据,则出于隐私或安全原因,您可能不希望将其上载到外部服务以进行大数据处理。 因此,在本教程中,我将逐步介绍如何在自己的计算机,家庭实验室等上设置自己的大数据基础架构。我们将设置一个单节点Hadoop&Hive实例和一个"分布式" spark实例。 与Jupyter集成。
本教程不适用于工业生产安装!
先决条件
· 基于Debian的发行版-Ubuntu,Pop-os等
· 基本的命令行知识有帮助,但对安装不是必不可少的
步骤1 —下载Hadoop和Hive
Hadoop无疑是当今行业中最常用的大数据仓库平台,并且对于任何大数据工作都是必不可少的。 简而言之,Hadoop是一个开放源代码软件框架,用于在大型(或廉价的水平扩展)硬件集群上以分布式方式存储和处理大数据。 您可以从此处下载最新版本。
通常将Hive添加到hadoop之上,以类似SQL的方式查询Hadoop中的数据。 蜂巢使工作容易执行
· 数据封装
· 临时查询
· 庞大的数据集分析
Hive相当慢,通常仅用于批处理作业。 较快的Hive版本将类似于Impala,但对于家庭使用来说,它可以完成工作。 您可以在此处下载最新版本的Hive。
确保您下载的是二进制(bin)版本而不是源(src)版本!
将文件解压缩到/ opt
cd ~/Downloads
tar -C /opt -xzvf apache-hive-3.1.2-bin.tar.gz
tar -C /opt -xzvf hadoop-3.1.3-src.tar.gz
将它们重命名为蜂巢和Hadoop。
cd /opt
mv hadoop-3.1.3-src hadoop
mv apache-hive-3.1.2-bin hive
步骤2 —设置授权(或无密码)SSH。
为什么我们需要这样做? Hadoop核心使用Shell(SSH)在从属节点上启动服务器进程。 它要求主机与所有从机和辅助计算机之间的无密码SSH连接。 如果您没有此资源,而我们处于完全分布式的环境中,则必须手动转到每个节点并启动每个过程。
由于我们仅运行Hadoop的单个实例,因此我们可以省去设置主机名,ssh密钥,将它们添加到每个框等的麻烦。如果是分布式环境,最好创建一个hadoop用户, 但是因此可以为个人使用而设置单个节点的好处。
真正简单易用,仅适合家庭使用,不应在其他任何地方使用或完成:
cat 〜/ .ssh / id_rsa.pub >>〜/ .ssh / authorized_keys
现在运行ssh localhost,您应该可以不用密码登录。
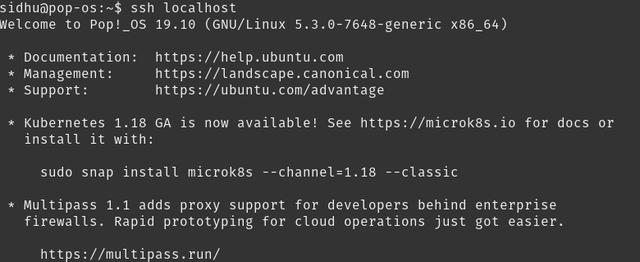
> Passwordless SSH login
要了解在分布式环境中设置网络和SSH配置所需的知识,可以阅读以下内容。
第3步-安装Java 8
可以说,本教程是最重要的步骤之一。
如果做错了,将导致花费大量时间调试模糊的错误消息,只是为了意识到问题所在,解决方案是如此简单。
Hadoop有一个主要要求,这是Java版本8。有趣的是,这也是Spark的Java要求,也非常重要。
sudo apt-get updatesudo apt-get install openjdk-8-jdk
验证Java版本。

> Java Version
如果由于某种原因在上方看不到输出,则需要更新默认的Java版本。
sudo update-alternatives –config Java
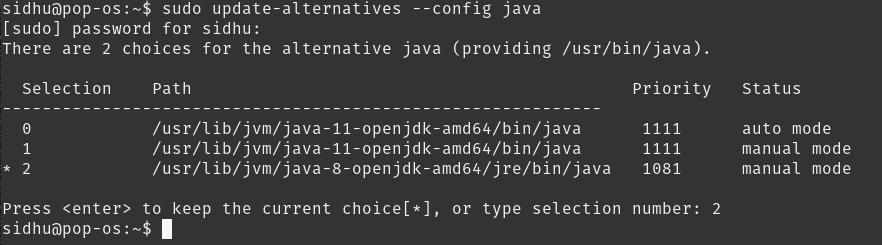
> Update Java version
选择与Java 8相关的编号。
再次检查版本。
Java版本
> Correct Java version
步骤4 —配置Hadoop + Yarn
Apache Hadoop YARN(另一个资源协商者)是一种集群管理技术。 从根本上讲,它可以帮助Hadoop管理和监视其工作负载。
初始Hadoop设置
首先,让我们设置环境变量。 这些将告诉其他组件每个组件的配置位于何处。
nano 〜/ .bashrc
将此添加到您的.bashrc文件的底部。
export HADOOP_HOME=/opt/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:$LD_LIBRARY_PATH
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
保存并退出nano CTRL + o,CTRL + x。
然后,我们需要通过运行源〜/ .bashrc激活这些更改。 您也可以关闭并重新打开终端以达到相同的结果。
接下来,我们需要建立一些目录并编辑权限。 制作以下目录:
sudo mkdir -p /app/hadoop/tmp
mkdir -p ~/hdfs/namenode
mkdir ~/hdfs/datanode
编辑/ app / hadoop / tmp的权限,授予其读取和写入访问权限。
sudo chown -R $USER:$USER /app
chmod a+rw -R /app
配置文件
所有Hadoop配置文件都位于/ opt / hadoop / etc / hadoop /中。
cd / opt / hadoop / etc / hadoop
接下来,我们需要编辑以下配置文件:
- core-site.xml- hadoop-env.sh- hdfs-site.xml- mapred-site.xml- yarn-site.xml
core-site.xml
hadoop.tmp.dir/app/hadoop/tmpParent directory for other temporary directories.fs.defaultFS hdfs://YOUR_IP:9000The name of the default file system.
hadoop.tmp.dir:可以自我解释,只是hadoop用来存储其他临时目录的目录fs.defaultFS:文件系统的IP和端口,可以通过网络进行访问。 它应该是您的IP,以便其他节点可以连接到它(如果这是分布式系统)。
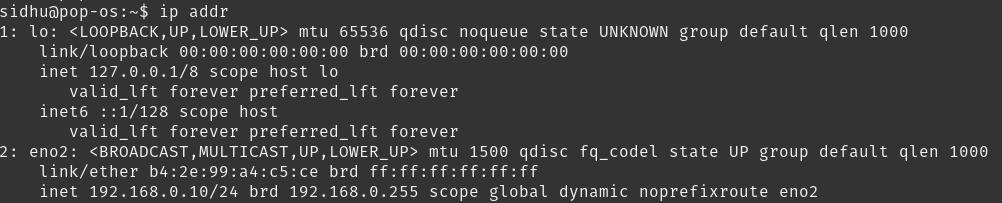
要找到您的IP,请在命令行上输入ip addr或ifconfig:
hadoop-env.sh
· 确定Java 8 JDK的位置,它应该与/ usr / lib / jvm / java-8-openjdk-amd64 /类似或相同。
· 将以下行添加到hadoop-env.sh:
export JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64 /
hdfs-site.xml
dfs.replication1Default block replication.dfs.name.dirfile:///home/YOUR_USER/hdfs/namenodedfs.data.dirfile:///home/YOUR_USER/hdfs/datanode
dfs.replication:要在其上复制数据的节点数。
dfs.name.dir:namenode块的目录
dfs.data.dir:数据节点块的目录
mapred-site.xml
mapreduce.framework.nameyarnmapreduce.jobtracker.addresslocalhost:54311yarn.app.mapreduce.am.envHADOOP_MAPRED_HOME=$HADOOP_MAPRED_HOMEmapreduce.map.envHADOOP_MAPRED_HOME=$HADOOP_MAPRED_HOMEmapreduce.reduce.envHADOOP_MAPRED_HOME=$HADOOP_MAPRED_HOMEmapreduce.map.memory.mb4096mapreduce.reduce.memory.mb4096
mapreduce.framework.name:用于执行MapReduce作业的运行时框架。 可以是本地,经典或毛线之一。
mapreduce.jobtracker.address:MapReduce作业跟踪程序运行的主机和端口。 如果是"本地",则作业将作为单个映射在流程中运行,并减少任务。
yarn.app.mapreduce.am.env:纱线图减少env变量。
mapreduce.map.env:Map reduce map env变量。
mapreduce.reduce.env:映射减少reduce env变量。
mapreduce.map.memory.mb:Hadoop允许分配给映射器的内存上限,以兆字节为单位。 默认值为512。
mapreduce.reduce.memory.mb:Hadoop允许分配给减速器的内存上限,以兆字节为单位。 默认值为512。
yarn-site.xml
yarn.resourcemanager.hostnamelocalhostyarn.nodemanager.aux-servicesmapreduce_shuffleyarn.nodemanager.resource.memory-mb16256yarn.app.mapreduce.am.resource.mb4096yarn.scheduler.minimum-allocation-mb4096
yarn.resourcemanager.hostname:RM的主机名。 也可以是远程yarn实例的ip地址。
yarn.nodemanager.aux-services:选择需要设置的随机播放服务以运行MapReduce。
yarn.nodemanager.resource.memory-mb:可以分配给容器的物理内存量(以MB为单位)。 供参考,我的计算机上有64GB的RAM。 如果此值太低,您将无法处理大文件,并出现FileSegmentManagedBuffer错误。
yarn.app.mapreduce.am.resource.mb:此属性指定为特定作业选择资源的条件。 任何具有相等或更多可用内存的节点管理器都将被选择执行作业。
yarn.scheduler.minimum-allocation-mb:RM上每个容器请求的最小分配,以MB为单位。 低于此数量的内存请求将不会生效,并且指定的值将被分配到最少。
启动Hadoop
在开始Hadoop之前,我们必须格式化namenode:
hdfs namenode-格式
现在,我们很好地开始了Hadoop! 运行以下命令:
start-dfs.shstart-yarn.sh
为确保一切已开始,请运行以下命令:
ss -ln | grep 9000

> Port 9000 network info
运行jps
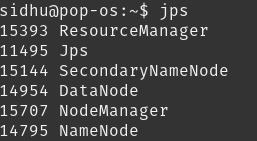
> Running Java programs
现在,您还可以通过http:// localhost:9870访问Hadoop Web UI。
> Hadoop Web UI
您还可以通过localhost:8088访问Yarn Web UI。

> Yarn Web UI
第5步-设置配置单元
现在我们已经建立并运行了Hadoop,让我们在其之上安装Hive。
首先,让我们在Hadoop中创建一个目录,将其存储在我们的Hive表中。
hdfs dfs -mkdir -p /用户/配置单元/仓库
配置权限。
hdfs dfs -chmod -R a + rw / user / hive
设置一个元存储
Hive Metastore是Hive元数据的中央存储库。 它存储Hive表和关系(方案和位置等)的元数据。 它通过使用metastore服务API提供客户端对此信息的访问。 有3种不同类型的元存储库:
· 嵌入式Metastore:一次只能打开一个Hive会话。
· 本地Metastore:多个Hive会话,必须连接到外部数据库。
· 远程Metastore:多个Hive会话,使用Thrift API与Metastore进行交互,具有更好的安全性和可伸缩性。
要详细了解每种类型的元存储之间的区别,这是一个很好的链接。
在本指南中,我们将使用MySQL数据库设置远程元存储。
sudo apt updatesudo apt install mysql-server
sudo mysql_secure_installation
运行以下命令:
sudo mysql
CREATE DATABASE metastore;
CREATE USER 'hive'@'%' IDENTIFIED BY 'PW_FOR_HIVE';
GRANT ALL ON metastore.* TO 'hive'@'%' WITH GRANT OPTION;
将PW_FOR_HIVE替换为您要在MySQL中为配置单元用户使用的密码。
下载MySQL Java连接器:
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.19.tar.gz
tar -xzvf mysql-connector-java-8.0.19.tar.gz
cd mysql-connect-java-8.0.19
cp mysql-connector-java-8.0.19.jar /opt/hive/lib/
编辑hive-site.xml
现在编辑/opt/hive/conf/hive-site.xml:
javax.jdo.option.ConnectionURLjdbc:mysql://YOUR_IP:3306/metastore?createDatabaseIfNotExist=true&useLegacyDatetimeCode=false&serverTimezone=UTCmetadata is stored in a MySQL serverjavax.jdo.option.ConnectionDriverNamecom.mysql.jdbc.DriverMySQL JDBC driver classjavax.jdo.option.ConnectionUserNamehiveuser name for connecting to mysql serverjavax.jdo.option.ConnectionPasswordPW_FOR_HIVEpassword for connecting to mysql server
用本地IP地址替换YOUR_IP。 将PW_FOR_HIVE替换为您先前为hive用户启动的密码。
初始化架构
现在,让您可以从网络上的任何地方访问MySQL。
nano /etc/mysql/mysql.conf.d/mysqld.cnf
将绑定地址更改为0.0.0.0。
重新启动服务以使更改生效:sudo systemctl restart mysql.service
最后,运行schematool -dbType mysql -initSchema来初始化metastore数据库中的模式。
启动Hive Metastore
Hive-服务元存储
测试配置单元
首先通过调用hive从命令行启动Hive。
让我们创建一个测试表:
CREATE TABLE IF NOT EXISTS test_table (col1 int COMMENT 'Integer Column', col2 string COMMENT 'String Column') COMMENT 'This is test table' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
然后插入一些测试数据。
INSERT INTO test_table VALUES(1,'testing');
然后,我们可以从表中查看数据。
SELECT * FROM test_table;
第6步-设置Spark
Spark是通用分布式数据处理引擎,适用于多种情况。 在Spark核心数据处理引擎之上,还有用于SQL,机器学习,图形计算和流处理的库,它们可以在应用程序中一起使用。 在本教程中,我们将使用Docker设置一个独立的Spark集群,并使其能够增加任意数量的工作人员。 这背后的原因是我们要模拟一个远程集群及其所需的一些配置。
在生产环境中,通常将Spark配置为使用Yarn和已分配给Hadoop的资源。
首先,我们需要创建Docker文件。 在本教程中,我们将使用Spark版本2.4.4,但如果您想要最新版本,则可以将其更改为2.4.5,它也随Hadoop 2.7一起提供,以管理节点之间的持久性和簿记。 在生产环境中,Spark通常配置有Yarn以使用现有的Hadoop环境和资源,因为我们只有一个节点上有Hadoop,所以我们将运行一个独立的Spark集群。 要将Spark配置为与Yarn一起运行,需要进行最小的更改,您可以在此处看到设置的差异。
设置独立群集
纳米Dockerfile
# DockerfileFROM python:3.7-alpineARG SPARK_VERSION=2.4.4ARG HADOOP_VERSION=2.7RUN wget -q https://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && tar xzf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz -C / && rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && ln -s /spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION} /sparkRUN apk add shell coreutils procpsRUN apk fetch openjdk8RUN apk add openjdk8RUN pip3 install ipythonENV PYSPARK_DRIVER_PYTHON ipython
现在,我们想启动一个Spark主机和N个Spark工作者。 为此,我们将使用docker-compose。nano docker-compose.yml
version: "3.3"networks: spark-network:services: spark-master: build: . container_name: spark-master hostname: spark-master command: > /bin/sh -c ' /spark/sbin/start-master.sh && tail -f /spark/logs/*' ports: - 8080:8080 - 7077:7077 networks: - spark-network spark-worker: build: . depends_on: - spark-master command: > /bin/sh -c ' /spark/sbin/start-slave.sh $$SPARK_MASTER && tail -f /spark/logs/*' env_file: - spark-worker.env environment: - SPARK_MASTER=spark://spark-master:7077 - SPARK_WORKER_WEBUI_PORT=8080 ports: - 8080 networks: - spark-network
对于主容器,我们为应用程序公开端口7077,为Spark作业UI公开端口8080。 对于工人,我们正在通过环境变量连接到我们的Spark master。
有关配置spark worker的更多选项,我们将它们添加到spark-worker.env文件中。
nano spark_worker
SPARK_WORKER_CORES=3SPARK_WORKER_MEMORY=8G
在此配置中,每个工作人员将使用3个内核并具有8GB的内存。 由于我的计算机具有6个核心,因此我们将启动2个工作线程。 我建议将其更改为与您的计算机相关的值。有关完整的环境变量列表以及独立模式下的信息,您可以在此处阅读完整的文档。 如果您想知道执行程序的存储空间,可以为每个应用程序设置,并在提交或启动应用程序时完成。
docker-compose build
docker-compose up -d --scale spark-worker=2
现在spark已启动并正在运行,您可以在localhost:8080上查看Web UI!

> Spark Web UI
在本地安装Spark
在您的本地计算机或将要创建或使用Spark的任何计算机上,都需要安装Spark,并且由于我们要将其配置为基于Hadoop / Hive构建,因此我们必须从源代码下载它。 在本教程中,我们将使用PySpark,而我的家庭项目中则主要使用Python。
您可以从此处下载Spark。
确保下载与主服务器上安装的版本相同的版本。 在本教程中,其版本为2.4.4
wget https://archive.apache.org/dist/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgztar -C /opt -xzvf spark-2.4.4-bin-hadoop2.7.tgz
设置Spark环境变量nano〜/ .bashrc
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
export PYSPARK_PYTHON=python3
如果您喜欢Jupyter Lab,请将PYSPARK_DRIVER_PYTHON_OPTS的"笔记本"更改为"实验室"。
配置文件
要配置Spark以使用我们的Hadoop和Hive,我们需要在Spark config文件夹中同时拥有两个配置文件。
cp $HADOOP_HOME/etc/hadoop/core-site.xml /opt/spark/conf/cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml /opt/spark/conf/
nano /opt/spark/conf/hive-site.xml
hive.metastore.uristhrift://YOUR_IP:9083spark.sql.warehouse.dirhdfs://YOUR_IP:9000/user/hive/warehouse
hive.metastore.uris:告诉Spark使用Thrift API与Hive Metastore进行交互。 spark.sql.warehouse.dir:告诉Spark我们的Hive表在HDFS中的位置。
安装PySpark
pip3 install pyspark == 2.4.4或将2.4.4替换为您在spark master上安装的任何版本。
要运行PySpark连接到我们的分布式集群,请运行:
pyspark –master spark:// localhost:7077,您也可以将localhost替换为您的IP或远程IP。
这将启动预定义了Spark上下文的Jupyter Notebook。 现在,您有一个环境可以运行Spark应用程序和分析以及正常的非分布式应用程序和分析。
默认情况下,执行程序内存仅为〜1GB(1024mb),要增加内存,请使用以下命令启动pyspark:
pyspark –master spark:// localhost:7077 –executor-memory 7g
Spark中每个执行器的开销为10%,因此我们最多可以分配7200mb,但是为了安全起见,我们将舍入数取为7。
测试整合
默认情况下,会自动创建一个SparkContext,变量为sc。
从以前创建的配置单元表中读取。
from pyspark.sql import Hive
Contexthc = HiveContext(sc)
hc.sql("show tables").show()
hc.sql("select * from test_table").show()
要从Hadoop读取文件,命令为:
sparksession = SparkSession.builder.appName("example-pyspark-read-and-write").getOrCreate()
df = (sparksession .read .format("csv") .option("header", "true") .load("hdfs://YOUR_IP:9000/PATH_TO_FILE"))
反馈
我鼓励所有有关此职位的反馈。 您可以给我发电子邮件sidhuashton@gmail.com或在帖子上发表评论,如果您有任何疑问或需要任何帮助。
您也可以通过@ashtonasidhu与我联系并在Twitter上关注我。
(本文翻译自Ashton Sidhu的文章《Tutorial: Building your Own Big Data Infrastructure for Data Science》,参考:https://towardsdatascience.com/tutorial-building-your-own-big-data-infrastructure-for-data-science-579ae46880d8)















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









