







我们知道多进程编程中,进程之间可以创建共享内存,这是最快的进程通信的方式。那么,对于分布式系统,如何共享数据呢?Spark提供了两种在Spark集群中创建和使用共享变量的机制:广播变量和累加器。
本文介绍广播变量的基本概念和实现原理。
基本概念
Spark官方对广播变量的说明如下:
广播变量可以让我们在每台计算机上保留一个只读变量,而不是为每个任务复制一份副本。例如,可以使用他们以高效的方式为每个计算节点提供大型输入数据集的副本。Spark也尽量使用有效的广播算法来分发广播变量,以降低通信成本。
另外,Spark action操作会被划分成一系列的stage来执行,这些stage根据是否产生shuffle操作来进行划分的。Spark会自动广播每个stage任务需要的通用数据。这些被广播的数据以序列化的形式缓存起来,然后在任务运行前进行反序列化。也就是说,在以下两种情况下显示的创建广播变量才有用:1)当任务跨多个stage并且需要同样的数据时;2)当以反序列化的形式来缓存数据时。
从以上官方定义我们可以得出Spark广播变量的一些特性:
1)广播变量会在每个worker节点上保留一份副本,而不是为每个Task保留一份副本。这样有什么好处?可以想象,在一个worker有时同时会运行若干的Task,若把一个包含较大数据的变量为Task都复制一份,而且还需要通过网络传输,应用的处理效率一定会受到很大影响。
2)Spark会通过某种广播算法来进行广播变量的分发,这样可以减少通信成本。Spark使用了类似于BitTorrent协议的数据分发算法来进行广播变量的数据分发,该分发算法会在后面进行分析。
3)广播变量有一定的适用场景:当任务跨多个stage,且需要同样的数据时,或以反序列化的形式来缓存数据时。
本文,将围绕官方对广播变量的定义来分析其实现原理。在分析前,先来看一下广播变量的使用。
广播变量的创建和使用
假设你有一个变量: v。要使用该变量来创建一个广播变量时,非常简单,只需要调用SparkContext的broadcast(v)函数即可。在spark-shell下代码如下:
scala> val v = Array(1,2,3,4,5,6)
v: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> val bv = sc.broadcast(v)
res1: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(1)
scala> bv
res9: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(2)
// 获取广播变量的值
scala> bv.value
res10: Array[Int] = Array(1, 2, 3, 4, 5, 6)
// 销毁广播变量
scala> bv.destory我们把一个变量v(一个普通数组)转换成了一个广播变量bv。通过查看bv的类型,可以看出bv是一个Array[Int]类型的广播变量。我们可以通过bv.value来获取广播变量的值。这样,广播变量bv就可以用到以后的数据计算中了。
注意,在创建广播变量时,广播变量的值必须是本地的可序列化的值,不能是RDD。
另外,广播变量一旦创建就不应该再修改,这样可以保证所以的worker节点上的值是一致的。这是因为,现有worker将看不到更新的值,新的worker才可能会看到新的值。
广播变量的实现原理
我们根据广播变量的创建和使用流程来分析广播变量的实现。广播变量的实现过程如下图2所示:
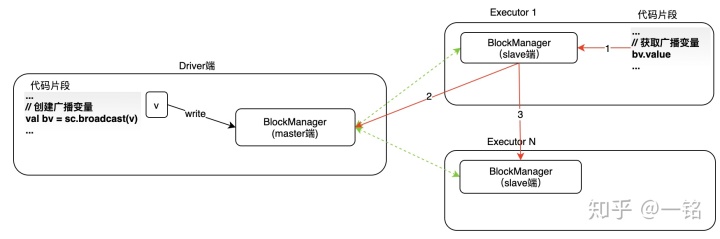
注:BlockManager是Spark数据块管理模块,会在后面的文章详细分析。
广播变量的创建
广播变量的创建发生在Driver端,如图2所示,当调用SparkContex
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









