






小伙伴们好啊,日常工作中,很多小伙伴都会遇到一些不规范的数据,很多小伙伴对字符串的提取问题也是头疼不已,今天咱们就分享一期关于字符串提取的内容。
一、提取字符串中的英文
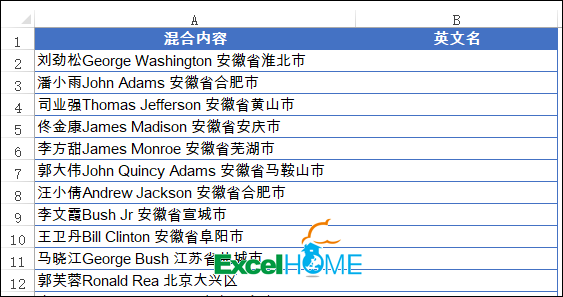
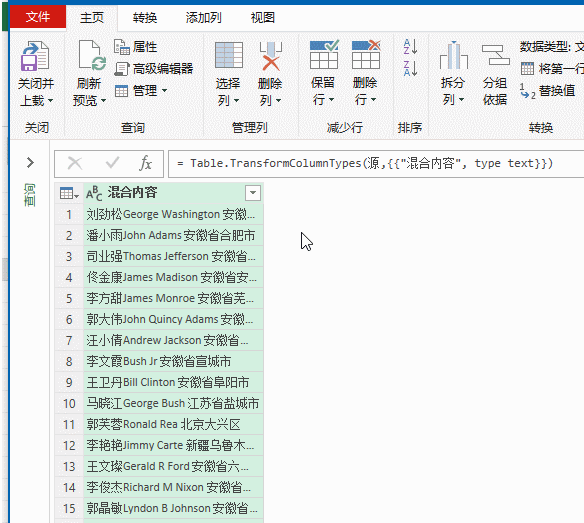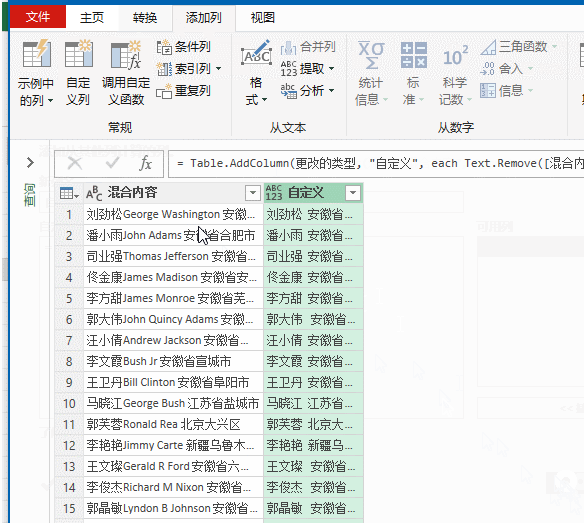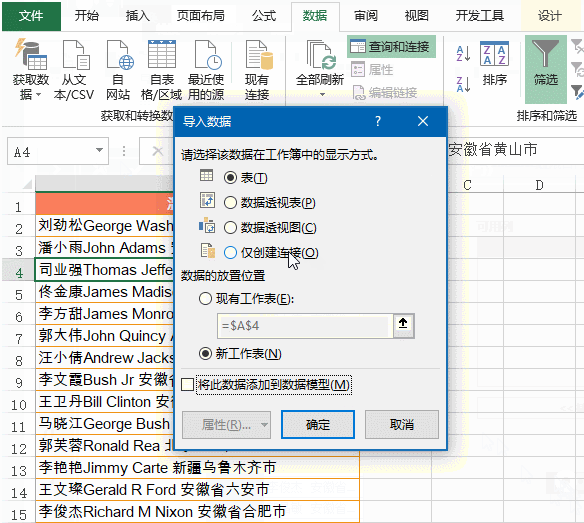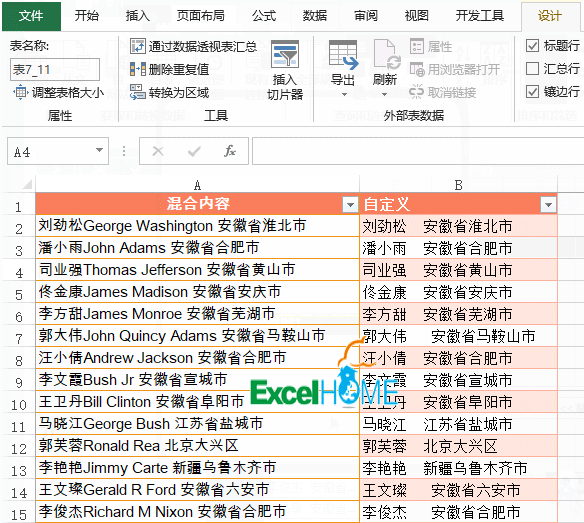
先来看下面的数据,是一些混到一起的客户信息,有姓名、英文名和住址,现在咱们要提取出其中的英文名。
 有小伙伴可能首先想到的就是在2013及以上版本中的快速填充功能,嗯嗯,可以实现要求,但是这个功能有很大的局限性,第一是数据源变化后不能更新,第二是要求数据必须要有非常明显的规律性,否则结果就会出错,因此快速填充功能不是今天咱们讨论的主题。
熟悉函数公式的小伙伴应该在偷偷笑了,嗯嗯,函数公式也行,但是数据量多了的时候,函数公式直接歇菜,我可不想在电脑前面一直眼巴巴的等:
有小伙伴可能首先想到的就是在2013及以上版本中的快速填充功能,嗯嗯,可以实现要求,但是这个功能有很大的局限性,第一是数据源变化后不能更新,第二是要求数据必须要有非常明显的规律性,否则结果就会出错,因此快速填充功能不是今天咱们讨论的主题。
熟悉函数公式的小伙伴应该在偷偷笑了,嗯嗯,函数公式也行,但是数据量多了的时候,函数公式直接歇菜,我可不想在电脑前面一直眼巴巴的等:
 咱们要分享的方法,不但可以刷新,而且在数据量非常多的时候仍然可以快速返回结果。说了半天,究竟要使用什么方法呢?
猜对了——就是Power Query功能。
接下来咱们就以
Excel 2019
为例,看看具体的步骤:
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
咱们要分享的方法,不但可以刷新,而且在数据量非常多的时候仍然可以快速返回结果。说了半天,究竟要使用什么方法呢?
猜对了——就是Power Query功能。
接下来咱们就以
Excel 2019
为例,看看具体的步骤:
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
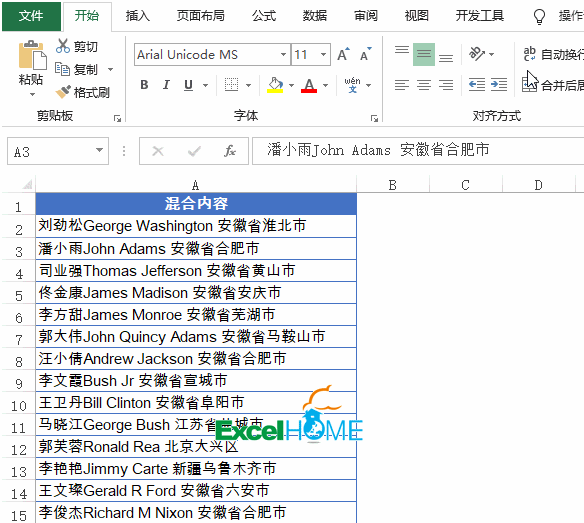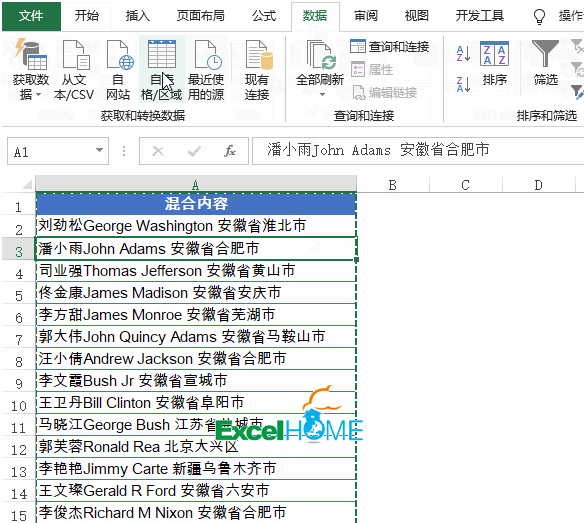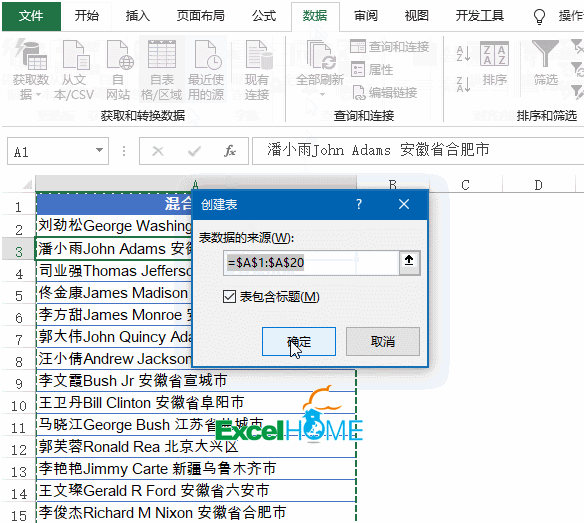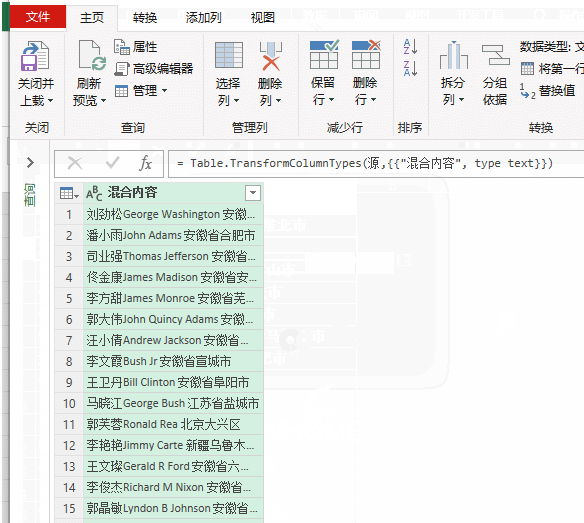 2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Remove([混合内容],{"一".."龟"})
然后删除原有的数据列,将数据加载到工作表。
2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Remove([混合内容],{"一".."龟"})
然后删除原有的数据列,将数据加载到工作表。
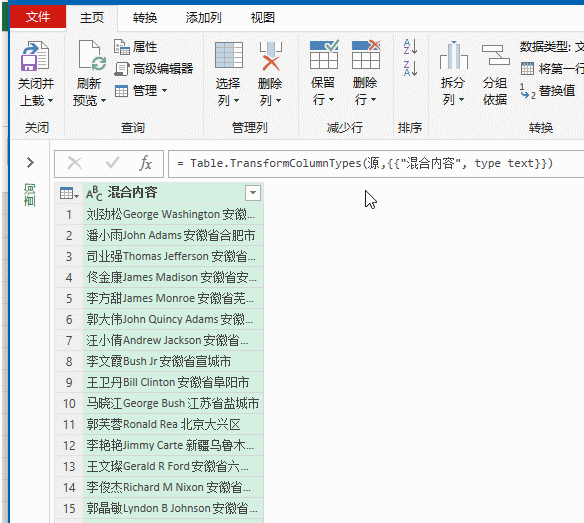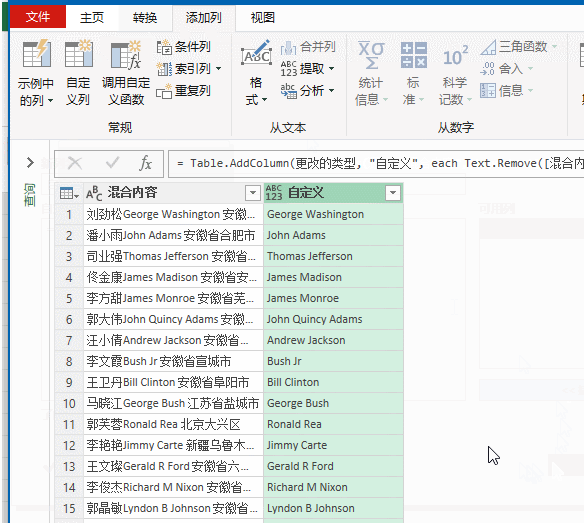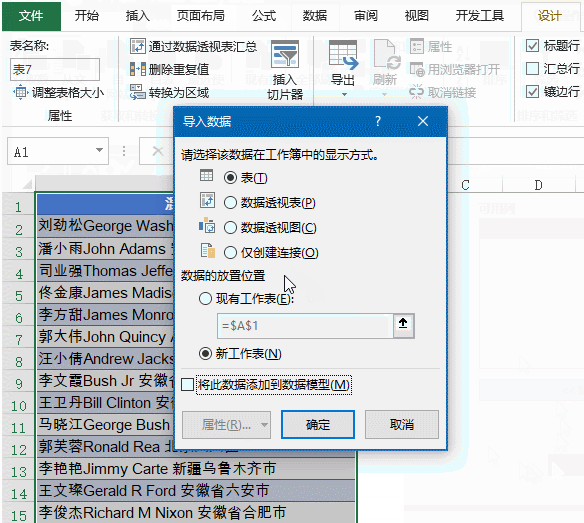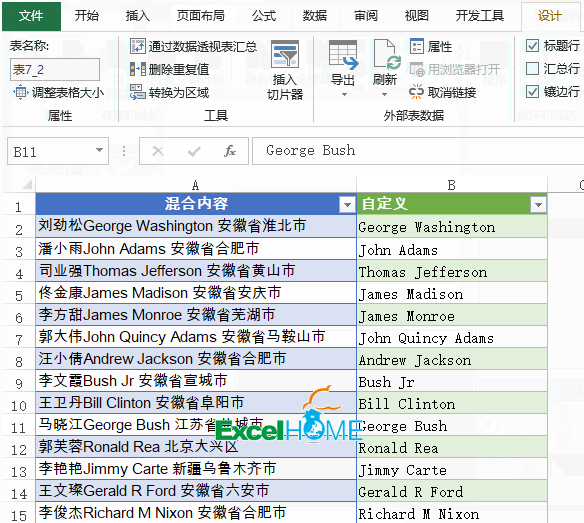 Text.Remove 函数是PQ中特有的函数,Text表示函数的类型,Remove的意思就是移除。函数的作用就是从字段中移除指定的字符。
这个函数有两个参数,第一个参数是要处理的字段,第二个参数是要移除的字符内容,公式中的{"一".."龟"}表示所有中文字符,也就是说只要是中文字符,就从【混合内容】字段中移除。
二、提取字符串中的中文
仍然以上面这组数据为例,要提取出其中的中文内容,也就是客户的姓名和地址信息。
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Remove([混合内容],{"A".."z"})
然后删除原有的数据列,将数据加载到工作表。
Text.Remove 函数是PQ中特有的函数,Text表示函数的类型,Remove的意思就是移除。函数的作用就是从字段中移除指定的字符。
这个函数有两个参数,第一个参数是要处理的字段,第二个参数是要移除的字符内容,公式中的{"一".."龟"}表示所有中文字符,也就是说只要是中文字符,就从【混合内容】字段中移除。
二、提取字符串中的中文
仍然以上面这组数据为例,要提取出其中的中文内容,也就是客户的姓名和地址信息。
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Remove([混合内容],{"A".."z"})
然后删除原有的数据列,将数据加载到工作表。
 公式的意思是从【混合内容】这个字段中,移除所有A~Z和a~z的字母。
三、提取字符串中的数字
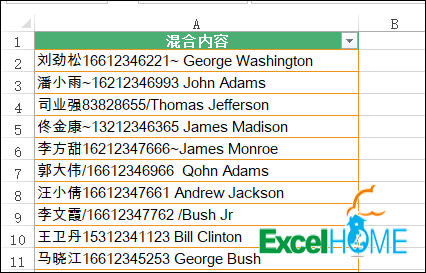
再看下面的数据,里面有中文、英文、数字还有一些间隔符号,需要从这些混合内容中,提取出电话信息:
公式的意思是从【混合内容】这个字段中,移除所有A~Z和a~z的字母。
三、提取字符串中的数字
再看下面的数据,里面有中文、英文、数字还有一些间隔符号,需要从这些混合内容中,提取出电话信息:
 要删除的字符类型太多了,这回咱们换一个函数。
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
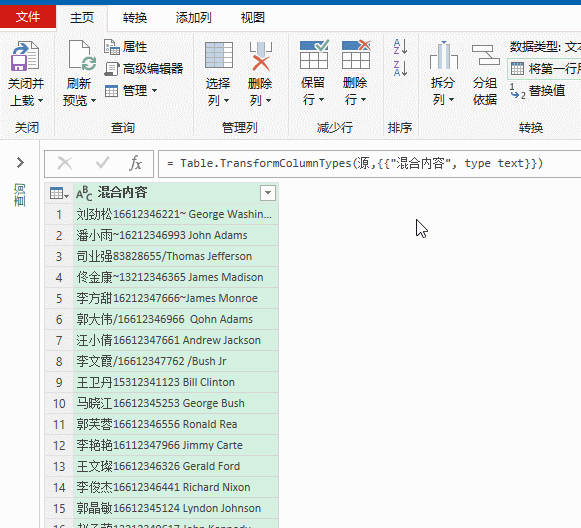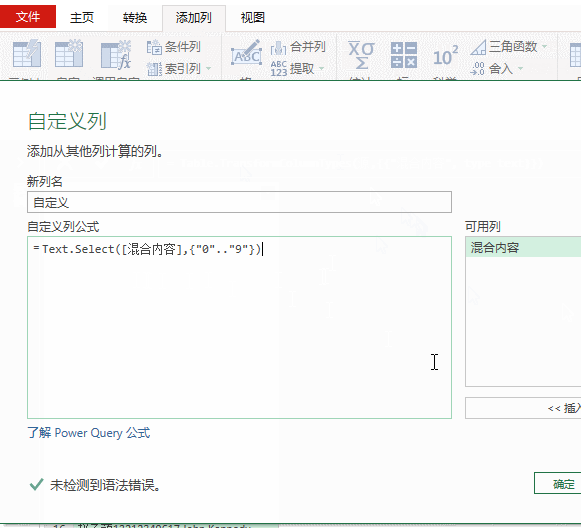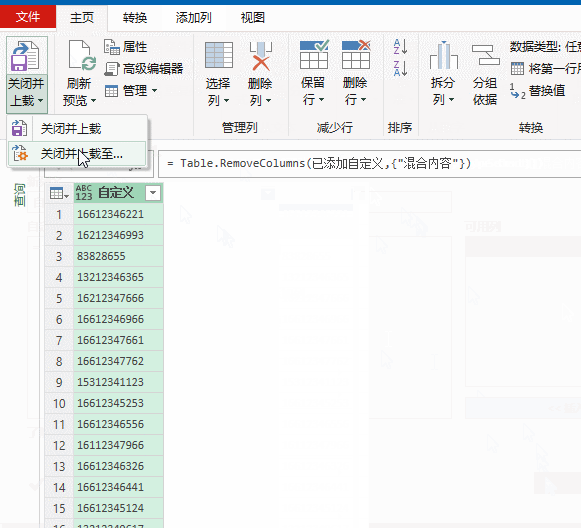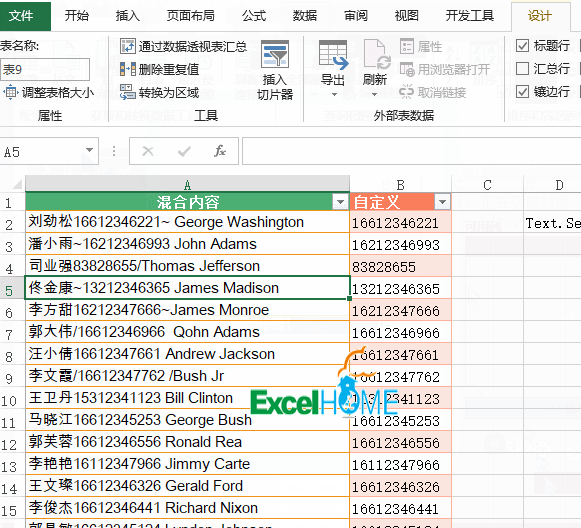
2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Select([混合内容],{"0".."9"})
然后删除原有的数据列,将数据加载到工作表。
要删除的字符类型太多了,这回咱们换一个函数。
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Select([混合内容],{"0".."9"})
然后删除原有的数据列,将数据加载到工作表。
 Text.Select 函数的作用和 Text.Remove 函数相反,Select的意思是挑选,顾名思义,Text.Select 函数就是从字段中挑选出指定的内容。
第二参数使用{"0".."9"},表示提取0至9的所有数字。如果要
提取是其他类型的内容,可以使用以下几个公式。
Text.Select 函数的作用和 Text.Remove 函数相反,Select的意思是挑选,顾名思义,Text.Select 函数就是从字段中挑选出指定的内容。
第二参数使用{"0".."9"},表示提取0至9的所有数字。如果要
提取是其他类型的内容,可以使用以下几个公式。
 编后话:
从Excel 2016版本开始,Power Query成为了内置功能,如果你使用的是2010或是2013版本的Excel,可以百度一下安装微软的Power Query插件。如果使用的是2007或是2003,那就尽快升级吧~
今天的练手文件在此,你也试试:
链接: https://pan.baidu.com/s/1lK4GHyuiWk0NHhCTjlMbmg
提取码: 4kga
编后话:
从Excel 2016版本开始,Power Query成为了内置功能,如果你使用的是2010或是2013版本的Excel,可以百度一下安装微软的Power Query插件。如果使用的是2007或是2003,那就尽快升级吧~
今天的练手文件在此,你也试试:
链接: https://pan.baidu.com/s/1lK4GHyuiWk0NHhCTjlMbmg
提取码: 4kga
有小伙伴可能首先想到的就是在2013及以上版本中的快速填充功能,嗯嗯,可以实现要求,但是这个功能有很大的局限性,第一是数据源变化后不能更新,第二是要求数据必须要有非常明显的规律性,否则结果就会出错,因此快速填充功能不是今天咱们讨论的主题。
熟悉函数公式的小伙伴应该在偷偷笑了,嗯嗯,函数公式也行,但是数据量多了的时候,函数公式直接歇菜,我可不想在电脑前面一直眼巴巴的等:
咱们要分享的方法,不但可以刷新,而且在数据量非常多的时候仍然可以快速返回结果。说了半天,究竟要使用什么方法呢?
猜对了——就是Power Query功能。
接下来咱们就以
Excel 2019
为例,看看具体的步骤:
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Remove([混合内容],{"一".."龟"})
然后删除原有的数据列,将数据加载到工作表。
Text.Remove 函数是PQ中特有的函数,Text表示函数的类型,Remove的意思就是移除。函数的作用就是从字段中移除指定的字符。
这个函数有两个参数,第一个参数是要处理的字段,第二个参数是要移除的字符内容,公式中的{"一".."龟"}表示所有中文字符,也就是说只要是中文字符,就从【混合内容】字段中移除。
二、提取字符串中的中文
仍然以上面这组数据为例,要提取出其中的中文内容,也就是客户的姓名和地址信息。
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Remove([混合内容],{"A".."z"})
然后删除原有的数据列,将数据加载到工作表。
公式的意思是从【混合内容】这个字段中,移除所有A~Z和a~z的字母。
三、提取字符串中的数字
再看下面的数据,里面有中文、英文、数字还有一些间隔符号,需要从这些混合内容中,提取出电话信息:
要删除的字符类型太多了,这回咱们换一个函数。
1、单击数据区域,数据→自表格/区域,将数据加载到数据查询编辑器
2、依次单击【添加列】→【自定义列】,输入公式:
=Text.Select([混合内容],{"0".."9"})
然后删除原有的数据列,将数据加载到工作表。
Text.Select 函数的作用和 Text.Remove 函数相反,Select的意思是挑选,顾名思义,Text.Select 函数就是从字段中挑选出指定的内容。
第二参数使用{"0".."9"},表示提取0至9的所有数字。如果要
提取是其他类型的内容,可以使用以下几个公式。
编后话:
从Excel 2016版本开始,Power Query成为了内置功能,如果你使用的是2010或是2013版本的Excel,可以百度一下安装微软的Power Query插件。如果使用的是2007或是2003,那就尽快升级吧~
今天的练手文件在此,你也试试:
链接: https://pan.baidu.com/s/1lK4GHyuiWk0NHhCTjlMbmg
提取码: 4kga














 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









