







集成方法 的目标是把使用多个给定学习算法构建的基本估计器的预测结果结合起来,从而获得比单个基本估计器更好的泛化能力/鲁棒性。 集成学习方法通常分为两种:
 ,其中M是树的数目,N 是样本数。可以通过设置以下参数来降低模型复杂度:
,其中M是树的数目,N 是样本数。可以通过设置以下参数来降低模型复杂度:
- 在平均方法(averaging methods)中,驱动原则是首先独立地构建若干个估计器,然后对它们的预测结果取平均。在平均意义上,组合得到的估计器通常优于任意一个基本估计器,因为它的方差被减小了。
- 相比之下,在增强方法(boosting methods)中,基本估计器是按顺序构建的,其中每一个基本估计器都致力于减小组合估计器的偏差。这种方法的动机是通过组合若干个弱模型来产生一个强大的集成模型。
1. Bagging元估计器(meta-estimator)
在集成算法中,bagging方法会在原始训练集的随机子集上构建黑盒估计器(black-box estimator)的多个实例,然后把这些估计器的预测结果结合起来形成最终的预测结果。该方法通过在构建模型的过程中引入随机性,来减少基本估计器的方差(例如,减小决策树的方差)。在多数情况下,bagging方法提供了一种非常简单的方式来对单一模型进行改进,而无需修改底层算法。因为bagging方法可以减小过拟合,所以通常在强分类器和复杂模型上使用时表现的很好(例如,完全决策树(fully developed decision trees)),相比之下boosting方法则在弱模型上表现更好(例如,浅层决策树(shallow decision trees))。 Bagging方法有多种风格,但它们之间的区别主要在于它们抽取训练集中随机子集的方法:- 如果抽取数据集的随机子集作为样本的随机子集,该方法称为粘贴(Pasting)[B1999]。
- 如果抽取样本是有放回的,该方法称为Bagging[B1996]。
- 如果抽取数据集的随机子集作为特征的随机子集,该方法称为“随机子空间(Random Subspaces)” [H1998]。
- 最后,如果是用样本和特征抽取的子集来构建基本估计器,该方法称为随机补丁(Random Patches)[LG2012]。
BaggingClassifier 元估计器(resp.
BaggingRegressor )提供的,用户指定的基本估计器以及随机子集的选择策略作为参数输入。特别需要指出的是,
max_samples 和
max_features 控制着子集的大小(对于样本和特征),而
bootstrap 和
bootstrap_features 控制着样本和特征的抽取是有放回还是无放回的。当使用样本子集时,通过设置
oob_score=True 可以使用袋外(out-of-bag)样本来评估泛化精度。下面代码说明了如何构造一个
KNeighborsClassifier 估计器的bagging集成实例,每一个基本估计器都建立在50%的样本随机子集和50%的特征随机子集上。
>>> from sklearn.ensemble import BaggingClassifier>>> from sklearn.neighbors import KNeighborsClassifier>>> bagging = BaggingClassifier(KNeighborsClassifier(),... max_samples=0.5, max_features=0.5)- 单一估计器与bagging :偏置方差分解https://urlify.cn/i2AfAz
2. 随机森林(Forests of randomized trees)
sklearn.ensemble 模块包括两种基于随机决策树的平均算法:RandomForest算法和Extra-Trees算法。两种算法都是专为树设计的扰动与组合技术(perturb-and-combine techniques)[B1998]。这意味着通过在分类器构造中引入随机性来创建多样化的分类器集。集成分类器的预测结果就是所有单个分类器预测结果的平均值。 与其他分类器一样,森林分类器(forest classifiers)必须要在两个数组上进行拟合:一个是用于训练样本的形状为
[n_samples, n_features] 的稠密或稀疏的X数组,另一个是与训练数据对应的目标变量(如类标签)的形状为
[n_samples] 的Y数组:
>>> from sklearn.ensemble import RandomForestClassifier>>> X = [[0, 0], [1, 1]]>>> Y = [0, 1]>>> clf = RandomForestClassifier(n_estimators=10)>>> clf = clf.fit(X, Y)[n_samples, n_outputs] 数组)。
2.1. 随机森林(Random Forests)
在随机森林中(参见RandomForestClassifier 和
RandomForestRegressor 类),每棵树构建时的样本都是由训练集经过有放回抽样得来的(例如,自助采样法(bootstrap sample))。 此外,在树的构造过程中拆分每个节点时,可以从所有输入特征或大小为
max_features 的随机子集中找到最佳拆分点。(有关更多详细信息,请参见参数调整准则 https://scikit-learn.org/stable/modules/ensemble.html#random-forest-parameters )。 这两个随机性的目的是减少森林估计器的方差。实际上,单个决策树通常表现出较高的方差并且倾向于过拟合。在森林中注入随机性来产生决策树,让其预测误差有所解耦。通过取这些预测结果的平均值,可以减少一些误差。随机森林通过组合不同的树来减少方差,有时会以略微增加偏差(bias)为代价。在实践中,由于方差的减小通常是很明显的,因此在总体上会产生更好的模型。 与原始出版的[B2001]相比,scikit-learn的实现是取每个分类器预测出的概率的平均,而不是让每个分类器对单个类别进行投票。
2.2. 极端随机树(Extremely Randomized Trees)
在极端随机树方法中(请参见ExtraTreesClassifier 和
ExtraTreesRegressor 类),随机性更进一步的体现在计算划分的方式上。极端随机树也和随机森林一样,使用了候选特征的随机子集,但是不同之处在于:随机森林为每个特征寻找最具分辨性的阈值,而在极端随机树里面每个特征的阈值是随机抽取的,这些随机生成的阈值里最好的阈值会被用来分割节点。这种更随机的做法通常能够使得模型的方差减小一点但是会使得模型的偏差稍微的增加一点:
>>> from sklearn.model_selection import cross_val_score>>> from sklearn.datasets import make_blobs>>> from sklearn.ensemble import RandomForestClassifier>>> from sklearn.ensemble import ExtraTreesClassifier>>> from sklearn.tree import DecisionTreeClassifier>>> X, y = make_blobs(n_samples=10000, n_features=10, centers=100,... random_state=0)>>> clf = DecisionTreeClassifier(max_depth=None, min_samples_split=2,... random_state=0)>>> scores = cross_val_score(clf, X, y, cv=5)>>> scores.mean()0.98...>>> clf = RandomForestClassifier(n_estimators=10, max_depth=None,... min_samples_split=2, random_state=0)>>> scores = cross_val_score(clf, X, y, cv=5)>>> scores.mean()0.999...>>> clf = ExtraTreesClassifier(n_estimators=10, max_depth=None,... min_samples_split=2, random_state=0)>>> scores = cross_val_score(clf, X, y, cv=5)>>> scores.mean() > 0.999True2.3. 参数(Parameters)
使用这些方法时,要调整的参数主要是n_estimators 和
max_features 。
n_estimators 是森林里的树的数量,通常数量越大,效果越好,但是计算时间也会随之增加。此外要注意,当树的数量超过一个临界值之后,算法的效果并不会很显著增加。
max_features 是分割节点时特征随机子集的大小,这个值越低,方差减小得越多,但是偏差的增加也越多。根据经验,回归问题中使用
max_features=n_features ,分类问题使用
max_features=sqrt(n_features) ,( 特征的个数
n_features 是比较好的默认值)。
max_depth=None 和
min_samples_split=2 的参数组合通常会有不错的效果(即生成完全的树)。请记住,这些(默认)值通常不是最佳的,同时还可能消耗大量的内存,最佳参数值应由交叉验证获得。另外,请注意,在随机森林中,默认使用自助采样法(
bootstrap=True ),然而极端随机树(extra-trees)的默认策略是使用整个数据集(
bootstrap=False )。当使用自助采样法方法抽样时,泛化精度是可以通过剩余的或者袋外的样本来估算的,可以通过设置
oob_score=True 来实现。
注意: 具有默认参数的模型复杂度为
,其中M是树的数目,N 是样本数。可以通过设置以下参数来降低模型复杂度:
min_samples_split ,
max_leaf_nodes ,
max_depth 和
min_samples_leaf 。
2.4. 并行化(Parallelization)
最后,该模块还支持树的并行构建和预测结果的并行计算,这可以通过n_jobs 参数实现。如果设置
n_jobs=k ,则计算被划分为
k 个作业,并运行在机器的
k 个核上。如果设置
n_jobs = -1 ,则使用机器的所有核进行工作。注意由于进程间通信具有一定的开销,这里的提速并不是线性的(即,使用
k 个作业并不意味着快
k 倍)。当然,在建立大量的树或者构建单个树需要相当长的时间(例如,在大数据集上)的情况下,(通过并行化)仍然可以实现显著的加速。
案例:
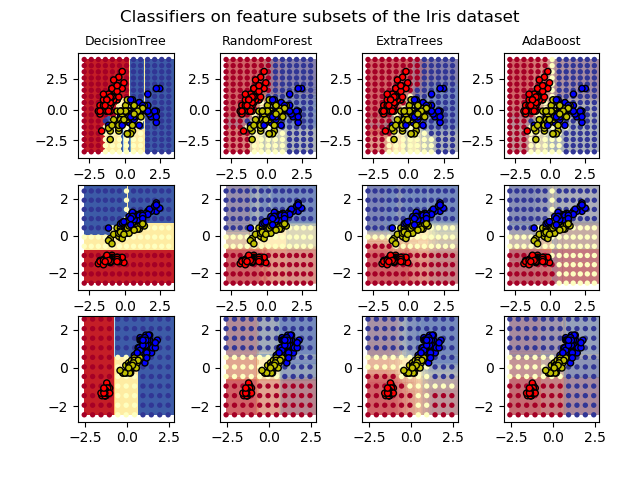
- 在鸢尾属植物数据集上绘制集成树的决策面https://urlify.cn/iaQJj2
- 由树构成的并行化森林用于显示像素的重要性https://urlify.cn/JjY3Mr
- 使用多输出估计器补全人脸https://urlify.cn/Mz6rqe
- [B2001] Breiman, “Random Forests”, Machine Learning, 45(1), 5-32, 2001.
- [B1998] Breiman, “Arcing Classifiers”, Annals of Statistics 1998.
- P. Geurts, D. Ernst., and L. Wehenkel, “Extremely randomized trees”, Machine Learning, 63(1), 3-42, 2006.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









