









论文名称:FaceNet: A Unified Embedding for Face Recognition and Clustering
论文下载:https://arxiv.org/abs/1503.03832
论文年份:CVPR 2015
论文被引:10437(2022/05/10)
论文代码:https://github.com/timesler/facenet-pytorch
论文总结
本文的主要贡献是提出了一种直接从人脸图像学习嵌入的框架 FaceNet,其使用 三元损失函数进行训练,并且选择三个样本是至关重要的,作者对此做了消融实验。具体地,FaceNet基于 LMNN [19] 的三元组的损失函数直接将其输出训练为紧凑的 128-D 嵌入(这个维度不是固定的,只是作者在权衡精度和速度做出的选择。)。
FaceNet架构有两种,一种是基于ZFNet,一种是基于Inception。
Abstract
Despite significant recent advances in the field of face recognition [10, 14, 15, 17], implementing face verification and recognition efficiently at scale presents serious challenges to current approaches. In this paper we present a system, called FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. Once this space has been produced, tasks such as face recognition, verification and clustering can be easily implemented using standard techniques with FaceNet embeddings as feature vectors.
Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches. To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method. The benefit of our approach is much greater representational efficiency: we achieve state-of-the-art face recognition performance using only 128-bytes per face.
On the widely used Labeled Faces in the Wild (LFW) dataset, our system achieves a new record accuracy of 99.63%. On YouTube Faces DB it achieves 95.12%. Our system cuts the error rate in comparison to the best published result [15] by 30% on both datasets.
We also introduce the concept of harmonic embeddings, and a harmonic triplet loss, which describe different versions of face embeddings (produced by different networks) that are compatible to each other and allow for direct comparison between each other.
尽管人脸识别领域最近取得了重大进展[10,14,15,17],但大规模有效地实施人脸验证和识别对当前方法提出了严峻挑战。在本文中,我们提出了一个名为 FaceNet 的系统,该系统直接学习从人脸图像到紧凑欧几里得空间的映射,其中距离直接对应于人脸相似度的度量。一旦产生了这个空间,就可以使用将 FaceNet 嵌入作为特征向量的标准技术轻松实现人脸识别、验证和聚类等任务。
为了进行训练,我们使用粗略对齐的匹配/不匹配人脸补丁(aligned matching / non-matching face patches)的三元组,这些补丁是使用一种新的在线三元组挖掘方法(online triplet mining method)生成的。
我们的方法使用经过训练的深度卷积网络直接优化嵌入本身,而不是像以前的深度学习方法那样使用中间瓶颈层。为了训练,我们使用了使用一种新颖的在线三元组挖掘方法生成的大致对齐匹配/非匹配面块的三元组。我们的方法的好处是更高的表示效率:我们实现了最先进的人脸识别性能,每张人脸仅使用 128 字节。
在广泛使用的野外标记人脸 (LFW) 数据集上,我们的系统达到了 99.63% 的新记录准确率。在 YouTube Faces DB 上,它达到了 95.12%。与已发表的最佳结果 [15] 相比,我们的系统在两个数据集上都将错误率降低了 30%。
我们还介绍了谐波嵌入(harmonic embeddings)的概念和谐波三元组损失(harmonic triplet loss),它们描述了相互兼容的不同版本的人脸嵌入(由不同的网络产生),并允许相互直接比较。
1. Introduction
在本文中,我们提出了一个统一的系统,用于人脸验证(这是同一个人吗)、识别(这个人是谁)和聚类(在这些人脸中找到普通人)。我们的方法基于使用深度卷积网络学习每个图像的欧几里得嵌入。网络经过训练,使得嵌入空间中的平方 L2 距离直接对应于人脸相似度:同一个人的脸距离小,不同人的脸距离大。
一旦产生了这种嵌入,那么上述任务就变得简单了:人脸验证只涉及对两个嵌入之间的距离进行阈值处理;识别变成了一个k-NN分类问题;聚类可以使用现成的技术来实现,例如 k-means 或凝聚聚类(agglomerative clustering)。
以前基于深度网络的人脸识别方法使用在一组已知的人脸身份上训练的分类层 [15, 17],然后将中间瓶颈层作为表示,用于泛化超出训练中使用的身份集的识别。这种方法的缺点是它的间接性和效率低下:人们必须希望瓶颈表示(bottleneck representation)能够很好地推广到新人脸;并且通过使用瓶颈层,每个人脸的表示大小通常非常大(1000 维)。最近的一些工作 [15] 使用 PCA 降低了这种维度,但这是一种线性变换,可以在网络的一层中轻松学习。
与这些方法相比,FaceNet 使用基于 LMNN [19] 的基于三元组的损失函数直接将其输出训练为紧凑的 128-D 嵌入。我们的三元组由两个匹配的人脸缩略图和一个不匹配的人脸缩略图组成,损失旨在将正对与负对分开一段距离。缩略图(thumbnails)是人脸区域的紧密裁剪,没有 2D 或 3D 对齐,除了执行缩放和平移。
选择使用哪些三元组对于实现良好的性能非常重要,并且受课程学习(curriculum learning) [1] 的启发,我们提出了一种新颖的在线负样本挖掘策略,可确保随着网络训练而不断增加三元组的难度。为了提高聚类准确性,我们还探索了难 (hard) 正例挖掘技术,这些技术鼓励球形聚类用于单个人的嵌入。

作为我们的方法可以处理的令人难以置信的可变性的说明,请参见图 1。显示的是来自 PIE [13] 的图像对,这些图像对以前被认为对于人脸验证系统来说非常困难。
本文其余部分的概述如下:在第 2 节中,我们回顾了该领域的文献; 3.1 节定义了三元组损失,3.2 节描述了我们新颖的三元组选择和训练过程;在 3.3 节中,我们描述了使用的模型架构。最后在第 4 节和第 5 节中,我们展示了嵌入的一些定量结果,并定性地探索了一些聚类结果。
2. Related Work
与最近使用深度网络的其他作品类似 [15, 17],我们的方法是一种纯粹的数据驱动方法,它直接从人脸的像素中学习其表示。我们没有使用工程特征,而是使用大量标记的人脸数据集来获得姿势、照明和其他变化条件的适当不变性(appropriate invariances)。
在本文中,我们探讨了两种不同的深度网络架构,它们最近在计算机视觉社区中取得了巨大的成功。两者都是深度卷积网络 [8, 11]。第一个架构基于 Zeiler&Fergus [22] 模型,该模型由多个交错的卷积层、非线性激活、局部响应归一化和最大池化层组成。受 [9] 的启发,我们还添加了几个 1×1×d 卷积层。第二种架构基于 Szegedy 等人的 Inception 模型。最近被用作 ImageNet 2014 [16] 的获胜方法。这些网络使用混合层,并行运行多个不同的卷积层和池化层,并将它们的响应连接起来。我们发现这些模型可以将参数数量减少多达 20 倍,并且有可能减少可比性能所需的 FLOPS 数量。
有大量的人脸验证和识别工作。回顾它超出了本文的范围,因此我们将仅简要讨论最近最相关的工作。
[15,17,23] 的工作都采用了一个多阶段的复杂系统,它将深度卷积网络的输出与 PCA 相结合以降低维度,并使用 SVM 进行分类。
[23] 使用深度网络将人脸“扭曲”为规范的正面视图,然后学习 CNN,将每个人脸分类为属于已知身份。对于人脸验证,网络输出上的 PCA 与一组 SVM 一起使用。
[17] 提出了一种多阶段方法,将人脸与一般的 3D 形状模型对齐。训练了一个多类网络以对四千多个身份执行人脸识别任务。作者还尝试了一个所谓的连体网络,他们直接优化了两个人脸特征之间的 L1 距离。他们在 LFW (97.35%) 上的最佳表现源于使用不同对齐和颜色通道的三个网络的集合。这些网络的预测距离(基于 χ2 核的非线性 SVM 预测)使用非线性 SVM 进行组合。
[14, 15] 提出了一种紧凑且因此相对便宜的计算网络。他们使用 25 个这些网络的集合,每个网络都在不同的人脸补丁上运行。对于他们在 LFW 上的最终表现(99.47% [15]),作者结合了 50 个响应(常规和翻转)。采用有效对应于嵌入空间中的线性变换的 PCA 和联合贝叶斯模型 [2]。他们的方法不需要明确的 2D/3D 对齐。通过使用分类和验证损失的组合来训练网络。验证损失类似于我们使用的三元组损失 [12, 19],因为它最小化了相同身份的人脸之间的 L2 距离,并在不同身份的人脸之间强制了一个边距。主要区别在于只比较成对的图像,而三元组损失鼓励相对距离约束。
[18] 探讨了与此处使用的损失类似的损失,通过语义和视觉相似性对图像进行排序。
3. Method
FaceNet 使用深度卷积网络。我们讨论了两种不同的核心架构:Zeiler&Fergus [22] 风格的网络和最近的 Inception [16] 类型的网络。这些网络的细节在 3.3 节中描述。
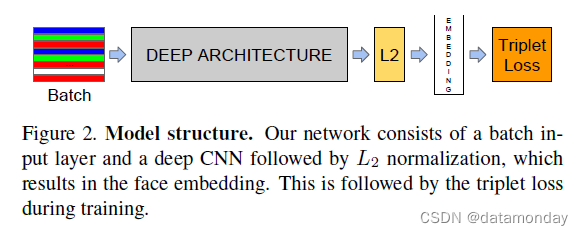
给定模型细节,并将其视为黑盒(见图 2),我们方法中最重要的部分在于整个系统的端到端学习。为此,我们采用了三元组损失,它直接反映了我们想要在人脸验证、识别和聚类中实现的目标。即,我们努力将 f(x) 从图像 x 嵌入到特征空间 Rd 中,使得所有具有相同身份的人脸之间的平方距离(与成像条件无关)很小,而一对来自不同身份的人脸图像之间的平方距离很大。
尽管我们没有直接与其他损失进行比较,例如一个使用正负对的方法,如 [14] 等式 (2) 中使用的那样,我们认为 triplet loss 更适合人脸验证。动机是 [14] 的损失鼓励将一个身份的所有人脸投影到嵌入空间中的单个点上。然而,triplet loss 试图在每对人脸之间从一个人到所有其他人脸强制执行一个边距。这允许一个身份的人脸生活在一个流形(mainfold)上,同时仍然加强距离,从而对其他身份进行区分。
以下部分描述了这种三元组损失以及如何大规模有效地学习它。
3.1. Triplet Loss

嵌入由
f
(
x
)
∈
R
d
f(x) ∈ R^d
f(x)∈Rd 表示。它将图像
x
x
x 嵌入到
d
d
d 维欧几里得空间中。此外,我们将这种嵌入**限制在
d
d
d 维超球面上,即
∣
∣
f
(
x
)
∣
∣
2
=
1
||f(x)||_2 = 1
∣∣f(x)∣∣2=1 **。这种损失是在 [19] 中在最近邻分类的背景下产生的。在这里,我们希望确保特定人的图像
x
i
a
x^a_i
xia(锚点)更接近同一个人的所有其他图像
x
i
p
x^p_i
xip(正),而不是任何其他人的任何图像
x
i
n
x^n_i
xin(负)。这在图 3 中可视化。
因此我们想要,
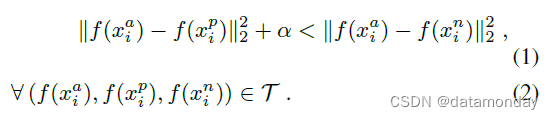
其中
α
α
α 是在正负对之间强制执行的边距。
T
\mathcal{T}
T 是训练集中所有可能的三元组的集合,具有基数
N
N
N。
最小化的损失是
L
L
L =
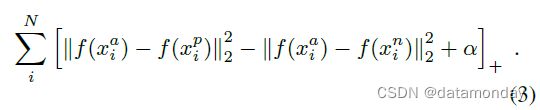
生成所有可能的三元组将导致许多容易满足的三元组,即满足等式 (1) 中的约束。这些三元组不会对训练做出贡献,并且会导致收敛速度变慢,因为它们仍然会通过网络。选择活跃的难三元组至关重要,因此有助于改进模型。以下部分讨论了我们用于三元组选择的不同方法。
3.2. Triplet Selection
为了确保快速收敛,选择违反等式 (1) 中的三元组约束的三元组至关重要。这意味着,给定 x i a x^a_i xia ,我们想要选择一个 x i p x^p_i xip (hard positive) 使得 a r g m a x x i p ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 2 argmax_{x^p_i} ||f(x^a_i ) − f(x^p _i )||^2_2 argmaxxip∣∣f(xia)−f(xip)∣∣22,并且类似地 x i n x^n_i xin (hard negative) 使得 a r g m i n x i n ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 2 argmin_{x^n_i} ||f(x^a_i ) − f (x^n_i) ||^2_2 argminxin∣∣f(xia)−f(xin)∣∣22。
计算整个训练集的 argmin 和 argmax 是不可行的。此外,它可能会导致训练不佳,因为错误标记和图像不佳的人脸会主导难正例和负例。有两个明显的选择可以避免这个问题:
- 每 n 步离线生成三元组,使用最近的网络检查点并在数据子集上计算 argmin 和 argmax。
- 在线生成三元组。这可以通过从小批量中选择硬正/负样本来完成。
在这里,我们专注于在线生成,并使用大约几千个样本的大型 mini-batch,并且只计算 mini-batch 中的 argmin 和 argmax。
为了对 anchor positive (锚点正例) 距离进行有意义的表示,需要确保确保任何一个身份的最小数量的样本出现在每个小批量中。在我们的实验中,我们对训练数据进行采样,使得每个小批量的每个身份选择大约 40 个人脸。
此外,随机采样的负例被添加到每个小批量中。我们没有选择最难的正例,而是在一个小批量中使用所有锚点正例对,同时仍然选择最难的负例。我们没有在小批量中对难锚点正例对和所有锚点正例对进行并排比较,但在实践中发现,所有锚点正例方法更稳定,并且在训练开始时收敛稍快。
我们还结合在线生成探索了三元组的离线生成,它可能允许使用较小的批量,但实验没有结论。
在实践中,选择最难的负样本可能会在训练早期导致局部最小值不佳,特别是它可能导致模型崩溃,即 f(x) = 0。为了减轻这种情况,它有助于选择
x
i
n
x^n_i
xin 使得
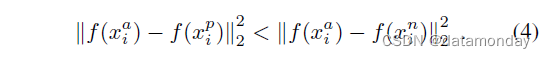
我们将这些负样本称为半难(semi-hard)样本,因为它们比正样本离锚点更远,但仍然很难,因为平方距离接近锚点正例距离。这些负例位于边距 α 内。
如前所述,正确的三元组选择对于快速收敛至关重要。一方面,我们希望使用小型 mini-batch,因为它们往往会在随机梯度下降 (SGD) [20] 期间提高收敛性。另一方面,实施细节使数十到数百个样本的批次更有效率。然而,关于批量大小的主要限制是我们从小批量中选择难相关三元组的方式。在大多数实验中,我们使用大约 1800 个样本的批量大小。
3.3. Deep Convolutional Networks
在我们所有的实验中,我们使用带有标准反向传播 [8, 11] 和 AdaGrad [5] 的随机梯度下降 (SGD) 来训练 CNN。在大多数实验中,我们从 0.05 的学习率开始,我们将其降低以最终确定模型。模型从随机初始化,类似于 [16],并在 CPU 集群上训练 1,000 到 2,000 小时。训练 500 小时后,损失的减少(和准确性的增加)急剧下降,但额外的训练仍然可以显着提高性能。余量 α 设置为 0.2。
我们使用了两种类型的架构,并在实验部分更详细地探讨了它们的权衡。它们的实际区别在于参数和 FLOPS 的不同。最佳模型可能因应用而异。例如。在数据中心运行的模型可以有很多参数,需要大量的 FLOPS,而在手机上运行的模型需要很少的参数,以便它可以放入内存中。
我们所有的模型都使用 ReLU 作为非线性激活函数。
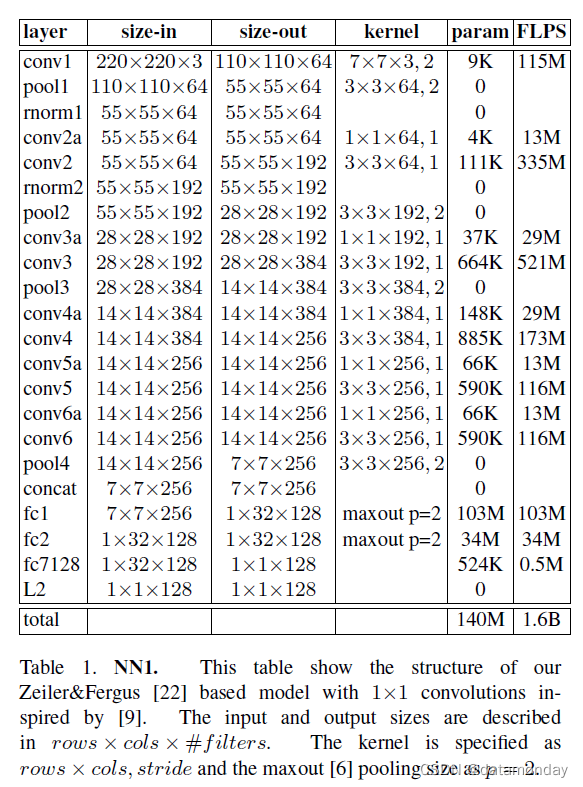
第一类,如表 1 所示,在 Zeiler&Fergus [22] 架构的标准卷积层之间添加 1×1×d 卷积层,如 [9] 中所建议的那样,并产生 22 层深的模型。它共有 1.4 亿个参数,每张图像需要大约 16 亿次 FLOPS。
我们使用的第二类是基于 GoogLeNet 风格的 Inception 模型 [16]。这些模型的参数减少了 20 倍(大约 6.6M-7.5M),FLOPS 减少了 5 倍(在 500M-1.6B 之间)。其中一些模型的尺寸(深度和过滤器数量)显著减小,因此它们可以在手机上运行。
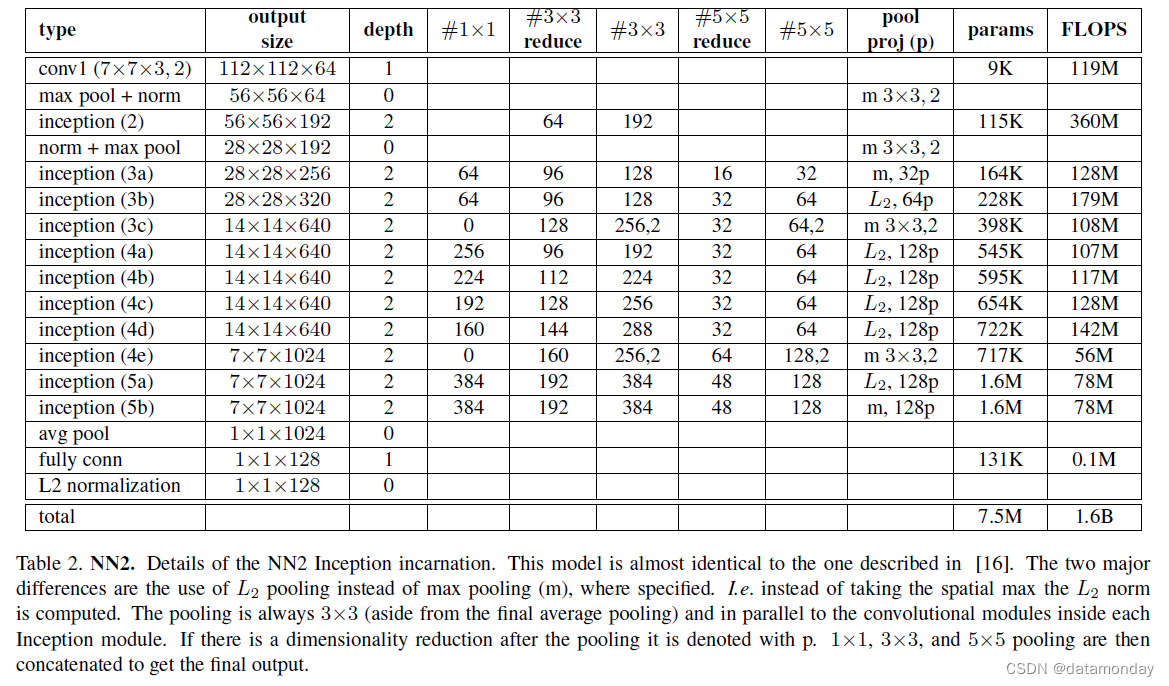
NNS1,有 26M 参数,每张图像只需要 220M FLOPS。
NNS2,有 4.3M 参数和 20M FLOPS。表 2 详细描述了我们最大的网络 NN2。
NN3 在架构上是相同的,但输入大小减少了 160x160。
NN4 的输入大小仅为 96x96,从而大大降低了 CPU 需求(285M FLOPS 与 NN2 的 1.6B)。除了减小输入大小之外,它在较高层中不使用 5x5 卷积,因为那时感受野已经太小了。一般来说,我们发现 5x5 卷积可以在整个过程中被移除,而准确度只会略有下降。图 4 比较了我们所有的模型。
4. Datasets and Evaluation
我们在四个数据集上评估我们的方法,除了野外的 Labeled Faces 和 YouTube Faces,我们在人脸验证任务上评估我们的方法。例如,给定一对两张人脸图像,使用平方 L2 距离阈值 D(xi, xj) 来确定相同和不同的分类。所有具有相同身份的人脸对 (i, j) 用 Psame 表示,而所有不同身份的人脸对用 Pdiff 表示。
我们将所有**真实接受(true accepts)**的集合定义为
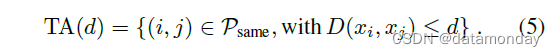
这些是在阈值 d 被正确分类为相同的人脸对 (i, j)。相似地
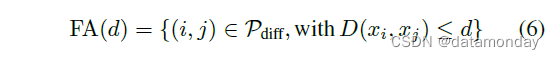
是被错误分类为相同(错误接受)的所有对的集合。
给定人脸距离 d 的验证率 VAL(d) 和错误接受率 FAR(d) 定义为
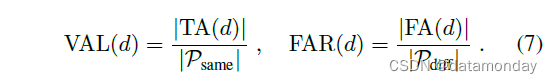
4.1. Hold-out Test Set
我们保留了一组大约一百万张图像,与我们的训练集具有相同的分布,但身份不相交。为了评估,我们将其分成五组不相交的图像,每组 20 万张图像。然后在 100k × 100k 图像对上计算 FAR 和 VAL 率。在五个拆分中报告标准误差。
4.2. Personal Photos
这是一个与我们的训练集分布相似的测试集,但经过人工验证,标签非常清晰。它由三个个人照片集组成,共有约 12k 张图像。我们计算所有 12k 平方图像对的 FAR 和 VAL 率。
4.3. Academic Datasets
Labeled Faces in the Wild (LFW) 是用于人脸验证的事实上的学术测试集 [7]。我们遵循不受限制的、标记的外部数据的标准协议,并报告平均分类准确度以及平均值的标准误差。
Youtube Faces DB [21] 是一个在人脸识别社区 [17, 15] 中广受欢迎的新数据集。该设置类似于 LFW,但不是验证成对的图像,而是使用成对的视频。
5. Experiments
如果没有另外提及,我们会使用 100M-200M 的训练人脸缩略图,其中包含大约 8M 不同的身份。在每个图像上运行一个人脸检测器,并在每个人脸周围生成一个紧密的边界框。这些人脸缩略图的大小被调整为相应网络的输入大小。在我们的实验中,输入尺寸范围从 96x96 像素到 224x224 像素。
5.1. Computation Accuracy Trade-off
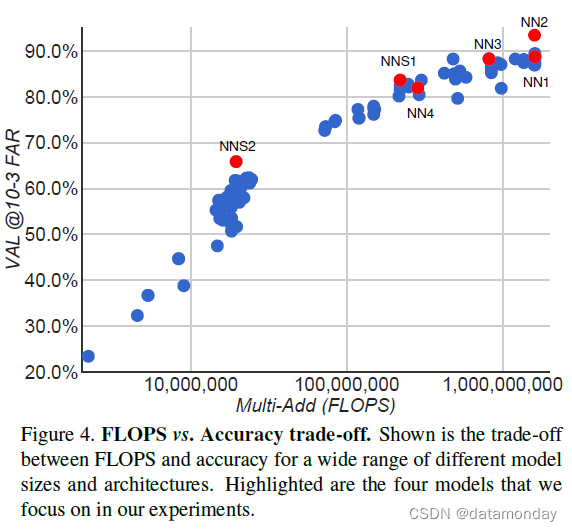
在深入了解更具体实验的细节之前,我们将讨论特定模型所需的准确性与 FLOPS 数量之间的权衡。图 4 显示了 x 轴上的 FLOPS 和 0.001 错误接受率 (F AR) 在我们的用户标记的测试数据集(第 4.2 节)上的准确度。有趣的是,模型所需的计算量与其所达到的准确度之间存在很强的相关性。该图突出显示了我们在实验中更详细讨论的五个模型(NN1、NN2、NN3、NNS1、NNS2)。
我们还研究了关于模型参数数量的准确性权衡。但是,在这种情况下,情况并不那么清晰。例如,基于 Inception 的模型 NN2 实现了与 NN1 相当的性能,但只有 20th 的参数。不过,FLOPS 的数量是可比的。显然,如果参数数量进一步减少,性能预计会下降。其他模型架构可能允许进一步减少而不损失准确性,就像 Inception [16] 在这种情况下所做的那样。
5.2. Effect of CNN Model
我们现在更详细地讨论我们选择的四个模型的性能。一方面,我们有基于 Zeiler&Fergus 的传统架构,具有 1×1 卷积 [22, 9](见表 1)。另一方面,我们有基于 Inception [16] 的模型,可以显着减小模型大小。总体而言,在最终性能中,两种架构的顶级模型的性能相当。然而,我们的一些基于 Inception 的模型,例如 NN3,仍然取得了良好的性能,同时显着降低了 FLOPS 和模型大小。
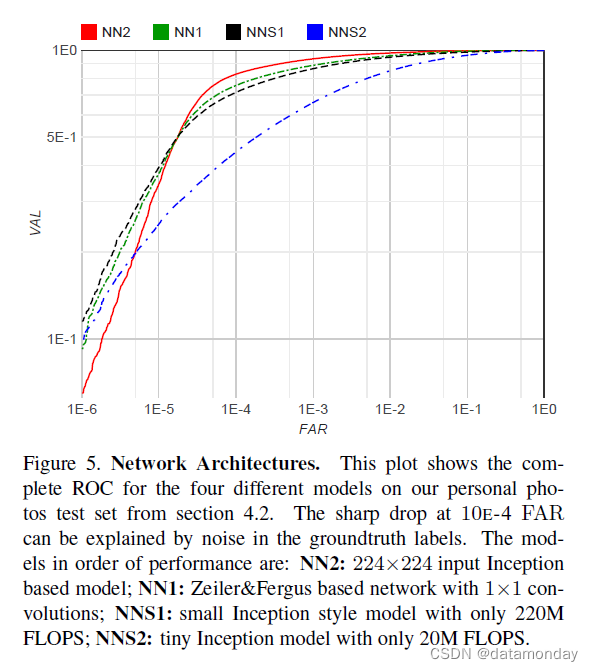
我们的个人照片测试集的详细评估如图 5 所示。虽然最大的模型与微型 NNS2 相比在精度上取得了显着提升,但后者在手机上可以运行 30ms/张,仍然足够精确到用于人脸聚类。 FAR < 10-4 的 ROC 急剧下降表明测试数据中的标签有噪声。在极低的错误接受率下,单个错误标记的图像可能会对曲线产生重大影响。
5.3. Sensitivity to Image Quality
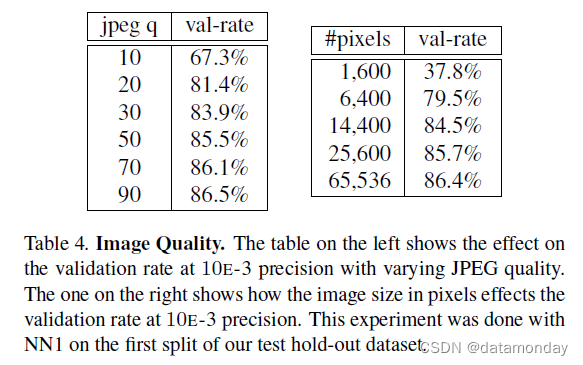
表 4 显示了我们的模型在各种图像尺寸下的鲁棒性。该网络在 JPEG 压缩方面出人意料地强大,并且在 JPEG 质量为 20 时表现得非常好。对于尺寸为 120x120 像素的人脸缩略图,性能下降非常小,即使在 80x80 像素时,它也显示出可接受的性能。这是值得注意的,因为该网络是在 220x220 输入图像上训练的。用较低分辨率的人脸训练可以进一步提高这个范围。
5.4. Embedding Dimensionality
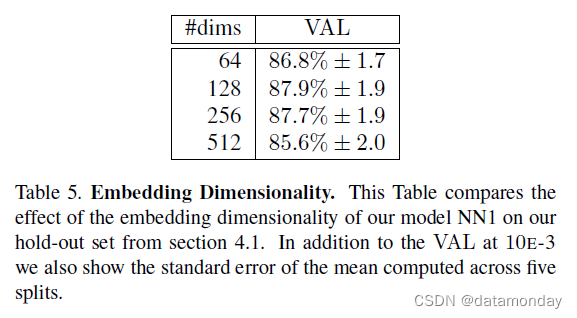
除了表 5 中报告的比较之外,我们探索了各种嵌入维度并为所有实验选择了 128 个。人们期望较大的嵌入至少与较小的嵌入一样好,但是,它们可能需要更多的训练才能实现相同的准确性。也就是说,表 5 中报告的性能差异在统计上并不显著。需要注意的是,在训练过程中使用了 128 维浮点向量,但它可以量化为 128 字节而不会损失精度。因此,每个人脸都由一个 128 维字节向量紧凑地表示,这是大规模聚类和识别的理想选择。较小的嵌入是可能的,但精度损失很小,并且可以在移动设备上使用。
5.5. Amount of Training Data
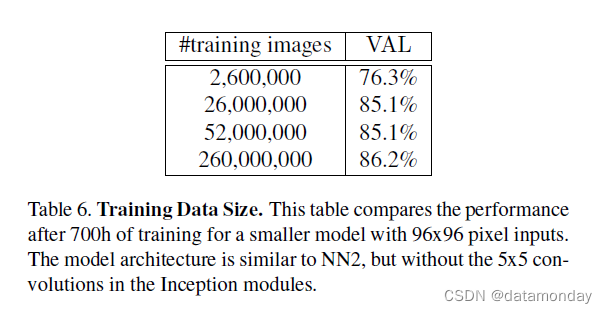
表 6 显示了大量训练数据的影响。由于时间限制,此评估在较小的模型上运行;在更大的模型上效果可能更大。很明显,使用数以千万计的样本可以明显提高第 4.2 节中我们的个人照片测试集的准确性。与仅数百万张图像相比,误差相对减少了 60%。使用另一个数量级的更多图像(数亿)仍然会带来小幅提升,但改进会逐渐减弱。
5.6. Performance on LFW
我们使用标准协议评估我们在 LFW 上的模型,用于不受限制的、标记的外部数据。九个训练分割用于选择 L2 距离阈值。然后在第十个测试拆分上执行分类(相同或不同)。对于除八分之一 (1.256) 之外的所有测试拆分,选定的最佳阈值为 1.242。
我们的模型以两种模式进行评估: 1. LFW 提供的缩略图的固定中心裁剪。 2. 专有的人脸检测器(类似于 Picasa [3])在提供的 LFW 缩略图上运行。如果它未能对齐人脸(这发生在两个图像上),则使用 LFW 对齐。

图 6 给出了所有失败案例的概览。它在顶部显示错误接受,在底部显示错误拒绝。当使用 (1) 中描述的固定中心裁剪时,我们实现了 98.87%±0.15 的分类准确度,而在使用额外人脸对齐 (2) 时,我们达到了打破平均标准误差的 99.63%±0.09 的记录。这将 [17] 中 DeepFace 报告的错误减少了 7 倍以上,并且将 [15] 中 DeepId2+ 报告的先前最先进技术减少了 30%。这是模型 NN1 的性能,但即使是更小的 NN3 也能实现在统计上没有显著差异的性能。
5.7. Performance on Youtube Faces DB
我们使用人脸检测器在每个视频中检测到的前一百帧的所有对的平均相似度。这为我们提供了 95.12%±0.39 的分类准确率。使用前一千帧的结果是 95.18%。与同样评估每个视频一百帧的 [17] 91.4% 相比,我们将错误率降低了近一半。 DeepId2+ [15] 达到了 93.2%,我们的方法将此误差降低了 30%,与我们对 LFW 的改进相当。
5.8. Face Clustering

我们紧凑的嵌入有助于将用户的个人照片聚集到具有相同身份的人群中。与纯验证任务相比,人脸聚类所施加的分配约束,导致真正惊人的结果。图 7 显示了用户个人照片集中的一个集群,它是使用凝聚聚类生成的。它清楚地展示了对遮挡、光照、姿势甚至年龄的难以置信的不变性。
6. Summary
我们提供了一种直接学习嵌入到欧几里得空间中进行人脸验证的方法。这使它与其他使用 CNN 瓶颈层或需要额外后处理(例如多个模型和 PCA 的串联)以及 SVM 分类的方法 [15、17] 不同。我们的端到端培训既简化了设置,又表明直接优化与手头任务相关的损失可以提高性能。
我们模型的另一个优点是它只需要最小的对齐(人脸区域周围的紧密裁剪)。 [17],例如,执行复杂的 3D 对齐。我们还尝试了相似变换对齐,并注意到这实际上可以稍微提高性能。目前尚不清楚是否值得额外的复杂性。
未来的工作将集中在更好地理解错误情况,进一步改进模型,以及减少模型大小和降低 CPU 需求。我们还将研究改善目前极长的训练时间的方法,例如我们的课程学习变体,批量较小,离线以及在线正负挖掘。
7. Appendix: Harmonic Embedding
在本节中,我们介绍谐波嵌入的概念。我们由此表示一组嵌入,它们由不同的模型 v1 和 v2 生成,但在可以相互比较的意义上是兼容的。
这种兼容性极大地简化了升级路径。例如。在跨大量图像计算嵌入 v1 并且正在推出新的嵌入模型 v2 的场景中,这种兼容性可确保平稳过渡,而无需担心版本不兼容。图 8 显示了我们的 3G 数据集的结果。可以看出,改进后的模型 NN2 明显优于 NN1,而 NN2 嵌入与 NN1 嵌入的比较表现处于中等水平。
7.1. Harmonic Triplet Loss
为了学习谐波嵌入,我们将 v1 的嵌入与正在学习的嵌入 v2 混合在一起。这是在三元组损失中完成的,并导致额外生成的三元组鼓励不同嵌入版本之间的兼容性。图 9 可视化了导致三元组损失的三元组的不同组合。
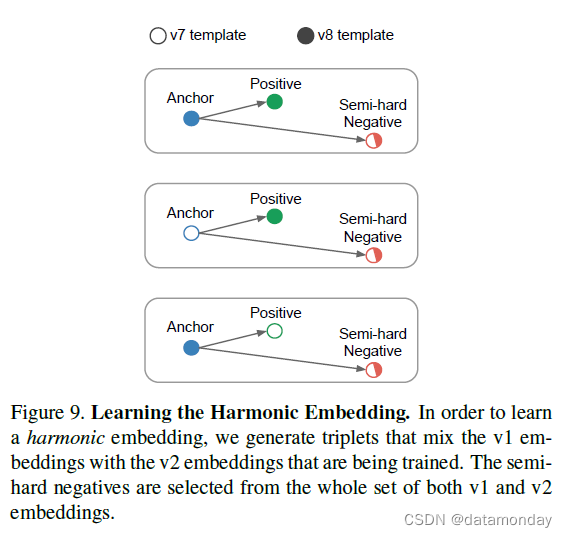
我们从独立训练的 NN2 初始化 v2 嵌入,并从随机初始化中重新训练最后一层(嵌入层),兼容性鼓励三元组损失。首先只对最后一层进行再训练,然后我们继续使用谐波损失训练整个 v2 网络。

图 10 显示了这种兼容性在实践中如何工作的可能解释。绝大多数 v2 嵌入可能嵌入在相应的 v1 嵌入附近,但是,错误放置的 v1 嵌入可能会受到轻微干扰,因此它们在嵌入空间中的新位置会提高验证准确性。
7.2. Summary
这些都是非常有趣的发现,它运行得如此之好有点令人惊讶。未来的工作可以探索这个想法可以扩展到多远。据推测,v2 嵌入可以在 v1 上改进多少,同时仍然兼容。此外,训练可以在手机上运行并与更大的服务器端模型兼容的小型网络会很有趣。
















 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











