





前言
生成式对抗网络(GAN)是近几年深度学习领域比较热门的话题之一。我的本科毕业设计(用宋体字符图像生成新字体,保证新字体图像接近于宋体。)就是以GAN为核心展开的。实现过程中,我在网上查阅了很多资料,本篇文章也是我学习的一个总结,也是我毕业论文的摘选。内容主要来源于博客论坛、李宏毅教授的教学课程和GAN最原始的paper。
1.介绍
生成对抗网络(Generative Adversarial Network,简称GAN)是无监督学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法由Ian J.Goodfellow等人于2014年提出。一经提出就在无监督学习领域掀起了一股热潮,自2014年来与GAN相关论文数目每年呈指数性增长,并且目前已经有许多研究者利用GAN在某些特定领域取得了不错的进展。2018年图灵奖得主同时也是深度学习领域的著名学者Yann Lecun多次给予了GAN高度评价。
生成式对抗网络由生成器和判别器构成。生成对抗网络的核心目的是训练生成器。生成器的目的是生成与真实样本尽可能相似的“假样本”,判别器的目的是尽可能区分出给定样本是真实样本还是生成的“假样本”。二者目的相悖,在不断博弈的过程中相互提高,最终在判别器判别能力足够可靠的前提下仍无法区分给定样本是真实样本还是生成样本,从而我们说生成器能够生成“以假乱真”的样本。
为了作直观的解释,下面举一个较为形象的例子。枯叶蝶的祖先原本也是五彩斑斓的蝴蝶,然而色彩鲜艳也导致了很容易被它的天敌麻雀发现,为了躲避天敌,枯叶蝶在不断的“物竞天择”的过程中身体颜色进化为与枯叶一样的褐色。然而这样也迫使麻雀进化,麻雀能够根据是否具有树叶纹理判断枯叶蝶的存在。于是在这样一次又一次的进化中,最终枯叶蝶具有了与枯叶极为相似的外形。图2.1和图2.2更直观的展示了这一过程。


在实际运用中,生成器和判别器一般是两个神经网络。对于真实样本z,通过生成网络G我们得到生成样本G(z)。对于判别网络D,给定输入样本,给出该样本是真实样本的概率(介于0-1之间)。对于z我们希望D(z)≈1。而对于生成样本G(z),我们希望D(G(z))≈0。可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5。也就是说,最终生成器不能区分真实样本和生成样本,而生成样本与真实样本相似。
2.样本空间与概率分布
为了更好的理解,先举一个较为简单的例子。假设工厂生产了某一型号的零件N件,对于每一个零件我们要求它的尺寸是x,由于各种原因,这些生产出来的零件在尺寸上不可避免的会存在一些误差,使得真实生产的零件尺寸并非都是x。我们以零件的尺寸作为横轴以该尺寸出现的概率作为纵轴,给出N件零件尺寸的概率分布图。如图2.3所示。
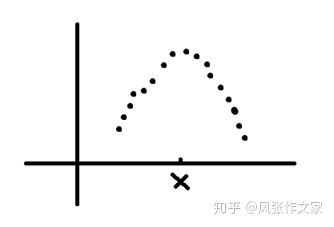
从图2.3我们能够看到,对于大多数零件,它们的尺寸分布在x周围。有人可能会产生质疑,一定是这样的吗?其实我们从现实经验得知,在大多数情况下,这个概率分布图都是一条近似于抛物线的形状。不只是对于这一案例,例如某一区域所有人身高的概率分布图,某一次考试所有考生成绩的概率分布图等等,都服从一条类似于抛物线的分布。不夸张地说,这是一种自然现象。对于这种现象,伟大的数学家高斯早已给出了定义和数学证明,即正态分布。
深度学习的目的是找出一个复杂、具有层次结构的模型,用这个模型来表示诸如图像、音频、自然语言等人工智能应用的概率分布。(这是GAN论文中给出的。换一句话说,一个深度学习的模型就是一个概率分布,训练深度学习模型的过程等价于寻找高维空间上的一个概率分布。)
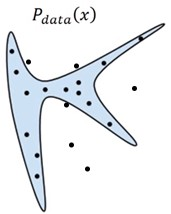
采用生成字体这一事例,将上述结论拓展开来。对于某一种字体,如宋体,现在我们得到一组宋体字的图像,我们希望生成一种类似于宋体的新字体(一组字符图像)。现在假设这组图像大小均为m*n,那么对于每一张图像可以理解为m*n维空间上的一个“点”。我们给出宋体在这个m*n维空间上的概率分布,用这个概率分布去估计生成字体与宋体的差异,通过最大化这个估计值(最大似然估计,见2.1.2)我们得到生成字体的概率分布(深度学习模型),这个概率分布近似于宋体的概率分布(当生成字体的概率分布近似于宋体的概率分布,就能够用深度学习模型生成近似于宋体的新字体),那么我们便得到了一种新字体的生成方法。如图2.4所示,我们将宋体的概率分布抽象到二维平面,图2.4中的蓝色区域中所有的点表示宋体字符,蓝色区域边缘的点表示与宋体相近的字符,距离蓝色区域较远的点表示非宋体字符。
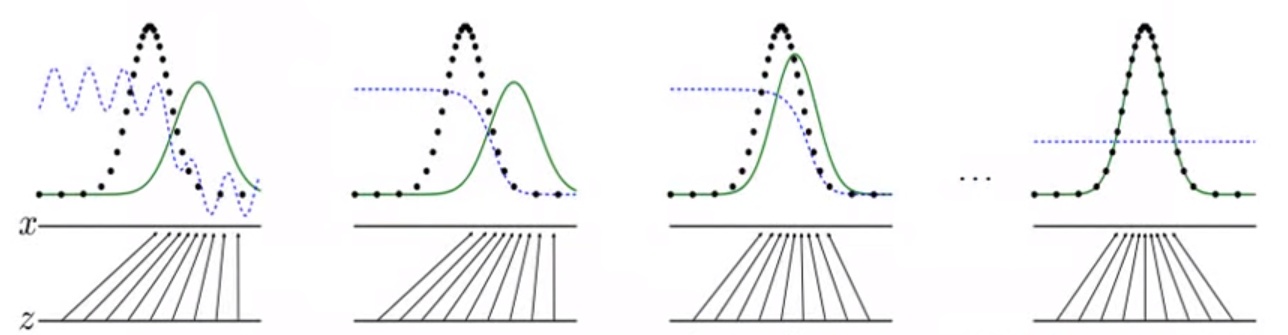
进一步的,我们用上述结论解释生成对抗网络(GAN)的原理。如图2.5所示,黑色虚线表示宋体的概率分布,绿色实线表示生成字体的概率分布,蓝色虚线表示判别器,判别器值越大表示越接近宋体,z所在的水平线表示生成字体。生成器的每一次迭代使生成字体的s概率分布更接近于宋体,判别器的每一次迭代为了更好的区分这两个概率分布。最终,生成字体的概率分布与宋体的概率分布“重合”,表示生成器已经能够生成近似宋体的新字体。
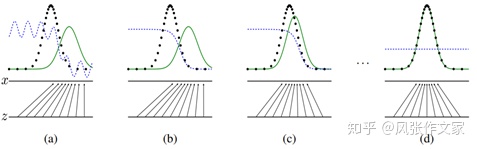
实际上,对于宋体在高维空间上的概率分布我们很难得到,但是利用生成对抗网络依然能够达到上述的效果,这也正是生成对抗网络的优势所在。在下面的章节会继续介绍如何用生成对抗网络使生成字体的概率分布接近于宋体的概率分布。
3.最大似然估计
最大似然估计就是利用已知的样本结果信息,反推出最大可能导致这些样本结果出现的模型参数。在2.1.1已经提到,深度学习的模型即概率分布。而确定一个模型,也就是确定模型的结构和参数θ。假设现在有一个生成模型和一批初始化的参数θ,也就是任意给定一个多维空间上的概率分布,用这个生成模型来表示生成字体的概率分布。为了使模型生成与宋体相似的新字体,我们通过不断优化参数θ使模型不断更新,使模型生成的字体服从宋体的概率分布,也就是说生成字体的概率分布与宋体的概率分布相似(这个过程就叫做最大似然估计)。
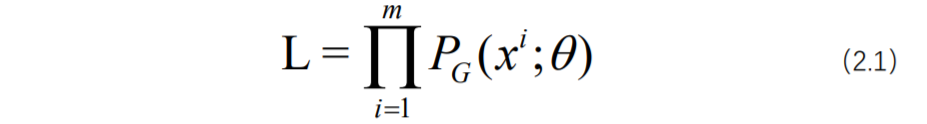
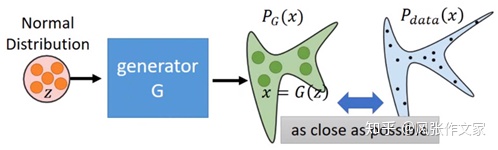
我们采用最大似然估计实现这一目的。同样在2.1.1提到,假设我们已知宋体的概率分布P_data(x),我们的目的是使新字体的概率分布P_g(x;θ)≈P_data(x)。如式(2.1)所示,其中,P_g(x;θ)表示由参数θ确定的生成模型表示的概率分布。最大化式(2.1)优化参数θ,得到最终的生成模型,也就是生成字体的概率分布。这个过程如图2.6所示,真实样本的概率分布分布可以服从一个混合高斯模型或者其它任意模型,我们只需要使P_g(x;θ)≈P_data(x),这样当生成样本的分布接近于真实样本的分布,那么我们便可以利用生成模型来生成足够“以假乱真”的新字体(来自李宏毅教授的视频课程)。
4.理论推导
在2.1.1提到,实际上宋体的概率分布我们很难得到,生成对抗网络(GAN)为此提供了解决方案。式(2.2)的推导证明,最大似然估计法可以等价为最小化KL Divergence。用KL Divergence来衡量真实样本的概率分布和生成样本的概率分布的差异,因此通过最小化KL Divergence优化生成模型的参数θ,能够确定生成模型。

于是对于生成模型我们的任务转换为最小化真实样本的概率分布和生成样本的概率分布之间的Divergence。前面提到,真实样本的概率分布我们很难得到,同样生成样本的概率分布我们也无从得知。对于生成样本的概率分布,我们用生成模型来表示,而对于真实样本的概率分布,我们从真实样本sample出m个数据,用这m个数据拟合真实样本的概率分布,这样我们就近似的得到了真实样本的概率分布。
对于判别模型,我们希望尽可能区分目标样本是真实样本还是生成样本,实际上判别模型的目标是在高维空间中找出一个高维“平面”,用这个“平面”分割真实样本的分布和生成样本的分布,从而区分真实样本和生成样本。式(2.4)采用log-likelihood描述真实样本分布和生成样本分布间的差异,通过最大化V(D,G)使判别模型达到最优的判别效果。同样可以最小化V(D,G)优化生成模型的生成效果。(公式不好输入,用图片显示。PDF乱码,方框是~。)

们可以说生成器生成了“以假乱真”的样本。
在实际应用中,生成模型和判别模型的训练是分步进行的。通常使判别模型迭代K次、生成模型迭代1次,依此交替进行,对于判别模型,我们使其保持局部最优状态。一般的,在最初期需要对判别模型进行与训练,使其在一开始就有一定的判别能力。
生成式对抗网络的厉害之处不是提出了一个对抗的思想,它的厉害之处是从理论上证明了对于任意的函数G和D(一般神经网络),都存在唯一的最优解使得D=0.5,而此时生成网络能够生成与真实样本相似的生成样本。但是在实际运用过程中是很难操控这个过程的,其实目前来说我是达不到这种水平的,我的毕设是借鉴的GitHub上zi2zi这个模型。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









