





在本文中,我将解释主要用于超参数调优的K- fold 交叉验证。交叉验证是一种评估预测机器学习模型的技术,它将原始样本分为训练模型的训练集和评估模型的测试集。我将逐步解释k折交叉验证。
- 将数据集拆分为k个相等的分区
- 使用第一个fold为测试数据,将其他folds的并集作为训练数据,并计算测试精度
- 重复步骤1和步骤2。如果我们把数据集分成k个folds。在第一次迭代中,第一个fold将是测试数据,其余的并集将是训练数据。然后我们将计算测试准确度。然后在下一次迭代中,第二个fold将是测试数据,其余的并集将是训练数据。我们将对所有folds做类似处理。
- 将这些测试准确度的平均值作为样本的准确度。
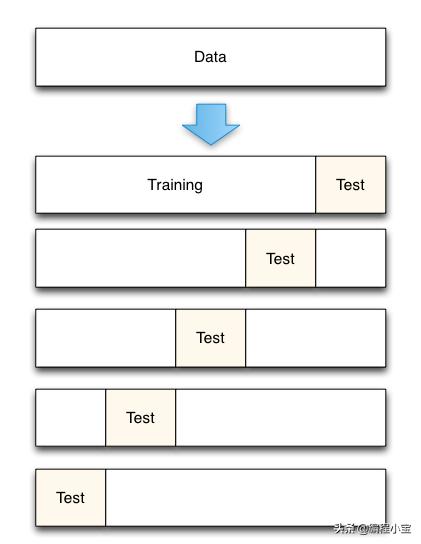
现在您已了解K-fold交叉验证的工作原理。我们对K采取的典型值是10,即10 fold交叉验证。现在我将解释我们将如何进行k -fold cross validation来确定k-最近邻中的k(no of neighbour)。(注:k最近邻中的k与k-fold交叉验证中的k不同)
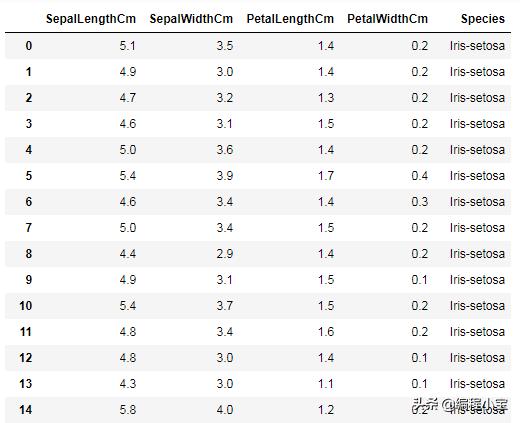
sklearn完美地实现了cross_val_score来解决我们的问题。它只有几行代码。我们将用著名的iris数据集进行尝试。我们的数据如下所示。我们必须根据现有的数据来确定这种花属于哪一种。
#importing necessary modulesimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport pandas as pd#splitting into train and test datafrom sklearn.cross_validation import train_test_splitX = data.iloc[:, :-1]y = data.iloc[:, -1]X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)#fitting k-nearest neighbours algorithmfrom sklearn.neighbors import KNeighborsClassifierknn1 = KNeighborsClassifier(n_neighbors=3)knn1.fit(X_train,y_train)y_pred = knn1.predict(X_test)#calculating accuracyfrom sklearn.metrics import accuracy_scoreprint('Acuuracy score is {}'.format(accuracy_score(y_test, y_pred)))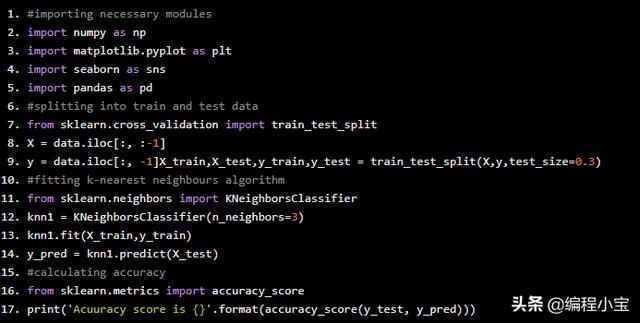
Acuuracy score is 0.9555555555555556
我们得到了大约95%的准确率。但是在测试数据上表现良好的机器学习模型不一定在新数据上表现良好。我们已经确定了最佳K值,我们可以使用交叉验证。这里我们将进行10 fold交叉验证。
from sklearn.model_selection import cross_val_score#hyper parameter tuning.Selecting best Kneighbors = [x for x in range(1,50) if x % 2 != 0]# empty list that will hold cv scorescv_scores = []for k in neighbors: knn = KNeighborsClassifier(n_neighbors=k) scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') cv_scores.append(scores.mean())#graphical view#misclassification errorMSE = [1-x for x in cv_scores]#optimal Koptimal_k_index = MSE.index(min(MSE))optimal_k = neighbors[optimal_k_index]print(optimal_k)# plot misclassification error vs kplt.plot(neighbors, MSE)plt.xlabel('Number of Neighbors K')plt.ylabel('Misclassification Error')plt.show()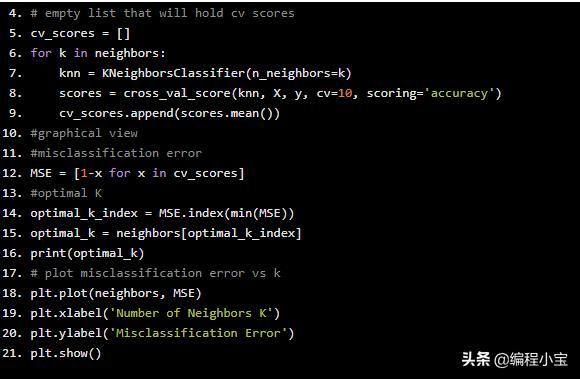
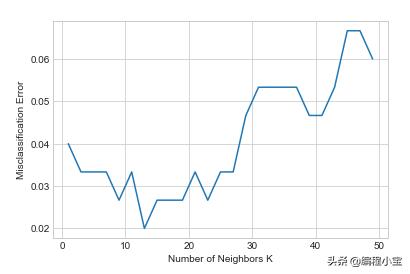
因此,k最近邻的最佳k值是k = 13.因此,我们可以基于此训练机器学习模型
knn = KNeighborsClassifier(n_neighbors=13)knn.fit(X_train,y_train)y_pred = knn1.predict(X_test)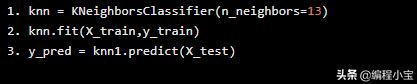














 1314
1314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









