






2. 前端性能优化实战
2.1 延迟渲染
通常为了加快页面渲染的速度,基础的解决思路是,通过去除页面上除首屏以外的对于用户不可见的信息区块,让页面的DOM节点数更少,DOM树结构更简单,从而达到加快页面下载和渲染速度的目的。
然后使用懒加载异步化请求、BigPipe等方案,动态加载这些不可见的信息区块。
2.1.1 挑战和困难
有些页面是网站重要的主流程页面,承担搜索功能的搜索结果列表页面,主体部分不能使用异步化请求进行懒加载。
在很多电商网站中,搜索页面的结构通常会包含两大主体搜索结果内容,左栏一般为关联产品搜索结果的类目数据,右栏为搜索结果数据。
对于页面的首屏来说它包含了两部分,通常这两部分数据都来自于两次独立的数据查询的结果。如果使用异步化请求分割右栏的搜索结果列表,当单页请求结果数为50时,首屏展示区域为3条结果。
这种请求方式对于服务端搜索引擎分页处理系统来说是个挑战,而且一次搜索结果分两次请求获取,对服务器的资源也是很大的浪费。
表面上页面通过这样的分割,可以达到减少DOM树节点数、简化DOM树结构的目的,但考虑到服务器所付出的代价,这无疑是得不偿失的。
2.1.2 解决方案
在编写HTML和样式的时候,尽量精简结构,并且要避免通过滥用样式选择器得到高效的CSS Selector。
减小页面首次渲染时的DOM树节点数,并且在不修改服务端输出逻辑的前提下进行。
假设完整的搜索结果页面包含36个搜索结果,其中首屏展示的部分包含3个结果,首屏以下不可见部分则为剩下的33个结果:
使用TextArea来存放首屏以下的33个搜索结果对应的HTML代码,浏览器会解析识别为TextArea内容,而不会被当作DOM节点进行解析。
在服务端,将一些特殊字符(比如&)进行HTMLEncode转义;在浏览器端,需要在首屏以下区域处于可见状态时,将TextArea中的HTML代码取出,将其恢复到DOM树中进行渲染。
本书作者将这个方案称为“延迟渲染”。
2.2 SEO Ajax
对于面向海外用户的网站,会和Google有很多交集,特别是在Google SEO的流量导流优化方面。
2.2.1 挑战和困难
针对SEO页面的性能优化,遇到的问题:
1)针对爬虫爬取收录的页面,页面内容必须同步展示;
2)HTML代码和实际展现的内容要保证一定程度的一致性,否则有被认作作弊页面的风险。
在同步展示的要求上面,服务端要在一次请求过程中,把整个页面所有的内容都计算完毕,这就导致了页面在服务端的响应会消耗很多时间。
同时一致性的要求,使得在浏览器端方面,我们也不能轻举妄动,极大地限制了各种优化方案的使用。
2.2.2 解决方案
Google官方提供了一个称为Ajax crawlable scheme的Ajax爬行方案,是Google为了帮助爬虫抓取网络上越来越多的富应用页面产生的内容。
简单地说,爬虫在页面中发现pretty Ajax URL(基于约定,URL中包括一个“#!”这样的锚点),会对这个URL做简单的修改,来表名意图--抓取快照,然后请求服务器,服务器返回一个包含全部内容的页面快照,由爬虫进行处理,而在搜索引擎结果中,只会展示原先的pretty Ajax URL。
在实际方案运用中,有两种不同的实现方法:
1)通过改造URL;
2)通过页面meta标签。
如果Google提供的方案可行,它将会带来很大价值:
1)可以放心使用Ajax异步化方案,而不用担心影响SEO;
2)可以基于此方案,进行更深入的前台和后台优化;
3)采用此方案后,针对终端用户的响应和爬虫的抓取响应,可以在后台架构上做分离。针对终端用户,提供实时信息的响应;针对爬虫,提供一定时间缓存版本的响应。
存在风险:
Google官方博客表明,他们会相似地对待采用此类方案的Ajax页面,就像对待其他Web传统页面一样,只获取爬虫通过爬行方案提供的方式抓取到此类Ajax页面的完整内容,但不保证此类页面在搜索结果中的排序,一切取决于内容。
Google没有明确表示网站使用该方案可能产生的影响,如果网站非常依赖Google SEO渠道流量的导流,此部分流量的丢失对网站会有很大影响。
本书作者经过半年的实验,验证了方案的可行性,并且在实验过程中,方案的应用还增加了SEO渠道的流量。
3. 网站性能分析
本章介绍如何借助站外优秀的性能测试工具,以及建立网站自己的真实用户性能监控系统,来测试和监控页面的关键性能指标,从而使我们能够对网站性能问题进行快速分析并做出优化。
3.1 快速了解网站性能
3.1.1 使用YSlow进行性能分析
YSlow性能检测插件(以Firefox插件的形式),遵守基于所有基础的性能最佳实践的规则,快速分析HTML文档代码组成。
Steve Souders在《高性能网站建设指南》一书中总结了12条基本规则:
1)尽量减少HTTP请求;
2)使用CDN;
3)静态资源使用Cache;
4)启用Gzip压缩;
5)JavaScript脚本尽量放在页面底部;
6)CSS样式表放在顶部;
7)避免CSS表达式;
8)减少内联JavaScript和CSS的使用,尽可能使用外部的JavaScript和CSS文件;
9)减少DNS查询;
10)精简JavaScript;
11)避免重定向;
12)删除重复的脚本。
一个页面如果遵守了以上规则进行前端开发,抛开网络因素,至少可以保证它在页面加载阶段的性能不会产生问题。
这些实践规则,基本上将焦点放在了页面的加载阶段,在加载完成后的浏览器的解析、渲染阶段是空白的。
3.1.2 使用PageSpeed进行性能分析
Google提供的优化工具PageSpeed除了有网站的入口,也能够以插件形式在Firefox和Chrome浏览器上运行。
它的工作原理类似于YSlow,也是基于一些基础的性能最佳实践规则来分析代码,然后提供一系列能够提高页面性能的优化方案建议。
PageSpeed除了能够提供页面在请求加载层面的优化建议,还能提供页面在加载完成后的一系列解析渲染操作的各部分时间,比如:
1)页面包含的JavaScript代码的执行时间;
2)合理高效的CSS样式代码的建议;
3)页面布局渲染的时间等。
3.1.3 使用WebPagetest进行性能分析
和YSlow、PageSpeed一样,WebPagetest也使用和它们相似的一组最佳性能实践来分析网页。
WebPagetest通过浏览器访问,基于输入的Website URL,以及选择的国家城市、浏览器类型、网络带宽等信息,启动对应的远程服务器上的浏览器进行性能分析测试。
WebPagetest能够提供遍布世界各个角落的代表性城市的页面性能分析测试,基本覆盖亚洲、大洋洲、非洲、欧洲、北美和南美洲。
除了常规的性能分析及优化建议,WebPagetest还提供了页面加载过程的视频录制、关键节点截图、页面加载瀑布图等诸多重要信息。
缺点:
1)WebPagetest很难对登录态依赖Cookie的网页进行测试,基本上无法为测试页面设置正确的Cookie;
2)WebPagetest上的性能测试服务是由人工触发的。
每一次测试服务,都是在特定地区的特定机器上启动特定浏览器进行性能分析,分析的结果只能作为排查某个国家用户访问性能问题时的一个性能报告参考,并不能真正代表访问网站的真实用户的性能体验。
3.2 真实用户前端性能监控
建立一个基础的真实用户前端性能监控系统,大致包含以下5个系统模块的设计开发工作:
1)真实用户前端性能数据采集;
2)采集数据存储;
3)监控系统指标定义及加工计算;
4)数据分析、性能报表产出;
5)性能基线定义。
3.2.1 真实用户前端性能数据采集
1)终端环境数据
(1)设备信息,用于区分PC、Mobile、平板等不同设备;
(2)操作系统;
(3)浏览器;
(4)地区/国家等。
2)基础性能指标数据
网络相关时间:
(1)页面域名解析时间(DNS Lookup Time);
(2)TCP建立连接时间(TCP Connection Time);
(3)HTML文档下载时间(HTML Download Time);
浏览器端渲染相关时间:
(1)页面开始渲染时间,即白屏等待时间(StartRender Time);
(2)文档对象模型准备时间(DOM Ready Time);
(3)页面加载完成时间(Page Load Time)。
3)页面资源加载详细数据
页面加载包含的IMG、JS、CSS资源的时间消耗数据。
3.2.2 数据采集可行性分析
1)终端环境数据采集分析
通常终端环境的数据通过浏览器的DOM API提供的navigator.userAgent属性可以获取。这个属性声明了浏览器用于发送HTTP请求的用户代理头的值。
通过解析日志请求中的HTTP Request Header的IP信息,在后期通过相关IP库拿到对应的地区或者国家信息。
2)页面性能数据采集分析
基于H5 Performance Timing API,收集页面的基础性能信息,主要包含3个部分:
(1)Navigation Timing:主要提供页面加载过程的性能数据;
(2)Resource Timing:主要提供页面所包含的脚本、样式表、图片等资源加载的性能数据;
(3)User Timing:方便为在复杂脚本内部记录不同代码片段的执行时间提供API实现。
3)页面性能数据加工计算
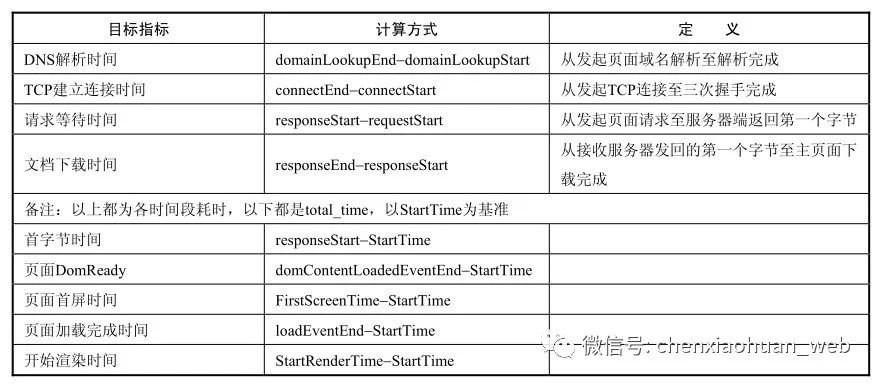
从浏览器获取原始的性能数据后,开始对数据进行加工计算,来映射前面定义的和用户体验相关的各种体验指标:
(1)StartTime基准计算
如果NavigationStart不为0,则使用NavigationStart作为页面StartTime基数;如果为0,则降级使用FetchStart;如果FetchStart还是0,则将考虑此数据作废。
(2)其他指标加工计算准则
4)系统报表简介
常规性能监控系统的常规设计:
(1)基于不同的设备(区分终端),来自手持设备还是PC等;
(2)基于不同国家,不同国家中的不同地区等;
(3)基于不同类型的用户群体。
然后基于上面不同维度、不同组合的需求,对数据进行聚合计算,并最终用于图标展示。
常规可视化图表设计:
(1)性能数据汇总概括;
(2)变化趋势;
(3)分布区间、直方图等;
(4)基于页面的瀑布图绘制(可基于最新的Resource Timing提供的数据进行绘制)。















 1043
1043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









