






Kaggle电影数据分析实战
本项目基于Kaggle电影影评数据集,通过这个系列,你将学到如何进行数据探索性分析(EDA),学会使用数据分析利器pandas,会用绘图包pyecharts,以及EDA时可能遇到的各种实际问题及一些处理技巧。
通过这个小项目,大家将会掌握pandas主要常用函数的使用技巧,matplotlib绘制直方图,和pyecharts使用逻辑,具体以下13个知识点:
1 创建DataFrame,转换长数据为宽数据;2 导入数据;3 处理组合值;4 索引列;5 连接两个表;6 按列筛选;
7 按照字段分组; 8 按照字段排序; 9 分组后使用聚合函数;10 绘制频率分布直方图绘制;11 最小抽样量的计算方法; 12 数据去重; 13 结果分析
注意:这些知识点不是散落的,而是通过求出喜剧电影排行榜,这一个目标主线把它们串联起来。
本项目需要导入的包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pyecharts.charts import Bar,Grid,Line
import pyecharts.options as opts
from pyecharts.globals import ThemeType
1 创建DataFrame
pandas中一个dataFrame实例:
Out[89]:
a val
0 apple1 1.0
1 apple2 2.0
2 apple3 3.0
3 apple4 4.0
4 apple5 5.0
我们的目标是变为如下结构:
a apple1 apple2 apple3 apple4 apple5
0 1.0 2.0 3.0 4.0 5.0
乍看可使用pivot,但很难一步到位。
所以另辟蹊径,提供一种简单且好理解的方法:
In [113]: pd.DataFrame(index=[0],columns=df.a,data=dict(zip(df.a,df.val)))
Out[113]:
a apple1 apple2 apple3 apple4 apple5
0 1.0 2.0 3.0 4.0 5.0
以上方法是重新创建一个DataFrame,直接把df.a所有可能取值作为新dataframe的列,index调整为[0],注意类型必须是数组类型(array-like 或者 Index),两个轴确定后,data填充数据域。
In [116]: dict(zip(df.a,df.val))
Out[116]: {'apple1': 1.0, 'apple2': 2.0, 'apple3': 3.0, 'apple4': 4.0, 'apple5': 5.0}
2 导入数据
数据来自kaggle,共包括三个文件:
movies.dat
ratings.dat
users.dat
movies.dat包括三个字段:['Movie ID', 'Movie Title', 'Genre']
使用pandas导入此文件:
import pandas as pd
movies = pd.read_csv('./data/movietweetings/movies.dat', delimiter='::', engine='python', header=None, names = ['Movie ID', 'Movie Title', 'Genre'])
导入后,显示前5行:
Movie ID Movie Title \
0 8 Edison Kinetoscopic Record of a Sneeze (1894)
1 10 La sortie des usines Lumi猫re (1895)
2 12 The Arrival of a Train (1896)
3 25 The Oxford and Cambridge University Boat Race ...
4 91 Le manoir du diable (1896)
5 131 Une nuit terrible (1896)
6 417 Le voyage dans la lune (1902)
7 439 The Great Train Robbery (1903)
8 443 Hiawatha, the Messiah of the Ojibway (1903)
9 628 The Adventures of Dollie (1908)
Genre
0 Documentary|Short
1 Documentary|Short
2 Documentary|Short
3 NaN
4 Short|Horror
5 Short|Comedy|Horror
6 Short|Action|Adventure|Comedy|Fantasy|Sci-Fi
7 Short|Action|Crime|Western
8 NaN
9 Action|Short
次导入其他两个数据文件
users.dat:
users = pd.read_csv('./data/movietweetings/users.dat', delimiter='::', engine='python', header=None, names = ['User ID', 'Twitter ID'])
print(users.head())
结果:
User ID Twitter ID
0 1 397291295
1 2 40501255
2 3 417333257
3 4 138805259
4 5 2452094989
5 6 391774225
6 7 47317010
7 8 84541461
8 9 2445803544
9 10 995885060
rating.data:
ratings = pd.read_csv('./data/movietweetings/ratings.dat', delimiter='::', engine='python', header=None, names = ['User ID', 'Movie ID', 'Rating', 'Rating Timestamp'])
print(ratings.head())
结果:
User ID Movie ID Rating Rating Timestamp
0 1 111161 10 1373234211
1 1 117060 7 1373415231
2 1 120755 6 1373424360
3 1 317919 6 1373495763
4 1 454876 10 1373621125
5 1 790724 8 1374641320
6 1 882977 8 1372898763
7 1 1229238 9 1373506523
8 1 1288558 5 1373154354
9 1 1300854 8 1377165712
read_csv 使用说明
说明,本次导入dat文件使用pandas.read_csv函数。
第一个位置参数./data/movietweetings/ratings.dat 表示文件的相对路径
第二个关键字参数:delimiter='::',表示文件分隔符使用::
后面几个关键字参数分别代表使用的引擎,文件没有表头,所以header为None;
导入后dataframe的列名使用names关键字设置,这个参数大家可以记住,比较有用。
Kaggle电影数据集第一节,我们使用数据处理利器 pandas, 函数read_csv 导入给定的三个数据文件。
import pandas as pd
movies = pd.read_csv('./data/movietweetings/movies.dat', delimiter='::', engine='python', header=None, names = ['Movie ID', 'Movie Title', 'Genre'])
users = pd.read_csv('./data/movietweetings/users.dat', delimiter='::', engine='python', header=None, names = ['User ID', 'Twitter ID'])
ratings = pd.read_csv('./data/movietweetings/ratings.dat', delimiter='::', engine='python', header=None, names = ['User ID', 'Movie ID', 'Rating', 'Rating Timestamp'])
用到的read_csv,某些重要的参数,如何使用在上一节也有所提到。下面开始数据探索分析(EDA)
找出得分前10喜剧(comedy)
3 处理组合值
表movies字段Genre表示电影的类型,可能有多个值,分隔符为|,取值也可能为None.
针对这类字段取值,可使用Pandas中Series提供的str做一步转化,注意它是向量级的,下一步,如Python原生的str类似,使用contains判断是否含有comedy字符串:
mask = movies.Genre.str.contains('comedy',case=False,na=False)
注意使用的两个参数:case, na
case为 False,表示对大小写不敏感;
na Genre列某个单元格为NaN时,我们使用的充填值,此处填充为False
返回的mask是一维的Series,结构与 movies.Genre相同,取值为True 或 False.
观察结果:
0 False
1 False
2 False
3 False
4 False
5 True
6 True
7 False
8 False
9 False
Name: Genre, dtype: bool
4 访问某列
得到掩码mask后,pandas非常方便地能提取出目标记录:
comedy = movies[mask]
comdey_ids = comedy['Movie ID']
以上,在pandas中被最频率使用,不再解释。看结果comedy_ids.head():
5 131
6 417
15 2354
18 3863
19 4099
20 4100
21 4101
22 4210
23 4395
25 4518
Name: Movie ID, dtype: int64
1-4介绍数据读入,处理组合值,索引数据等, pandas中使用较多的函数,基于Kaggle真实电影影评数据集,最后得到所有喜剧 ID:
5 131
6 417
15 2354
18 3863
19 4099
20 4100
21 4101
22 4210
23 4395
25 4518
Name: Movie ID, dtype: int64
下面继续数据探索之旅~
5 连接两个表
拿到所有喜剧的ID后,要想找出其中平均得分最高的前10喜剧,需要关联另一张表:ratings:
再回顾下ratings表结构:
User ID Movie ID Rating Rating Timestamp
0 1 111161 10 1373234211
1 1 117060 7 1373415231
2 1 120755 6 1373424360
3 1 317919 6 1373495763
4 1 454876 10 1373621125
5 1 790724 8 1374641320
6 1 882977 8 1372898763
7 1 1229238 9 1373506523
8 1 1288558 5 1373154354
9 1 1300854 8 1377165712
pandas 中使用join关联两张表,连接字段是Movie ID,如果顺其自然这么使用join:
combine = ratings.join(comedy, on='Movie ID', rsuffix='2')
左右滑动,查看完整代码
大家可验证这种写法,仔细一看,会发现结果非常诡异。
究其原因,这是pandas join函数使用的一个算是坑点,它在官档中介绍,连接右表时,此处右表是comedy,它的index要求是连接字段,也就是 Movie ID.
左表的index不要求,但是要在参数 on中给定。
以上是要注意的一点
修改为:
combine = ratings.join(comedy.set_index('Movie ID'), on='Movie ID')
print(combine.head(10))
以上是OK的写法
观察结果:
User ID Movie ID Rating Rating Timestamp Movie Title Genre
0 1 111161 10 1373234211 NaN NaN
1 1 117060 7 1373415231 NaN NaN
2 1 120755 6 1373424360 NaN NaN
3 1 317919 6 1373495763 NaN NaN
4 1 454876 10 1373621125 NaN NaN
5 1 790724 8 1374641320 NaN NaN
6 1 882977 8 1372898763 NaN NaN
7 1 1229238 9 1373506523 NaN NaN
8 1 1288558 5 1373154354 NaN NaN
9 1 1300854 8 1377165712 NaN NaN
Genre列为NaN表明,这不是喜剧。需要筛选出此列不为NaN 的记录。
6 按列筛选
pandas最方便的地方,就是向量化运算,尽可能减少了for循环的嵌套。
按列筛选这种常见需求,自然可以轻松应对。
为了照顾初次接触 pandas 的朋友,分两步去写:
mask = pd.notnull(combine['Genre'])
结果是一列只含True 或 False的值
result = combine[mask]
print(result.head())
结果中,Genre字段中至少含有一个Comedy字符串,表明验证了我们以上操作是OK的。
User ID Movie ID Rating Rating Timestamp Movie Title \
12 1 1588173 9 1372821281 Warm Bodies (2013)
13 1 1711425 3 1372604878 21 & Over (2013)
14 1 2024432 8 1372703553 Identity Thief (2013)
17 1 2101441 1 1372633473 Spring Breakers (2012)
28 2 1431045 7 1457733508 Deadpool (2016)
Genre
12 Comedy|Horror|Romance
13 Comedy
14 Adventure|Comedy|Crime|Drama
17 Comedy|Crime|Drama
28 Action|Adventure|Comedy|Sci-Fi
截止目前已经求出所有喜剧电影result,前5行如下,Genre中都含有Comedy字符串:
User ID Movie ID Rating Rating Timestamp Movie Title \
12 1 1588173 9 1372821281 Warm Bodies (2013)
13 1 1711425 3 1372604878 21 & Over (2013)
14 1 2024432 8 1372703553 Identity Thief (2013)
17 1 2101441 1 1372633473 Spring Breakers (2012)
28 2 1431045 7 1457733508 Deadpool (2016)
Genre
12 Comedy|Horror|Romance
13 Comedy
14 Adventure|Comedy|Crime|Drama
17 Comedy|Crime|Drama
28 Action|Adventure|Comedy|Sci-Fi
7 按照Movie ID 分组
result中会有很多观众对同一部电影的打分,所以要求得分前10的喜剧,先按照Movie ID分组,然后求出平均值:
score_as_movie = result.groupby('Movie ID').mean()
前5行显示如下:
User ID Rating Rating Timestamp
Movie ID
131 34861.000000 7.0 1.540639e+09
417 34121.409091 8.5 1.458680e+09
2354 6264.000000 8.0 1.456343e+09
3863 43803.000000 10.0 1.430439e+09
4099 25084.500000 7.0 1.450323e+09
8 按照电影得分排序
score_as_movie.sort_values(by='Rating', ascending = False,inplace=True)
score_as_movie
前5行显示如下:
User IDRatingRating Timestamp
Movie ID
713469030110.010.01.524974e+09
4168891319.010.01.543320e+09
5784023589.010.01.396802e+09
569356250266.010.01.511024e+09
507443803.010.01.428352e+09
都是满分?这有点奇怪,会不会这些电影都只有几个人评分,甚至只有1个?评分样本个数太少,显然最终的平均分数不具有太强的说服力。
所以,下面要进行每部电影的评分人数统计
9 分组后使用聚合函数
根据Movie ID分组后,使用count函数统计每组个数,只保留count列,最后得到watchs2:
watchs = result.groupby('Movie ID').agg(['count'])
watchs2 = watchs['Rating']['count']
打印前20行:
print(watchs2.head(20))
结果:
Movie ID
131 1
417 22
2354 1
3863 1
4099 2
4100 1
4101 1
4210 1
4395 1
4518 1
4546 2
4936 2
5074 1
5571 1
6177 1
6414 3
6684 1
6689 1
7145 1
7162 2
Name: count, dtype: int64
果然,竟然有这么多电影的评论数只有1次!样本个数太少,评论的平均值也就没有什么说服力。
查看watchs2一些重要统计量:
watchs2.describe()
结果:
count 10740.000000
mean 20.192086
std 86.251411
min 1.000000
25% 1.000000
50% 2.000000
75% 7.000000
max 1843.000000
Name: count, dtype: float64
共有10740部喜剧电影被评分,平均打分次数20次,标准差86,75%的电影样本打分次数小于7次,最小1次,最多1843次。
10 频率分布直方图
绘制评论数的频率分布直方图,便于更直观的观察电影被评论的分布情况。上面分析到,75%的电影打分次数小于7次,所以绘制打分次数小于20次的直方图:
fig = plt.figure(figsize=(12,8))
histn = plt.hist(watchs2[watchs2 <=19],19,histtype='step')
plt.scatter([i+1 for i in range(len(histn[0]))],histn[0])
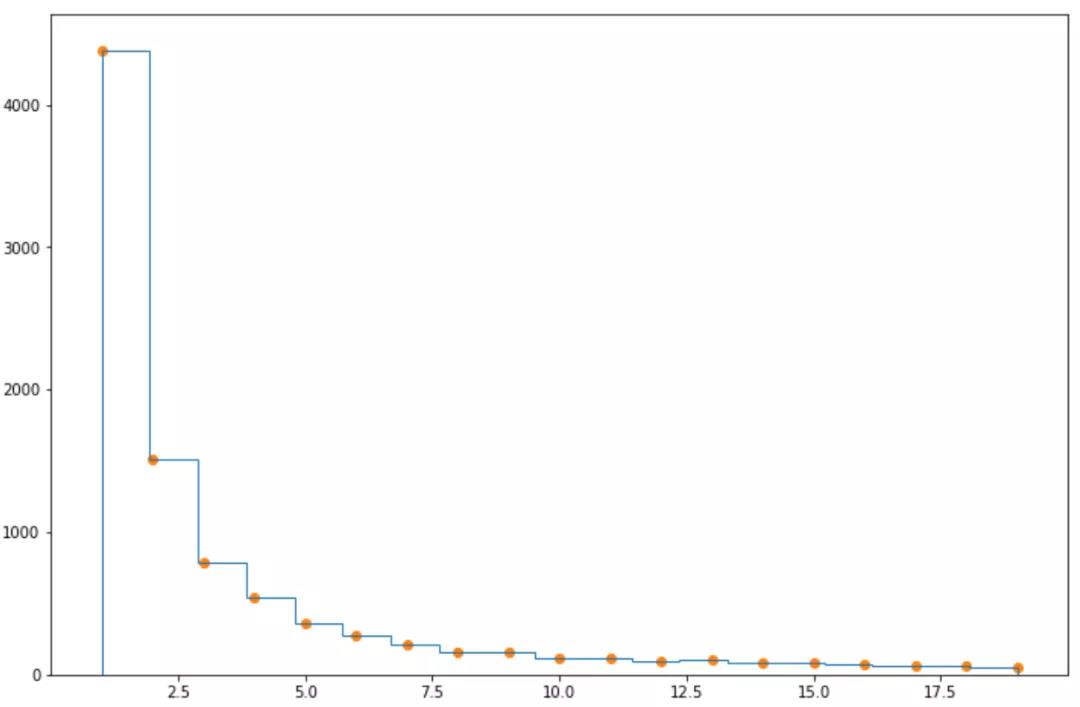
histn元祖表示个数和对应的被分割的区间,查看histn[0]:
array([4383., 1507., 787., 541., 356., 279., 209., 163., 158.,
118., 114., 90., 104., 81., 80., 73., 62., 65.,
52.])
sum(histn[0]) # 9222
看到电影评论次数1到19次的喜剧电影9222部,共有10740部喜剧电影,大约86%的喜剧电影评论次数小于20次,有1518部电影评论数不小于20次。
我们肯定希望挑选出被评论次数尽可能多的电影,因为难免会有水军和滥竽充数等异常评论行为。那么,如何准确的量化最小抽样量呢?
11 最小抽样量
根据统计学的知识,最小抽样量和Z值、样本方差和样本误差相关,下面给出具体的求解最小样本量的计算方法。
采用如下计算公式:
$$ n = \frac{Z^2\sigma^2}{E^2} $$
此处,$Z$ 值取为95%的置信度对应的Z值也就是1.96,样本误差取为均值的2.5%.
根据以上公式,编写下面代码:
n3 = result.groupby('Movie ID').agg(['count','mean','std'])
n3r = n3[n3['Rating']['count']>=20]['Rating']
只计算影评超过20次,且满足最小样本量的电影。计算得到的n3r前5行:
countmeanstd
Movie ID
417228.5000001.263027
12349688.4852941.227698
15324208.3500001.039990
15864518.4313731.374844
17925448.6363641.259216
进一步求出最小样本量:
nmin = (1.96**2*n3r['std']**2) / ( (n3r['mean']*0.025)**2 )
nmin前5行:
Movie ID
417 135.712480
12349 128.671290
15324 95.349276
15864 163.434005
17925 130.668350
筛选出满足最小抽样量的喜剧电影:
n3s = n3r[ n3r['count'] >= nmin ]
结果显示如下,因此共有173部电影满足最小样本抽样量。
countmeanstd
Movie ID
536041298.6356591.230714
570122078.4492751.537899
707352248.8392861.190799
756862098.0956941.358885
887632968.9459461.026984
............
63206288607.9662791.469924
64124522767.5108701.389529
66620502210.0000000.000000
69666929078.6736491.286455
713162211027.8511801.751500
173 rows × 3 columns
12 去重和连表
按照平均得分从大到小排序:
n3s_sort = n3s.sort_values(by='mean',ascending=False)
结果:
countmeanstd
Movie ID
66620502210.0000000.000000
49218604810.0000000.000000
52629722810.0000000.000000
55128723539.9858360.266123
38635521999.0100501.163372
............
12911506476.3276661.785968
25574905466.3076921.858434
14788391206.2000000.728761
21777714856.1505151.523922
195126110916.0834101.736127
173 rows × 3 columns
有一个细节容易忽视,因为上面连接的ratings表Movie ID会有重复,因为会有多个人评论同一部电影。所以再对n3s_sort去重:
n3s_drops = n3s_sort.drop_duplicates(subset=['count'])
结果:
countmeanstd
Movie ID
66620502210.0000000.000000
49218604810.0000000.000000
52629722810.0000000.000000
55128723539.9858360.266123
38635521999.0100501.163372
............
12911506476.3276661.785968
25574905466.3076921.858434
14788391206.2000000.728761
21777714856.1505151.523922
195126110916.0834101.736127
157 rows × 3 columns
仅靠Movie ID还是不知道哪些电影,连接movies表:
ms = movies.drop_duplicates(subset=['Movie ID'])
ms = ms.set_index('Movie ID')
n3s_final = n3s_drops.join(ms,on='Movie ID')
13 结果分析
喜剧榜单前50名:
Movie Title
Five Minutes (2017)
MSG 2 the Messenger (2015)
Avengers: Age of Ultron Parody (2015)
Be Somebody (2016)
Bajrangi Bhaijaan (2015)
Back to the Future (1985)
La vita bella (1997)
The Intouchables (2011)
The Sting (1973)
Coco (2017)
Toy Story 3 (2010)
3 Idiots (2009)
Green Book (2018)
Dead Poets Society (1989)
The Apartment (1960)
P.K. (2014)
The Truman Show (1998)
Am鑼卨ie (2001)
Inside Out (2015)
Toy Story 4 (2019)
Toy Story (1995)
Finding Nemo (2003)
Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb (1964)
Home Alone (1990)
Zootopia (2016)
Up (2009)
Monsters, Inc. (2001)
La La Land (2016)
Relatos salvajes (2014)
En man som heter Ove (2015)
Snatch (2000)
Lock, Stock and Two Smoking Barrels (1998)
How to Train Your Dragon 2 (2014)
As Good as It Gets (1997)
Guardians of the Galaxy (2014)
The Grand Budapest Hotel (2014)
Fantastic Mr. Fox (2009)
Silver Linings Playbook (2012)
Sing Street (2016)
Deadpool (2016)
Annie Hall (1977)
Pride (2014)
In Bruges (2008)
Big Hero 6 (2014)
Groundhog Day (1993)
The Breakfast Club (1985)
Little Miss Sunshine (2006)
Deadpool 2 (2018)
The Terminal (2004)
前10名评论数图:
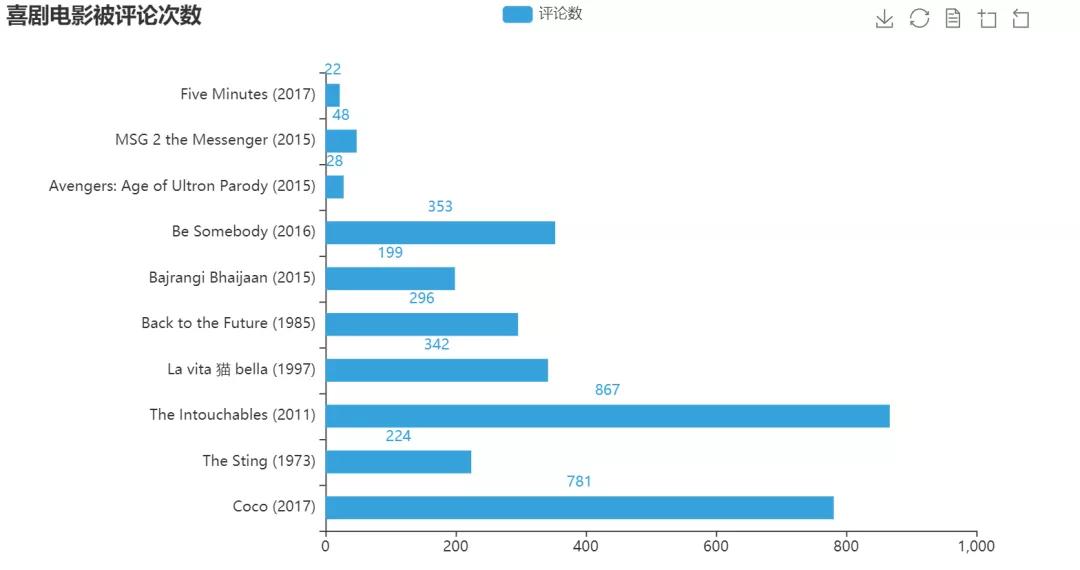
代码:
x = n3s_final['Movie Title'][:10].tolist()[::-1]
y = n3s_final['count'][:10].tolist()[::-1]
bar = (
Bar()
.add_xaxis(x)
.add_yaxis('评论数',y,category_gap='50%')
.reversal_axis()
.set_global_opts(title_opts=opts.TitleOpts(title="喜剧电影被评论次数"),
toolbox_opts=opts.ToolboxOpts(),)
)
grid = (
Grid(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add(bar, grid_opts=opts.GridOpts(pos_left="30%"))
)
grid.render_notebook()
前10名得分图:
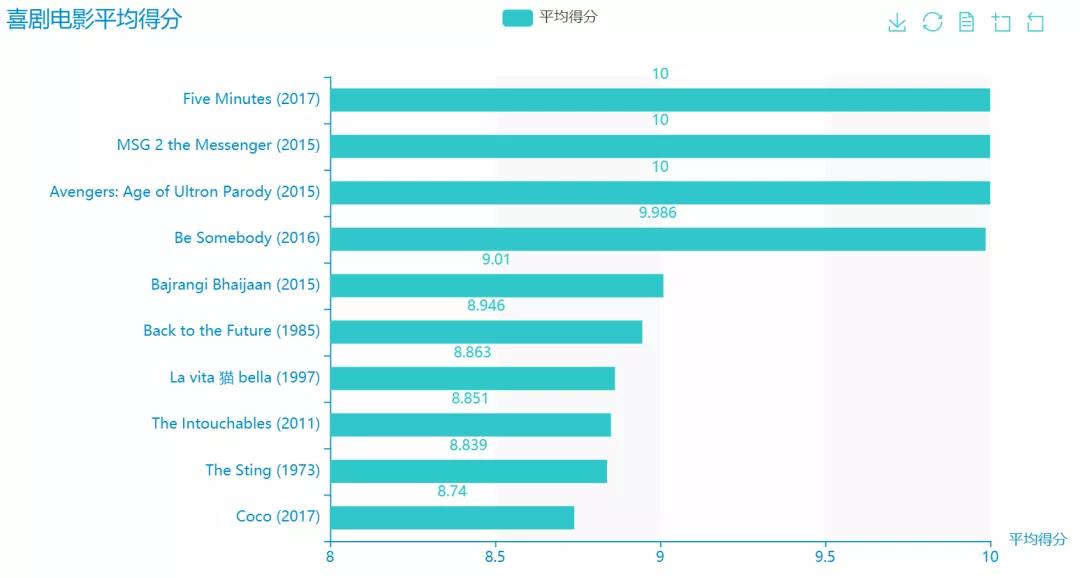
代码:
x = n3s_final['Movie Title'][:10].tolist()[::-1]
y = n3s_final['mean'][:10].round(3).tolist()[::-1]
bar = (
Bar()
.add_xaxis(x)
.add_yaxis('平均得分',y,category_gap='50%')
.reversal_axis()
.set_global_opts(title_opts=opts.TitleOpts(title="喜剧电影平均得分"),
xaxis_opts=opts.AxisOpts(min_=8.0,name='平均得分'),
toolbox_opts=opts.ToolboxOpts(),)
)
grid = (
Grid(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
.add(bar, grid_opts=opts.GridOpts(pos_left="30%"))
)
grid.render_notebook()














 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









