






写在前面
SQL可谓是数据分析必备技能之一了,面试中也是高频出现,初学SQL可以阅读《SQL必知必会》

全书通俗易懂,看完之后可以到牛客网和LeetCode刷一些SQL题巩固巩固。
数据库SQL实战_牛客网www.nowcoder.com 题库 - 力扣 (LeetCode)leetcode-cn.com
不过面试中的SQL大多都是结合部门业务,这里将我自己经历过的和之前看到的一些面试题收集整理过来,前期顺序可能比较乱,之后陆陆续续会归类分析。
目录(2020-05-18)
- 用户签到问题
- 销售情况问题
- sql去重操作
- 相邻间隔问题
- count(1)、count(*)和count(列名)的区别
切入正题
1. 用户签到问题
<题目>
给定一张用户签到表user_attendence,表中包含三个字段,分别是用户ID:【user_id】,日期:【date】,是否签到:【is_sign_in】,0否1是。
<问题1> 计算截至当前,每个用户已经连续签到的天数:
要求输出用户ID【user_id】和连续签到天数【recent_continuous_days】
<问题2> 计算有史以来用户最大连续签到天数:
要求输出用户ID【user_id】和最大连续签到天数【max_continuous_days】
<解题思路>
针对问题1,这里有一种非常巧妙的解法:只需要利用Max和datediff函数,也就是说只要找到用户最近一次没有签到的日期,计算和当前日期的差值即可。
针对问题2,可以将是否签到转换为一条0-1字符串序列,用0做split切割,计算切出来的1序列组中的最大长度。也可以运用窗口函数row_number,给所有签到记录为1的列排序号,这里也有一种很巧妙的思想,就用每行的签到日期减去序号,如果签到日期是连续的话,求得的值则是相同值,一旦日期不连续,将会求得一个新的相同值,这样的话,可以统计每个值的数量,进而判定最长签到天数。
举个栗子,下图为用户1在4月20日到4月27日的签到记录,其中4月23日没有签到,可以发现差值为19和20,其中20出现次数最多,有4次,说明该用户最大连续签到天数为4天。

不过有一点值得注意的是,求得的【值】必须唯一,上图中的数字显然不唯一。这里可以用日期去当作这个【差值】,毕竟日期具有唯一性,可以考虑运用MySQL中的DATE_SUB函数。
如果对窗口函数不了解的话,可以看我这个文章:
狗哥:数据分析|SQL窗口函数zhuanlan.zhihu.com
<答案>
# 求截止当前的连续签到天数
SELECT user_id, DATEDIFF('2020-04-27', max_date) AS recent_continuous_days
FROM (SELECT user_id, MAX(date) AS max_date
FROM user_attendence
WHERE is_sign_in = 0
GROUP BY user_id
) AS b
# 求有史以来的最大连续签到天数(窗口函数)
SELECT b.user_id, MAX(b.continues_day) as max_continuous_days
FROM (SELECT a.user_id, DATE_SUB(a.date, INTERVAL a.rn DAY) AS difference, COUNT(*) AS continues_day
FROM (SELECT user_id, date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY date) AS rn
FROM user_attendence
WHERE is_sign_in = 1) AS a
GROUP BY a.user_id, difference
) AS b
GROUP BY b.user_id2. 销售计算问题
<题目及问题>
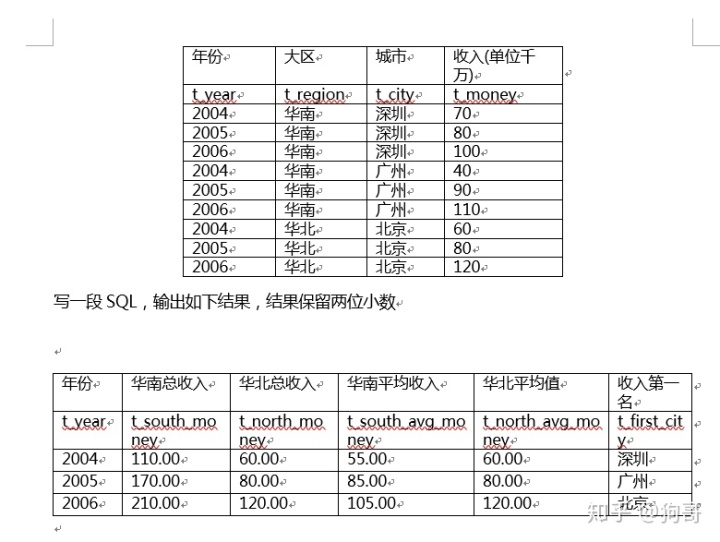
<解答>
这里用的办法比较复杂,主要涉及到了row_number、if和round函数,仅作参考
SELECT a.t_year,
ROUND(SUM(IF(a.t_region = '华南', a.t_money, 0)), 2) as '华南总收入',
ROUND(SUM(IF(a.t_region = '华北', a.t_money, 0)), 2) as '华北总收入',
ROUND(SUM(IF(a.t_region = '华南', a.t_money, 0)) / SUM(cicy_hn), 2) as '华南平均收入',
ROUND(SUM(IF(a.t_region = '华北', a.t_money, 0)) / SUM(cicy_hb), 2) as '华北平均收入',
if(a.ranknumber = 1, a.t_city, 0) AS 销售第一
FROM (SELECT t_year,
t_region,
t_city,
t_money,
if(t_region = '华南',COUNT(t_region), 0) AS cicy_hn,
if(t_region = '华北',COUNT(t_region), 0) AS cicy_hb,
ROW_NUMBER() OVER (PARTITION BY t_year ORDER BY t_money DESC) AS ranknumber
FROM sql2
GROUP BY t_year, t_city) AS a
GROUP BY t_year输出如下:

3. 去重问题
请移步
狗哥:数据分析|记一“道”难忘的SQL面试题...zhuanlan.zhihu.com
4. 相邻间隔问题
请移步
狗哥:数据分析|SQL面试题—相邻间隔问题zhuanlan.zhihu.com
5. count(1)、count(*)和count(列名)的区别
- 从执行结果来看
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计
- 从执行效率来看
- 如果列为主键,count(列名)效率优于count(1)
- 如果列不为主键,count(1)效率优于count(列名)
- 如果表中存在主键,count(主键列名)效率最优
- 如果表中只有一列,则count(*)效率最优
- 如果表有多列,且不存在主键,则count(1)效率优于count(*)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









