








在正式开始推理代码分析之前, 回顾下 MNN整体结构
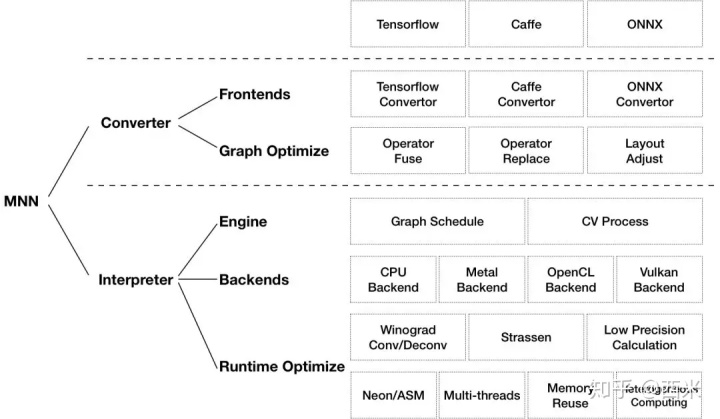
推理分为三个大部分
- Engine
- Backends
- Runtime Optimize
那么问题来了,从哪里开始,怎么入手呢? 我的心得是源码分析不能直接一头扎进去, 陷入迷茫.
应该遵循两个原则
- 从外到内 : 外部sdk接口开始,顺藤摸瓜分析.
- 从整体到局部: 先整体上了解这个东西,可以先阅读官方资料知道整体框架,以及哪些模块,分别起到什么作用.
建议按照之前使用方法,把MNN自带的Android demo编译安装运行,并且简单过一遍调用流程, 这里采用从外到内的方法着手分析.
Android上用MNN SDK做推理
以下内容参考自MNN参考文档
MNN中有两个概念:解释器Interpreter和会话Session。
解释器 负责加载模型, 持有模型数据;
会话是由解释器创建的,它是推理数据的持有者。多个推论可以共享相同的模型数据,也就是说,多个会话可以共享一个解释器
Session
创建会话得先有解释器, 解释器就是把模型文件加载进来的, 自然就有如下API:
根据指定MNN模型文件,创建解释器Interpreter
/**
* @brief create net from file.
* @param file given file.
* @return created net if success, NULL otherwise.
*/
static Interpreter* createFromFile(const char* file);
解释器提供了创建会话的方法Interpreter::createSession, 通过传递一个config文件配置这个会话.
/**
* @brief create session with schedule config. created session will be managed in net.
* @param config session schedule config.
* @return created session if success, NULL otherwise.
*/
Session* createSession(const ScheduleConfig& config);
会话配置Scheduling configuration
/** session schedule config */
struct ScheduleConfig {
/** which tensor should be kept */
std::vector<std::string> saveTensors;
/** forward type, CPU 或者GPU */
MNNForwardType type = MNN_FORWARD_CPU;
/** number of threads in parallel 线程数 */
int numThread = 4;
/** subpath to run */
struct Path {
std::vector<std::string> inputs;
std::vector<std::string> outputs;
enum Mode {
/**
* Op Mode
* - inputs means the source op, can NOT be empty.
* - outputs means the sink op, can be empty.
* The path will start from source op, then flow when encounter the sink op.
* The sink op will not be compute in this path.
*/
Op = 0,
/**
* Tensor Mode (NOT supported yet)
* - inputs means the inputs tensors, can NOT be empty.
* - outputs means the outputs tensors, can NOT be empty.
* It will find the pipeline that compute outputs from inputs.
*/
Tensor = 1
};
/** running mode */
Mode mode = Op;
};
Path path;
/** backup backend used to create execution when desinated backend do NOT support any op */
MNNForwardType backupType = MNN_FORWARD_CPU;
/** extra backend config */
BackendConfig* backendConfig = nullptr;
};
在推理中,主后端计算是由type指定的,缺省值是CPU。由backupType指定的备用后端,当主选择后端不支持模型中的操作符时启用备用后端。
推理路径是指从输入到输出计算过程中涉及到的operator。如果没有指定,它将根据模型结构自动识别。为了节省内存,MNN复用了tensor的内存(除了output tensor)。因此如果你需要保存中间tensor的结果,必须传入中间tensor, 放到saveTensors作为参数, 来避免内存复用。
在进行推断时,可以使用numThread修改线程的数量。但是线程的实际数量取决于部署环境:
•iOS,使用GCD,忽略配置;
•当MNN_USE_THREAD_POOL被启用时,线程的数量取决于第一次配置的线程数量;
•OpenMP,线程数全局设置,实际线程数取决于上次配置的线程数;
此外,可以通过backendConfig设置后端参数。详见下文。
Backend Configuration
backend configuration的定义:
struct BackendConfig {
enum MemoryMode {
Memory_Normal = 0,
Memory_High,
Memory_Low
};
MemoryMode memory = Memory_Normal;
enum PowerMode {
Power_Normal = 0,
Power_High,
Power_Low
};
PowerMode power = Power_Normal;
enum PrecisionMode {
Precision_Normal = 0,
Precision_High,
Precision_Low
};
PrecisionMode precision = Precision_Normal;
/** user defined context */
void* sharedContext = nullptr;
};
MemoryMode, PowerMode和 PrecisionMode 分别是指 内存占用,功耗,精度配置,
Input Data
获取Input Tensor
两个接口, getSessionInput是获取输入的tensor. 如果模型是有多个input tensor时用第二个接口getSessionInputAll
/**
* @brief get input tensor for given name.
* @param session given session.
* @param name given name. if NULL, return first input.
* @return tensor if found, NULL otherwise.
*/
Tensor* getSessionInput(const Session* session, const char* name);
/**
* @brief get all output tensors.
* @param session given session.
* @return all output tensors mapped with name.
*/
const std::map<std::string, Tensor*>& getSessionInputAll(const Session* session) const;
Fill Data
auto inputTensor = interpreter->getSessionInput(session, NULL);
inputTensor->host<float>()[0] = 1.f;
Backend为cpu时, 直接复制到Input tensot的host属性即可.
Copy Data
对于非cpu的backend,参考如下实例
auto inputTensor = interpreter->getSessionInput(session, NULL);
auto nchwTensor = new Tensor(inputTensor, Tensor::CAFFE);
// nchwTensor-host<float>()[x] = ...
inputTensor->copyFromHostTensor(nchwTensor);
delete nchwTensor;
Image Processing
struct Config
{
Filter filterType = NEAREST;
ImageFormat sourceFormat = RGBA;
ImageFormat destFormat = RGBA;
//Only valid if the dest type is float
float mean[4] = {
0.0f,0.0f,0.0f, 0.0f};
float normal[4] = {
1.0f, 1.0f, 1.0f, 1.0f};
};
CV::ImageProcess::Config
- Specify input and output formats by
sourceFormatanddestFormat, currently supportsRGBA、RGB、BGR、GRAY、BGRA、YUV_NV21 - Specify the type of interpolation by
filterType, currently supportsNEAREST,BILINEARandBICUBIC - Specify the mean normalization by
meanandnormal, but the setting is ignored when the data type is not a floating point type
Run Session
调用解释器Interpreter的runSession方法
/**
* @brief run session.
* @param session given session.
* @return result of running.
*/
ErrorCode runSession(Session* session) const;
Run Session with Callbacks
typedef std::function<bool(const std::vector<Tensor*>&,
const std::string& /*opName*/)> TensorCallBack;
/*
* @brief run session.
* @param session given session.
* @param before callback before each op. return true to run the op; return false to skip the op.
* @param after callback after each op. return true to continue running; return false to interrupt the session.
* @param sync synchronously wait for finish of execution or not.
* @return result of running.
*/
ErrorCode runSessionWithCallBack(const Session* session,
const TensorCallBack& before,
const TensorCallBack& end,
bool sync = false) const;
Compared to runSession, runSessionWithCallback provides additional:
- Callbacks before each op, which could be used to skip the execution;
- Callback after each op, which could be used to interrupt the inference;
- Synchronization option, defaults off; when enabled, all backends will wait for inference to complete, ie the function time cost is equal to the inference time cost;
Get Output
Get Output Tensor
/**
* @brief get output tensor for given name.
* @param session given session.
* @param name given name. if NULL, return first output.
* @return tensor if found, NULL otherwise.
*/
Tensor* getSessionOutput(const Session* session, const char* name);
/**
* @brief get all output tensors.
* @param session given session.
* @return all output tensors mapped with name.
*/
const std::map<std::string, Tensor*>& getSessionOutputAll(const Session* session) const;Interpreter provides two ways to get the output Tensor: getSessionOutput for getting a single output tensor and getSessionOutputAll for getting the output tensor map.
When there is only one output tensor, you can pass NULL to get the tensor when calling
getSessionOutput.
Read Data
auto outputTensor = interpreter->getSessionOutput(session, NULL);
auto score = outputTensor->host<float>()[0];
auto index = outputTensor->host<float>()[1];
// ...
The simplest way to read data is to read from host of Tensor directly, but this usage is limited to the CPU backend, other backends need to read the data through deviceid. On the other hand, users need to handle the differences between NC4HW4 and NHWC data layouts.
For non-CPU backends, or users who are not familiar with data layout, copy data interfaces should be used.
Copy Data
NCHW examp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









