






selenium是一个自动化测试的工具,可以模拟人的操作,而且配合python来使用非常方便。
官网:SeleniumHQ Browser Automation
安装配置
要开始使用selenium,需要安装一些依赖
conda install selenium
要使用selenium去调用浏览器,还需要一个驱动,不同浏览器的webdriver需要独立安装
https://www.selenium.dev/documentation/en/webdriver/driver_requirements/Driver requirementshttps://www.selenium.dev/documentation/en/webdriver/driver_requirements/
我这里就下载Firefox的驱动,下载之后,是一个EXE文件
把这个文件找地方放一下,然后,加入到PATH中
这两步做完之后,就可以测试下了
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
遇到的第一个问题,是这个driver,说找不到,但是我已经配置到PATH中了
这里也可以手工指定路径
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'C:Program FilesMozilla Firefoxgeckodriver.exe')
driver.get("https://www.baidu.com/")如果环境没有问题的话,就会弹出一个火狐浏览器,打开百度网址
定位元素
我们打开一个网页之后,我们就可以定位我们指定的页面元素,比如文本款,按钮等
我们继续以百度为例,我们填入关键词“python”,并提交搜索
为了填入关键词,我们首先如要知道怎么找到这个搜索框
在浏览器中,使用开发者工具,查看代码
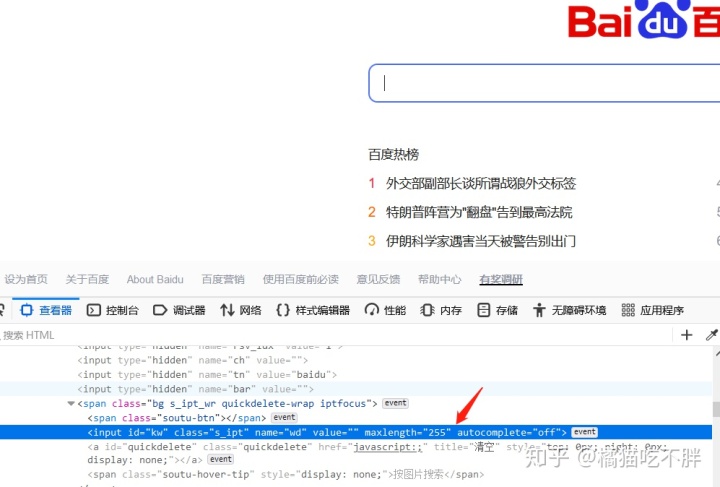
这里应该是这个input,它属于一个form表单
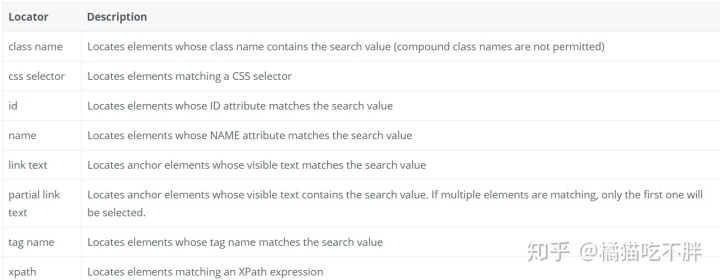
大概可以使用这几种方式来确定一个元素
这里先使用id来找到这个元素
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'C:Program FilesMozilla Firefoxgeckodriver.exe')
driver.get("https://www.baidu.com/")
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('python'))
print(p_input.text)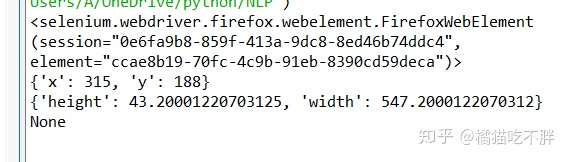
location,是元素的位置;
size是元素的大小
send_keys是给元素传入值,这里,我们再传入python之后,会自动展开搜索
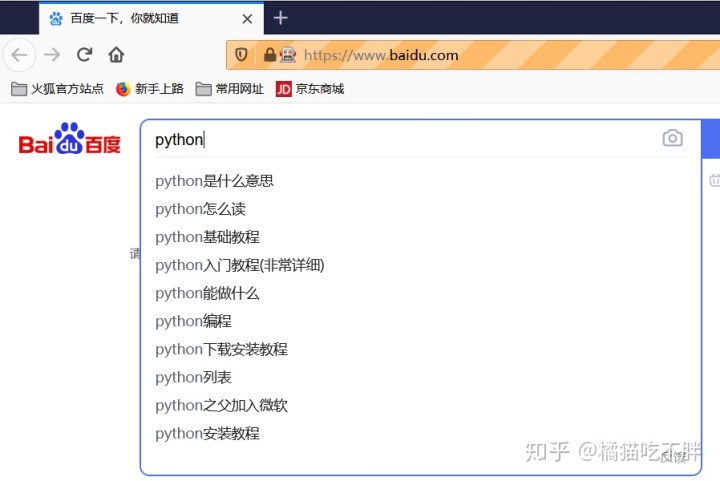
最后一行p_input.text,本来是想输入元素的内容,但是这里是None,或许,我们应该用另一种方式来获取
print(p_input.get_property('name'))
print(p_input.get_property('value'))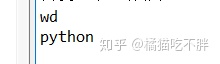
使用get_property函数,可以根据属性名称获取值
好了,我们接着看

我们在传入搜索值之后,页面切换了,但是,并没有进行搜索,我们还差一步搜索
为了出发搜索,我们可以使用
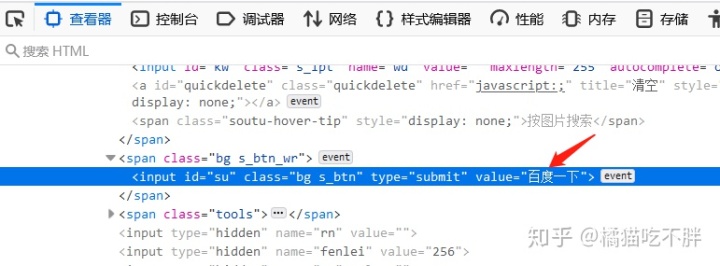
用另一个input,也就是按钮的点击事件来实现;或者是form表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()重新执行后,就会进行搜索了
后面,我们还可以针对结果页面,进行处理
比如把所有的结果都记录下来
ads = driver.find_elements_by_css_selector("div.c-container")
print('count:', len(ads))
for a in ads:
try:
x = a.find_element_by_css_selector('h3:nth-child(1) > a:nth-child(1)')
print('title:', x.text)
print('url:', x.get_property('href'))
print('------------')
except NoSuchElementException as e:
print(e)















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









