






本文主要过程参考[1]
Motivation
先通过几组图片了解为什么需要使用GMM.
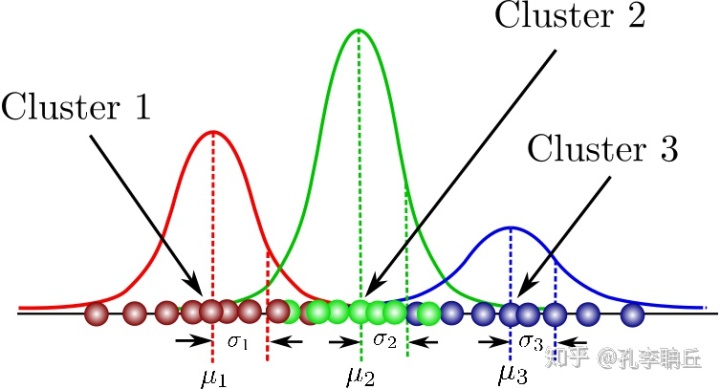
从几何角度来看,有的数据分布,用多个高斯分布的加权平均来描述合理一些.
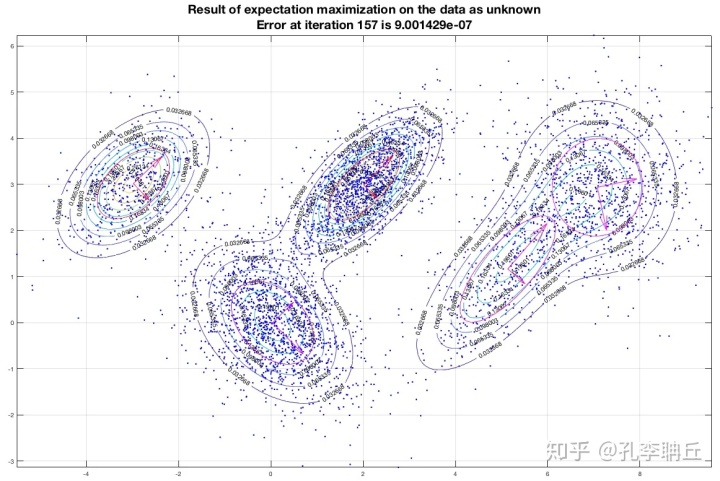
从混合模型的角度来看,
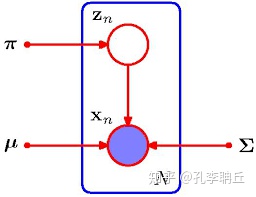
从生成过程来看, 用一个骰子投掷出z值从而确定样本所属分布,投掷N次就有N个样本了.
使用MLE估计参数
先推导如何消掉隐变量
做一些notation
使用MLE求参数
发现log里面有一个连加的符号, 这个是没有办法得到解析解的. 所以直接用MLE无法得出解析解. 解释可以参见[2]. 所以需要用数值解法比如梯度下降. 当然最流行的是EM算法.下面介绍EM算法.
EM 推导
EM的迭代公式如下:
先看E step, 令
单独研究中括号里面的公式
代入原式,有
现在就已经把E step求完了,现在开始M step.
求
这是约束优化,使用拉格朗日乘数法来解决.
对于
关于EM的算法的intuition,见<PRML>[3]
参考
- ^https://www.bilibili.com/video/BV13b411w7Xj?t=225
- ^<PRML> p433
- ^<PRML>,p450















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









