







这篇文章包含了你一定知道的,和你不一定知道的冒泡排序。
gif看不了可以点击【[原文](你知道和你不知道的冒泡排序)】查看gif。
源码: 【地址】
什么是冒泡排序
可能对于大多数的人来说比如我,接触的第一个算法就是冒泡排序。
我看过的很多的文章都把冒泡排序描述成我们喝的汽水,底部不停的有二氧化碳的气泡往上冒,还有描述成鱼吐泡泡,都特别的形象。
其实结合一杯水来对比很好理解,将我们的数组竖着放进杯子,数组中值小的元素密度相对较小,值大的元素密度相对较大。这样一来,密度大的元素就会沉入杯底,而密度小的元素会慢慢的浮到杯子的最顶部,稍微专业一点描述如下。
冒泡算法会运行多轮,每一轮会依次比较数组中相邻的两个元素的大小,如果左边的元素大于右边的元素,则交换两个元素的位置。最终经过多轮的排序,数组最终成为有序数组。
排序过程展示
我们先不聊空间复杂度和时间复杂度的概念,我们先通过一张动图来了解一下冒泡排序的过程。

这个图形象的还原了密度不同的元素上浮和下沉的过程。
算法V1
代码实现
private void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr.length - 1; j++) {
if (arr[j] > arr[j + 1]) {
exchange(arr, j, j + 1);
}
}
}
}
private void exchange(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
int[] arr = new int[]{5, 1, 3, 7, 6, 2, 4};
bubbleSort(arr);
System.out.println(Arrays.toString(arr)); // [1, 2, 3, 4, 5, 6, 7]实现分析
各位大佬看了上面的代码之后先别激动,坐下坐下,日常操作。可能很多的第一个冒泡排序算法就是这么写的,比如我,同时还自我感觉良好,觉得算法也不过如此。
我们还是以数组[5, 1, 3, 7, 6, 2, 4]为例,我们通过动图来看一下过程。

思路很简单,我们用两层循环来实现冒泡排序。
- 第一层,控制冒泡排序总共执行的轮数,例如例子数组的长度是7,那么总共需要执行6轮。如果长度是n,则需要执行n-1轮
- 第二层,负责从左到右依次的两两比较相邻元素,并且将大的元素交换到右侧
这就是冒泡排序V1的思路。
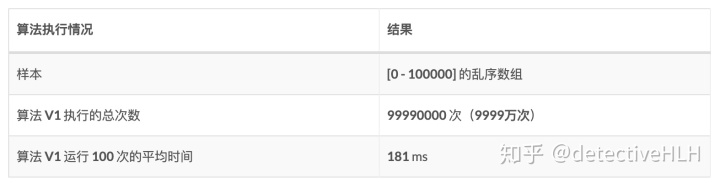
下表是通过对一个0-100000的乱序数组的标准样本,使用V1算法进行排序所总共执行的次数,以及对同一个数组执行100次V1算法的所花的平均时间。
算法V2
实现分析
仔细看动图我们可以发现,每一轮的排序,都从数组的最左端再到最右。而每一轮的冒泡,都可以确定一个最大的数,固定在数组的最右边,也就是密度最大的元素会冒泡到杯子的最上面。
还是拿上面的数组举例子。下图是第一轮冒泡之后数组的元素位置。

第二轮排序之后如下。

可以看到,每一轮排序都会确认一个最大元素,放在数组的最后面,当算法进行到后面,我们根本就没有必要再去比较数组后面已经有序的片段,我们接下来针对这个点来优化一下。
代码实现
这是优化之后的代码。
private void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
exchange(arr, j, j + 1);
}
}
}
}
private void exchange(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
int[] arr = new int[]{5, 1, 3, 7, 6, 2, 4};
bubbleSort(arr);
System.out.println(Arrays.toString(arr)); // [1, 2, 3, 4, 5, 6, 7]优化之后的实现,也就变成了我们动图中所展示的过程。
每一步之后都会确定一个元素在数组中的位置,所以之后的每次冒泡的需要比较的元素个数就会相应的减1。这样一来,避免了去比较已经有序的数组,从而减少了大量的时间。
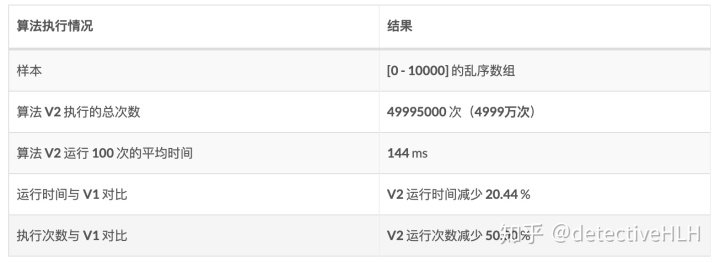
可能会有人看到,时间大部分已经会觉得满足了。从数据上看,执行的次数减少了50%,而运行的时间也减少了20%,在性能上已经是很大的提升了。而且已经减少了7亿次的执行次数,已经很NB了。 那是不是到这就已经很完美了呢?
答案是No。
哪里可以优化
同理,我们还是拿上面长度为7的数组来举例子,只不过元素的位置有所不同,假设数组的元素如下。
[7, 1, 2, 3, 4, 5, 6]
我们再来一步一步的执行V2算法, 看看会发生什么。
第一步执行完毕后,数组的情况如下。

继续推进,当第一轮执行完毕后,数组的元素位置如下。

这个时候,数组已经排序完毕,但是按照目前的V2逻辑,仍然有5轮排序需要继续,而且程序会完整的执行完5轮的排序,如果是100000轮呢?这样将会浪费大量的计算资源。
算法V3
代码实现
private void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
boolean flag = true;
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
flag = false;
exchange(arr, j, j + 1);
}
}
if (flag) {
break;
}
}
}
private void exchange(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
int[] arr = new int[]{5, 1, 3, 7, 6, 2, 4};
bubbleSort(arr);
System.out.println(Arrays.toString(arr)); // [1, 2, 3, 4, 5, 6, 7]实现分析
我们在V2代码的基础上,在第一层循环,也就是控制总冒泡轮数的循环中,加入了一个标志为flag。用来标示该轮冒泡排序中,数组是否是有序的。每一轮的初始值都是true。
当第二层循环,也就是冒泡排序的元素两两比较完成之后,flag的值仍然是true,则说明在这轮比较中没有任何元素被交换了位置。也就是说,数组此时已经是有序状态了,没有必要再执行后续的剩余轮数的冒泡了。
所以,如果flag的值是true,就直接break了(没有其他的操作return也没毛病)。
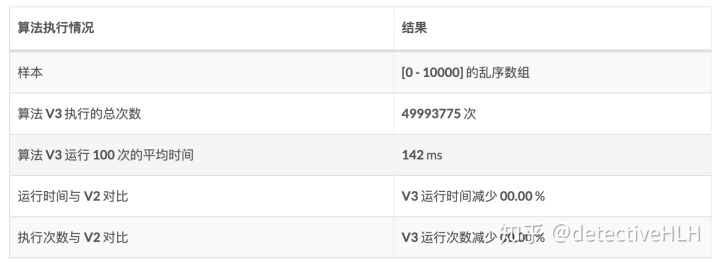
数据分析
大家看到数据可能有点懵逼。

你这个优化之后,运行时间执行次数都没有减少。你这优化的什么东西?
其实,这就要说到算法的适用性了。V3的优化是针对原始数据中存在一部分或者大量的数据已经是有序的情况,V3的算法对于这样的样本数据才最适用。
其实是我们还没有到优化这种情况的那一步,但是其实仍然有这样的说法,面对不同的数据结构,几乎没有算法是万能的
而目前的样本数据仍然是随机的乱序数组,所以并不能发挥优化之后的算法的威力。所谓对症下药,同理并不是所有的算法都是万能的。对于不同的数据我们需要选择不同的算法。例如我们选择[9999,1,2,…,9998]这行的数据做样本来分析,我们来看一下V3算法的表现。
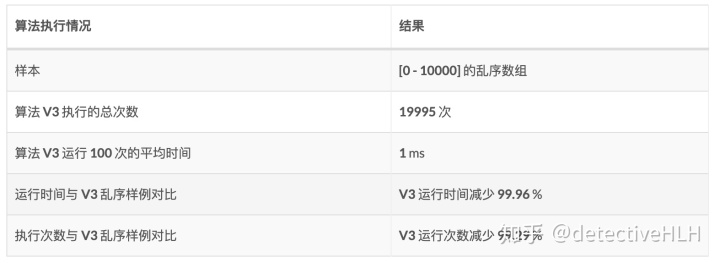
可以看到,提升非常明显。
适用情况
当冒泡算法运行到后半段的时候,如果此时数组已经有序了,需要提前结束冒泡排序。V3针对这样的情况就特别有效。
算法V4
嗯,什么?为什么不是结束语?那是因为还有一种没有考虑到啊。
适用情况总结
我们总结一下前面的算法能够处理的情况。
- V1:正常乱序数组
- V2:正常乱序数组,但对算法的执行次数做了优化
- V3:大部分元素已经有序的数组,可以提前结束冒泡排序
还有一种情况是冒泡算法的轮数没有执行完,甚至还没有开始执行,后半段的数组就已经有序的数组,例如如下的情况。

这种情况,在数组完全有序之前都不会触发V3中的提前停止算法,因为每一轮都有交换存在,flag的值会一直是true。而下标2之后的所有的数组都是有序的,算法会依次的冒泡完所有的已有序部分,造成资源的浪费。我们怎么来处理这种情况呢?
实现分析
我们可以在V3的基础之上来做。
当第一轮冒泡排序结束后,元素3会被移动到下标2的位置。在此之后没有再进行过任意一轮的排序,但是如果我们不做处理,程序仍然会继续的运行下去。
我们在V3的基础上,加上一个标识endIndex来记录这一轮最后的发生交换的位置。这样一来,下一轮的冒泡就只冒到endIndex所记录的位置即可。因为后面的数组没有发生任何的交换,所以数组必定有序。
代码实现
private void bubbleSort(int[] arr) {
int endIndex = arr.length - 1;
for (int i = 0; i < arr.length - 1; i++) {
boolean flag = true;
int endAt = 0;
for (int j = 0; j < endIndex; j++) {
if (arr[j] > arr[j + 1]) {
flag = false;
endAt = j;
exchange(arr, j, j + 1);
}
}
endIndex = endAt;
if (flag) {
break;
}
}
}
private void exchange(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
int[] arr = new int[]{5, 1, 3, 7, 6, 2, 4};
bubbleSort(arr);
System.out.println(Arrays.toString(arr)); // [1, 2, 3, 4, 5, 6, 7]算法V5
这一节仍然不是结束语...
算法优化
我们来看一下这种情况。

对于这种以上的算法都将不能发挥其应有的作用。每一轮算法都存在元素的交换,同时,直到算法完成以前,数组都不是有序的。但是如果我们能直接从右向左冒泡,只需要一轮就可以完成排序。这就是鸡尾酒排序,冒泡排序的另一种优化,其适用情况就是上图所展示的那种。
代码实现
private void bubbleSort(int[] arr) {
int leftBorder = 0;
int rightBorder = arr.length - 1;
int leftEndAt = 0;
int rightEndAt = 0;
for (int i = 0; i < arr.length / 2; i++) {
boolean flag = true;
for (int j = leftBorder; j < rightBorder; j++) {
if (arr[j] > arr[j + 1]) {
flag = false;
exchange(arr, j, j + 1);
rightEndAt = j;
}
}
rightBorder = rightEndAt;
if (flag) {
break;
}
flag = true;
for (int j = rightBorder; j > leftBorder; j--) {
if (arr[j] < arr[j - 1]) {
flag = false;
exchange(arr, j, j - 1);
leftEndAt = j;
}
}
leftBorder = leftEndAt;
if (flag) {
break;
}
}
}
private void exchange(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
int[] arr = new int[]{2, 3, 4, 5, 6, 7, 1};
bubbleSort(arr);
System.out.println(Arrays.toString(arr)); // [1, 2, 3, 4, 5, 6, 7]实现分析
第一层循环同样用于控制总的循环轮数,由于每次需要从左到右再从右到左,所以总共的轮数是数组的长度 / 2。
内存循环则负责先实现从左到右的冒泡排序,再实现从右到左的冒泡,并且同时结合了V4的优化点。
我们来看一下V5与V4的对比。
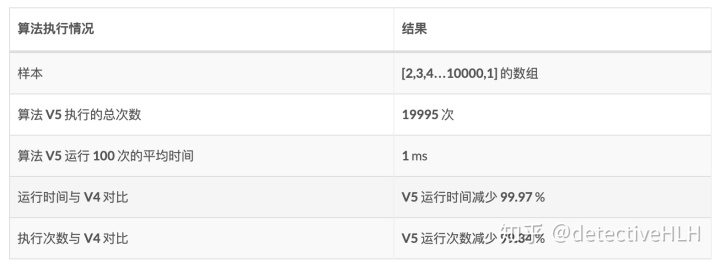
总结
以下是对同一个数组,使用每一种算法对其运行100次的平均时间和执行次数做的的对比。
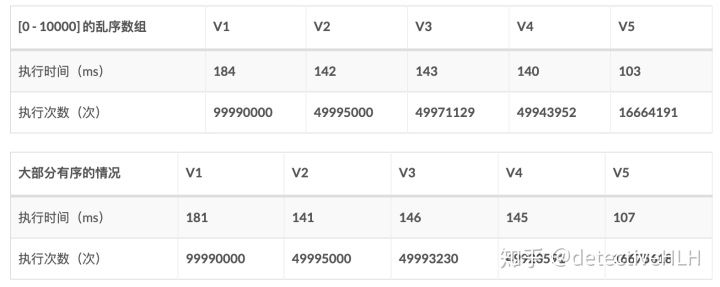
而冒泡排序的时间复杂度分为最好的情况和最快的情况。
- 最好的情况为O($$n$$). 也就是我们在V5中提到的那种情况,数组
2, 3, 4, 5, 6, 7, 1。使用鸡尾酒算法,只需要进行一轮冒泡,即可完成对数组的排序。 - 最坏的情况为O($$n^2$$).也就是V1,V2,V3和V4所遇到的情况,几乎大部分数据都是无序的。
往期文章:
聊聊微服务集群当中的自动化工具www.hulunhao.com



相关:
微信公众号: SH的全栈笔记(或直接在添加公众号界面搜索微信号LunhaoHu)















 9814
9814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









