






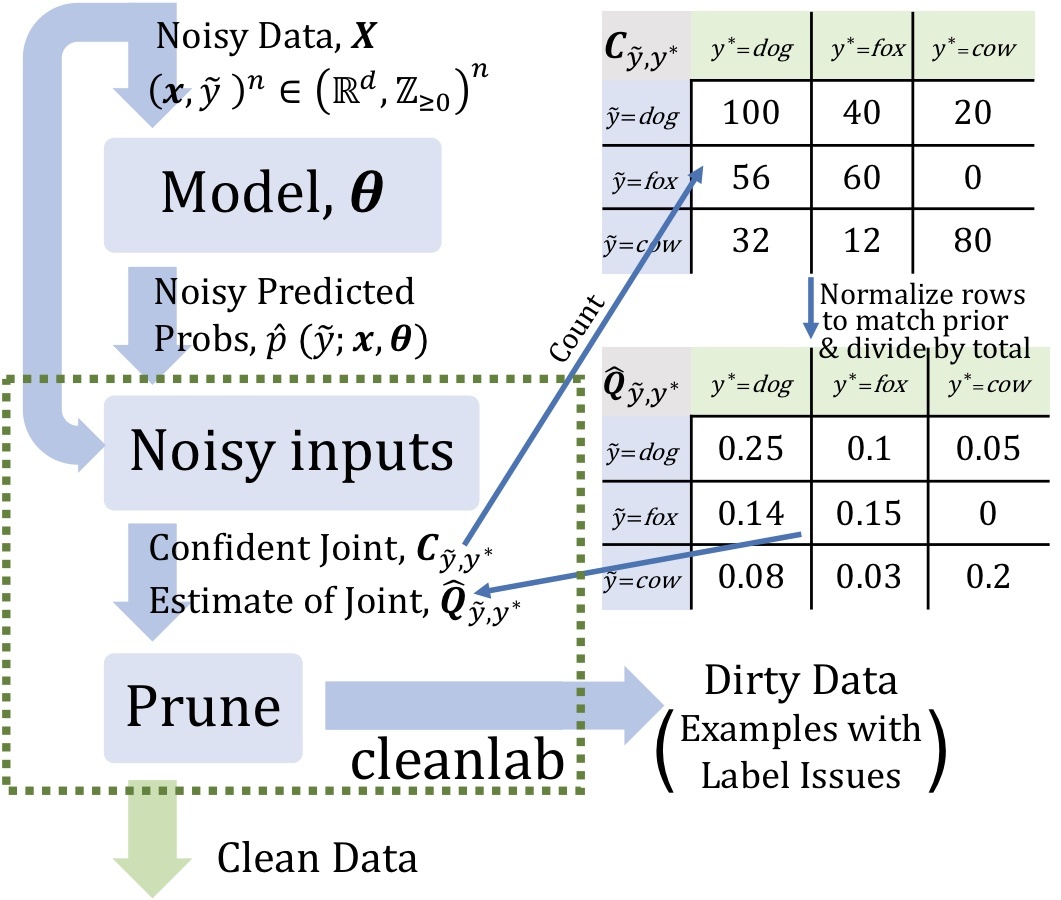
训练数据的质量,对最终训练出来的模型精度,起到了非常重要的作用。数据质量决定了业务效果的上限,而算法只能决定多大程度上逼近这个上限。因此,第一步需要清洗脏数据。
目前基于带噪标签数据的学习方法主要有两大类,一类是直接训练对噪声鲁棒的模型(noise-robust models),另一类方法首先识别出噪声数据,然后基于清洗后的数据训练模型。本文主要关注第二类方法。
a. 基于Confidence Learning识别错误标签
Confidence Learning是一种弱监督学习方法,它能够识别错误标签。Confidence Learning基于分类噪声过程假设(classification noise process ),认为噪声标签是以类别为条件的,仅仅依赖于潜在的正确类别,而不依赖与数据。通过估计给定带噪标签与潜在正确标签之间的条件概率分别来识别错误标签。
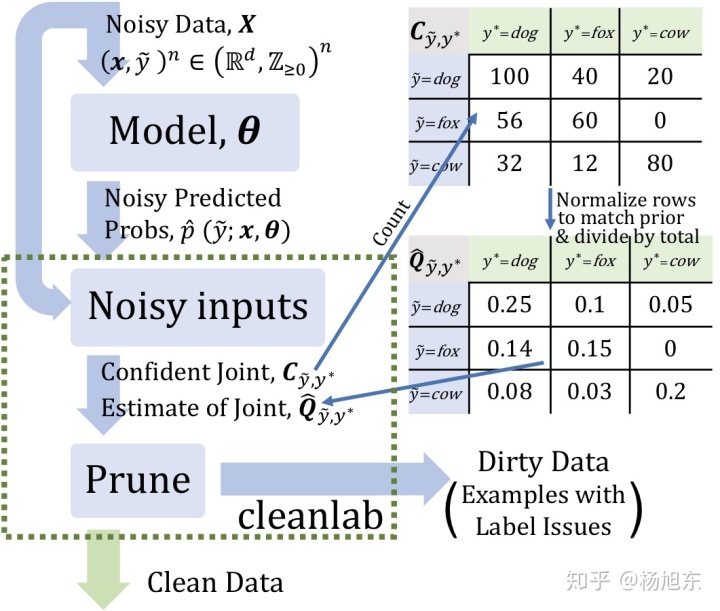
Confidence Learning只依赖两个输入:模型的样本外预测概率和带噪标签。学习过程首先通过预测标签与标注标签的计数矩阵估计带噪标签与潜在正确标签
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1554
1554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









