





这个一篇针对pandas新手的简短入门!!!!
首先导入需要的几个库。
import pandas as pdimport numpy as npimport matplotlib.pyplot as plt创建对象¶
pandas中两种类型:series和dataframe.下面创建两种基本类型。
通过传递一个list来创建Series,pandas会默认创建整型索引
s = pd.Series([1,3,5,6,8])通过传递一个numpy array,日期索引以及列标签来创建一个DataFrame:
dates = pd.date_range('20130101', periods=6) # DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', # '2013-01-05', '2013-01-06'], # dtype='datetime64[ns]', freq='D') df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))ABCD2013-01-01-0.900524-0.302515-0.5417621.5629162013-01-02-0.884117-0.6507410.2173450.2689152013-01-030.2208220.7905270.6921720.7234412013-01-041.2602761.0002970.809801-0.3897132013-01-051.6793811.4686090.360648-0.2408502013-01-060.5678670.2353521.117395-0.604326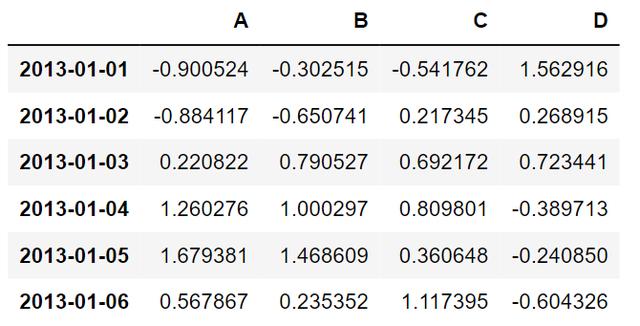
df 结果
通过传递一个能够被转换为类似series的dict对象来创建一个DataFrame:
df2 = pd.DataFrame({ 'A' : 1., 'B' : pd.Timestamp('20130102'), 'C' : pd.Series(1,index=list(range(4)),dtype='float32'), 'D' : np.array([3]*4,dtype='int32'), 'E' : pd.Categorical(["test","train","test","train"]), 'F' : 'foo' })df2.dtypes# A float64# B datetime64[ns]# C float32# D int32# E category# F object# dtype: object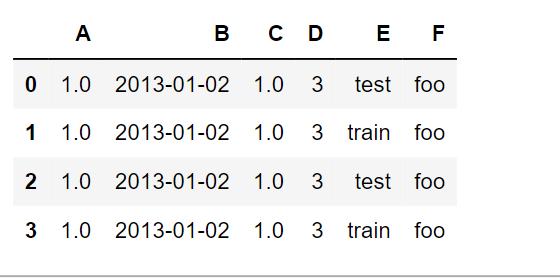
df2
查看数据
查看frame中头部和尾部的几行:
df.head() ## 头部数据 括号内可以填数字表示显示多少行df.tail()## 尾部数据## 显示索引、列名以及底层的numpy数据df.index df.columns df.values# 数据做一个快速的统计汇总df.describe()# 对数据做转置df.T# 排序df.sort_values(by='B')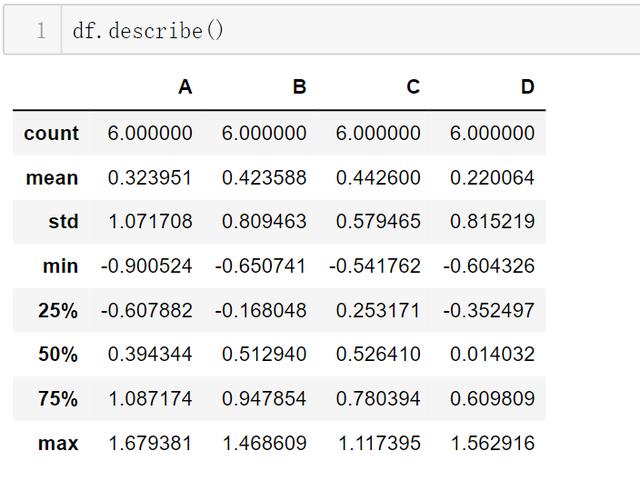
数据选择
# 选择某一列数据,它会返回一个Series,等同于df.A:df['A'] == df.A## 选择某一列数据,它会返回一个Series,等同于df.A:通过标签选取
# 通过标签进行交叉选取:df.loc[dates[0]]# 使用标签对多个轴进行选取df.loc[:,['A','B']]df.loc[:,['A','B']][:3] 前三行# 进行标签切片,包含两个端点df.loc['20130102':'20130104',['A','B']]# 对于返回的对象进行降维处理df.loc['20130102',['A','B']]通过位置选取
# 通过传递整型的位置进行选取df.iloc[3]# 通过整型的位置切片进行选取,与python/numpy形式相同df.iloc[3:5,0:2]# 只对行进行切片df.iloc[1:3,:]# 只对列进行切片df.iloc[:,1:3]# 只获取某个值df.iloc[1,1]布尔索引
# 用某列的值来选取数据df[df.A > 0]赋值
# 赋值一个新的列,通过索引来自动对齐数据s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20130102',periods=6))df['F'] = s1# 通过标签赋值df.at[dates[0], 'A'] = 0# 通过位置赋值df.iat[0,1] = 0# 通过传递numpy array赋值df.loc[:,'D'] = np.array([5] * len(df))缺失值处理
#在pandas中,用np.nan来代表缺失值,这些值默认不会参与运算。#reindex()允许你修改、增加、删除指定轴上的索引,并返回一个数据副本。df1 = df.reindex(index=dates[0:4], columns=list(df.columns)+['E'])df1.loc[dates[0]:dates[1],'E'] = 1# 剔除所有包含缺失值的行数据df1.dropna(how='any')# 填充缺失值df1.fillna(value=5)# 获取值是否为nan的布尔标记pd.isnull(df1)运算
#统计¶#运算过程中,通常不包含缺失值。#进行描述性统计df.mean() #列统计df.mean(1) # 行统计# 对于拥有不同维度的对象进行运算时需要对齐。除此之外,pandas会自动沿着指定维度计算。s = pd.Series([1,3,5,np.nan,6,8], index=dates).shift(2)#2013-01-01 NaN#2013-01-02 NaN#2013-01-03 1.0#2013-01-04 3.0#2013-01-05 5.0#2013-01-06 NaN#Freq: D, dtype: float64# 通过apply()对函数作用df.apply(lambda x:x.max()-x.min())## 频数统计s.value_counts()合并
Concat 连接
pandas中提供了大量的方法能够轻松对Series,DataFrame和Panel对象进行不同满足逻辑关系的合并操作
通过concat()来连接pandas对象
pieces = [df[:3], df[3:7], df[7:]]pd.concat(pieces)Join 合并
类似于SQL中的合并(merge)
pd.merge(left, right, on='key')Append 添加¶
将若干行添加到dataFrame后面
df.append(s, ignore_index=True)分组¶
对于“group by”操作,我们通常是指以下一个或几个步骤:
- 划分 按照某些标准将数据分为不同的组
- 应用 对每组数据分别执行一个函数
- 组合 将结果组合到一个数据结构
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar'], 'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'], 'C' : np.random.randn(8), 'D' : np.random.randn(8)})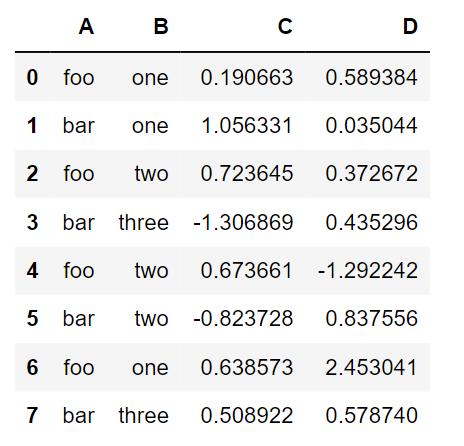
#分组并对每个分组应用sum函数df.groupby('A').sum()#按多个列分组形成层级索引,然后应用函数df.groupby(['A','B']).sum()绘图
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))ts = ts.cumsum()ts.plot()
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=['A', 'B', 'C', 'D'])df = df.cumsum()plt.figure(); df.plot(); plt.legend(loc='best')
获取数据
## 写数据df.to_csv('data.csv')## 读数据pd.read_csv('data.csv')## exceldf.to_excel('data.xlsx', sheet_name='Sheet1')## 有具体需要可以自行查询













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









