






(本文结合《SQL基础教程》整理)
文章结构
- 视图
- 子查询
- 变量子查询
- 关联子查询
- 如何用SQL解决业务问题
- 常见函数
视图
视图的定义:
视图究竟是什么呢?如果用一句话概述的话,就是“从 SQL 的角度来看视图就是一张表”。数据库中的数据实际上会被保存到计算机的存储设备(通常是硬盘)中。因此,我们通过 SELECT 语句查询数据时,实际上就是从存储设备(硬盘)中读取数据,进行各种计算之后,再将结果返回给用户这样一个过程。但是使用视图时并不会将数据保存到存储设备之中,而且也不会将数据保存到其他任何地方。实际上视图保存的是 SELECT 语句。我们从视图中读取数据时,视图会在内部执行该 SELECT 语句并创建出一张临时表,临时表会在客户端和数据库断开连接的时候自动删除。
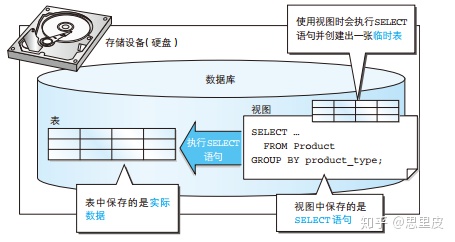
(以上文字和图片整理自:《SQL基础教程》)
视图的优点:
①由于视图无需保存数据,因此可以节省存储设备的容量。
②第二个优点就是可以将频繁使用的 SELECT 语句保存成视图,减少重复书写。视图创建好之后,只需在 SELECT 语句中进行调用。在进行汇总以及复杂的查询条件导致 SELECT 语句非常庞大时,使用视图可以大大提高效率。
③视图中的数据会随着原表的变化自动更新,视图就是封装好的SELECT 语句,定义视图时可以使用任何 SELECT 语句,既可以使用 WHERE、 GROUP BY、 HAVING,也可以通过 SELECT * 来指定全部列。
如何创建视图:【也是在新建查询中创建,然后刷新即可】


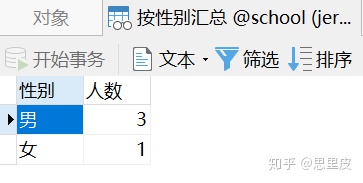
注意:SELECT 语句需要书写在 AS 【像,和...一样】关键字之后。 SELECT 语句中列的排列顺序和视图中列的排列顺序相同。
如何使用视图:

如何删除视图:

注意事项:
①在 FROM 子句中使用视图的查询,通常有如下两个步骤:

②可以以视图为基础创建视图的多重视图,实际使用中,应该尽量避免在视图的基础上创建视图。这是因为对多数 DBMS 来说,多重视图会降低 SQL 的性能。
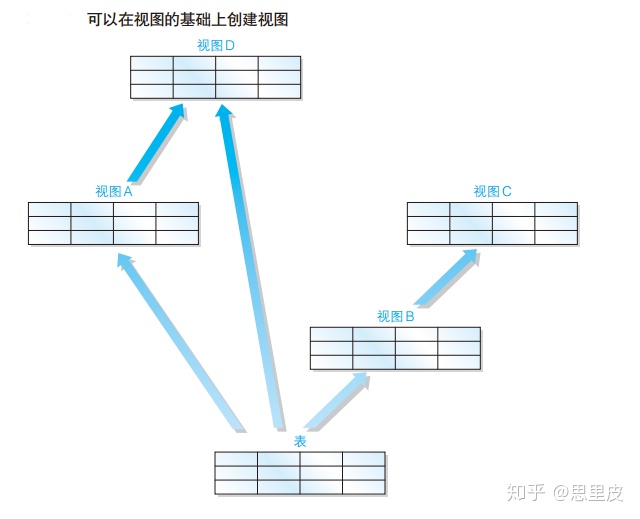
③定义视图时不能使用ORDER BY子句。
④视图和表需要同时进行更新,因此通过汇总得到的视图无法进行更新(详细原因见《SQL基础教程》P156)。
子查询
子查询定义:子查询就是将用来定义视图的SELECT语句直接用于FROM子句当中,子查询就是一次性视图(SELECT语句)。所以与视图不同,子查询在SELECT语句执行完毕之后就会消失。
FROM子句之后的子查询
案例1:要求根据商品种类(product_type)对数据进行汇总。
先回忆一下视图的创建和使用的过程:
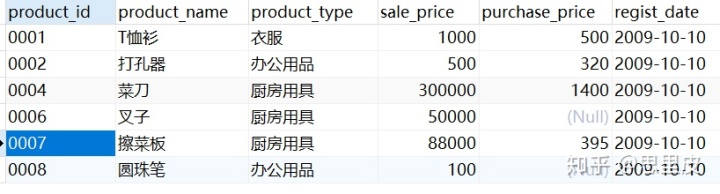
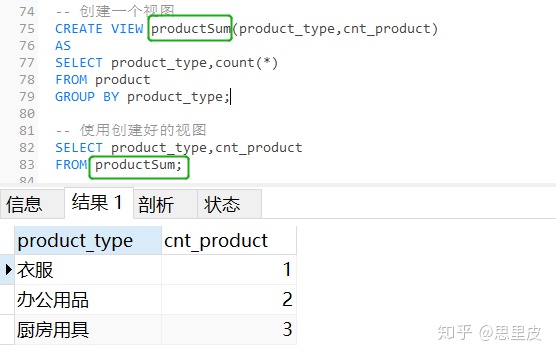
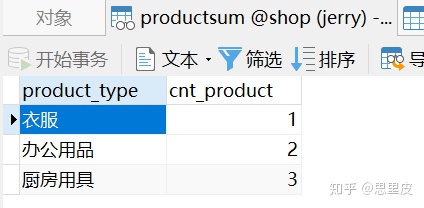
再来看看能够实现同样功能的子查询的创建和使用的过程:

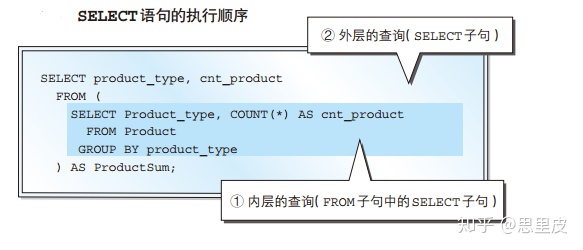

案例2:找出商品总数量为3的商品品类名称。
子查询可以嵌套【但是不建议】:

我们尝试解释一下上述语句的含义:
①最内层的子查询(ProductSum)与之前一样,根据商品种类(product_type)对数据进行汇总。
②外层的子查询将商品数量(cnt_product)限定为 3,结果就得到了 1 行厨房用具的数据,如下图。
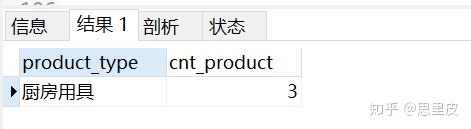
WHERE子句中的子查询
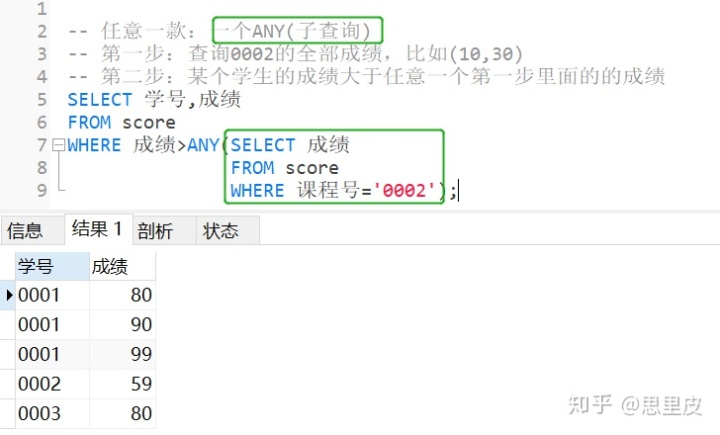
案例3:哪些学生的成绩比课程0002的全部成绩里的任意一个高?【ANY (子查询)括号里的数据以集合形式呈现】
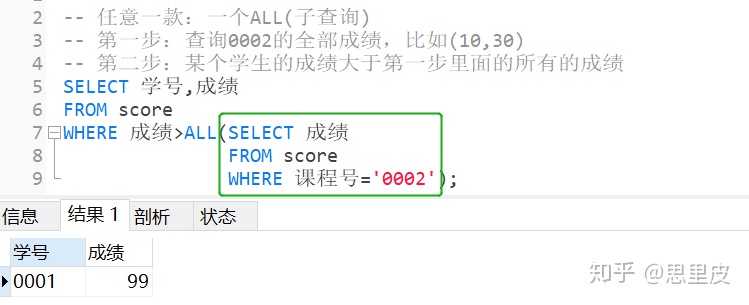
案例4:哪些学生的成绩比课程0002的全部成绩里都高?【all(子查询)】
需要注意的是:子查询只是充当了视图的功能并不会产生新的视图,就像视图仅仅创建了一张临时表是一个道理。
标量子查询
标量子查询的定义:标量就是单一的意思,标量子查询就是返回单一值的子查询。
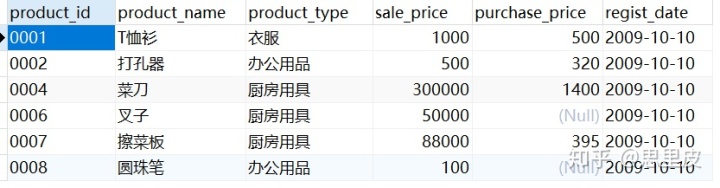
案例:
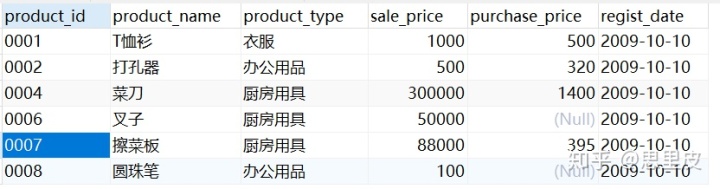
根据上表的数据结构考虑一个问题:查询出销售单价高于平均销售单价的商品。
根据常规思维,几乎会本能的在WHERE子句中使用聚集函数。
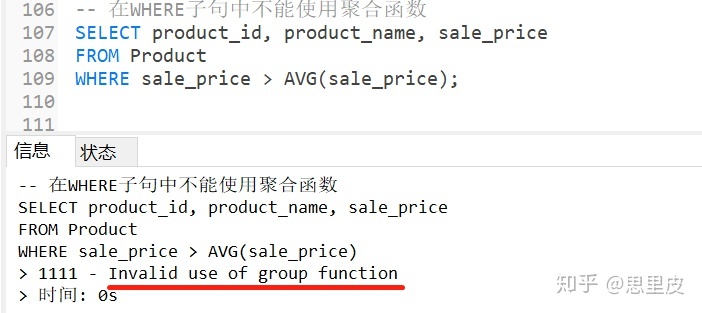
如下图,我们发现SELECT 语句的查询结果是单一的值(73266.6667)。因此,我们可以直接将这个结果用到之前失败的查询之中。
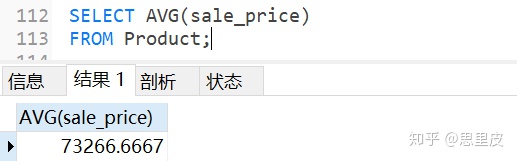
结合后的效果如下:
需要注意的是:标量子查询的书写位置并不仅仅局限于 WHERE 子句中,通常任何可以使用单一值的位置都可以使用【类似一个常数】。也就是说, 能够使用常数或者列名的地方,无论是 SELECT 子句、GROUP BY 子句、 HAVING 子句,还是ORDER BY 子句,几乎所有的地方都可以使用。
案例1:将全部商品的单价加入原表格【我们将子查询的语句放到了SELECT子句后】:
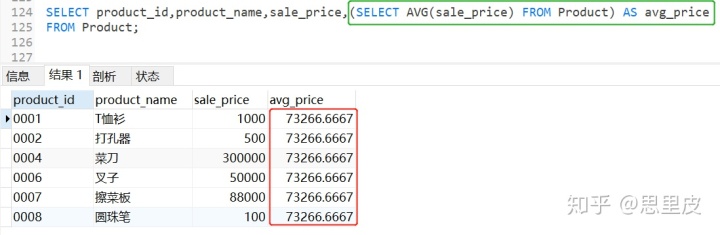
从上述结果可以看出,在商品一览表中加入了全部商品的平均单价。有时我们会需要这样的数据。
案例2:选取出销售均价高于全部商品的平均销售单价的商品种类【我们将子查询的语句放到了HAVING子句后】。
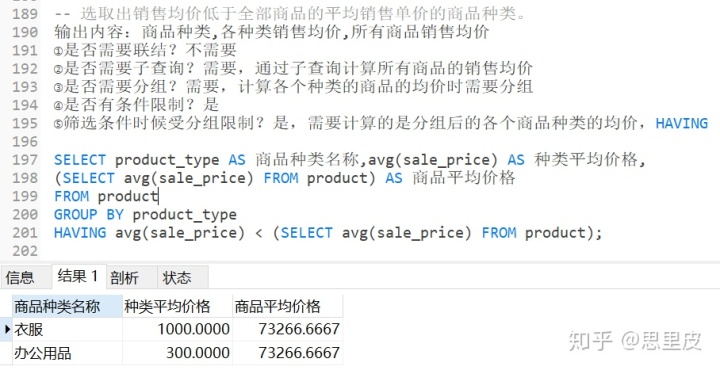
标量子查询注意事项:
①标量子查询绝对不能返回多行结果。也就是说,如果子查询返回了多行结果,那么它就不再是标量子查询,而仅仅是一个普通的子查询了。
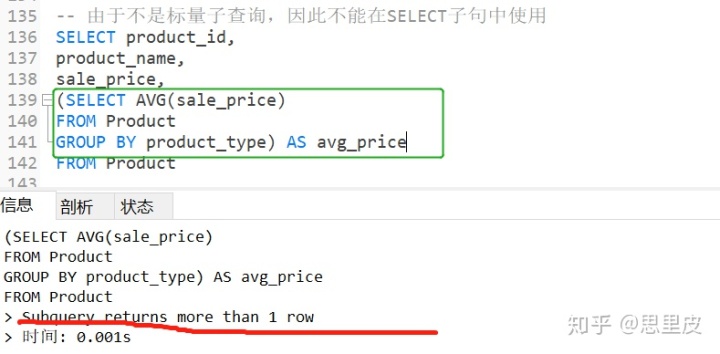
关联子查询
1.关联子查询:关联子查询会在涉及分组后的组内再计算的场景。
2.问题引入:
案例1:选取出各商品种类中高于该商品种类的平均销售单价的商品。
'商品种类的平均销售单价需要分组后再计算,需要用到关联子查询'
问题拆解:①找出每个商品种类的平均销售单价。②将各自商品与自己对应的商品种类的平均销售单价进行比较。
第一步:找出每个商品种类的平均销售单价。
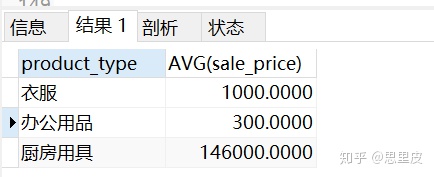
第二步:将各自商品与自己对应的商品种类的平均销售单价进行比较。
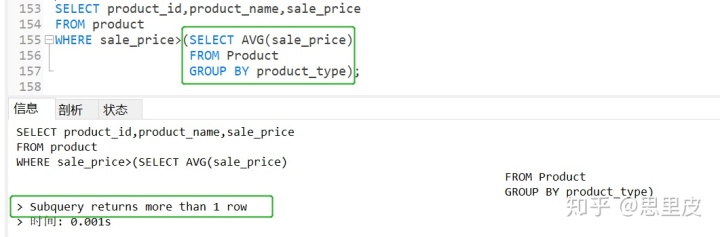
如果我们使用前一节(标量子查询)的方法,直接把上述SELECT 语句使用到 WHERE 子句当中的话,就会发生错误。出错原因前一节已经讲过了,该子查询会返回 3 行结果(1000、300、146000),并不是标量子查询。
正确的做法是使用关联子查询:
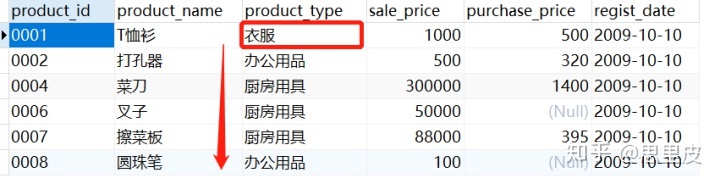
其中红色方框的运行逻辑是:
①执行到红框部分时,先从父查询的P1表中取出第一行值,并且传递到子查询中,然后第一行记录中取出product_type值'衣服'【p1.product_type】,于是红框等式右边的值替换为:'衣服',于是子查询语句实际变成如下所示,并且将该次完整的子查询结果返回给外层的父查询。
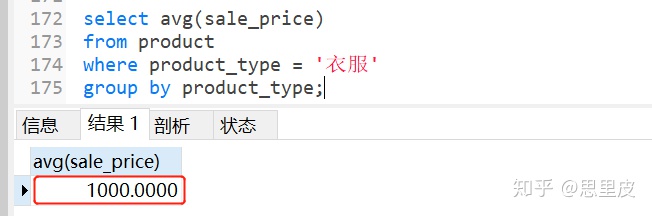
②将avg(sale_price)=1000作为返回值,同时限定条件:product_type='衣服'【体现关联】,返回到父查询中去,父查询实际上成为:
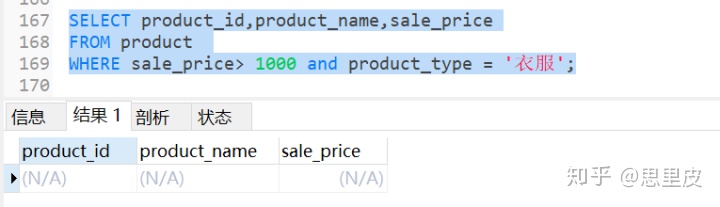
③执行该次父查询,我们发现,因为衣服只有一个品类,商品种类的均值就是本身,所以查询不到符合条件(大于1000且类型为衣服)。
④我们按上面相同的步骤,再从父查询的P1表中取出第二行记录传入子查询,得到第二行记录中product_type的值为'办公用品'【p1.product_type】,再重复上述几步,我们发现'办公用品'中的打孔器是符合筛选条件的,拆分的步骤大概如下。
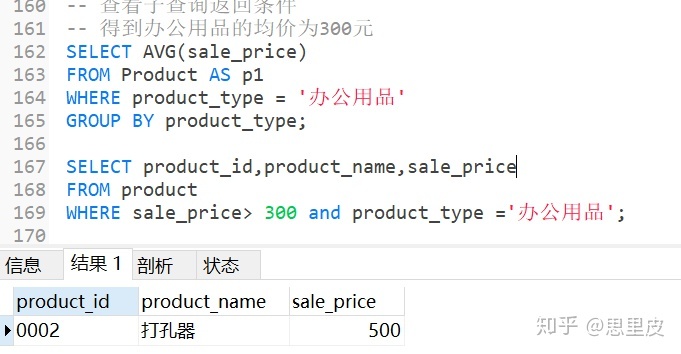
⑤最后,循环以上步骤,将外部p1的每一行都传递到子查询,子查询依次读取外部查询传递来的每一行值,并将其用到子查询上,直到外部查询所有的行都处理完为止.然后返回查询最终查询结果:
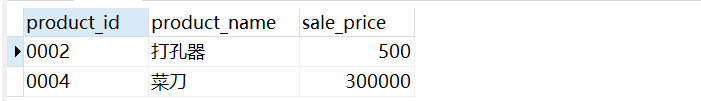
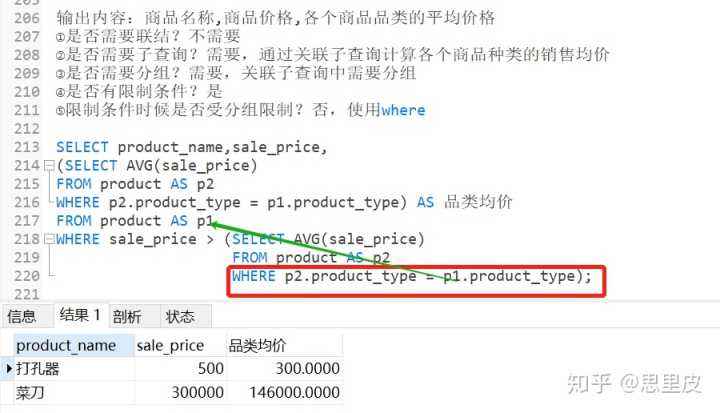
案例2:查询每个商品的价格和它们所处种类的平均价格。
'所处种类的平均价格需要分组后在计算,需要关联子查询'
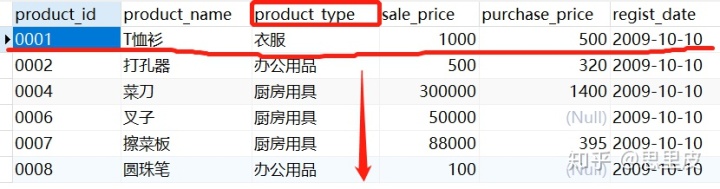
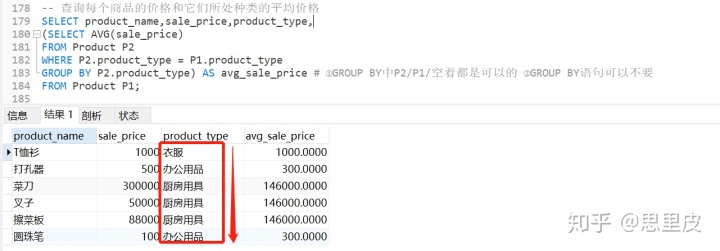
总结:①关联子查询主要使用场景为:分组后需要进行组内操作的场景,组内的操作会由关联子查询完成,同组的类似工作,靠父查询协调,遇到关联子查询的问题时,需要清晰明白各层查询的具体功能。②关联子查询的执行原理:关联子查询会引用外部查询中的一列或多列.在执行时,外部查询的每一行都被一次一行地传递给子查询.子查询依次读取外部查询传递来的每一行值,子查询为每一行数据执行一次并返回它的记录,直到父查询所有的行都处理完为止,然后返回查询结果。
关联子查询和普通子查询的区别:
①关联子查询的执行依赖于外部查询的数据,外部查询执行一行,子查询就执行一次。此外,在关联子查询中是信息流是双向的。外部查询的每行数据传递一个值给子查询,然后子查询为每一行数据执行一次并返回它的记录。然后,外部查询根据返回的记录做出决策。
②非相关子查询是独立于外部查询的子查询,非相关子查询是独立于外部查询的子查询,子查询总共执行一次,执行完毕后将值传递给外部查询。
③关联子查询中: 1. 先执行外层查 2. 再执行内层查询
④普通子查询中: 1. 先执行内层查询 2. 再执行外层查询
如何用SQL解决业务问题
①翻译成大白话
②写出分析思路
③写出对应的SQL子句
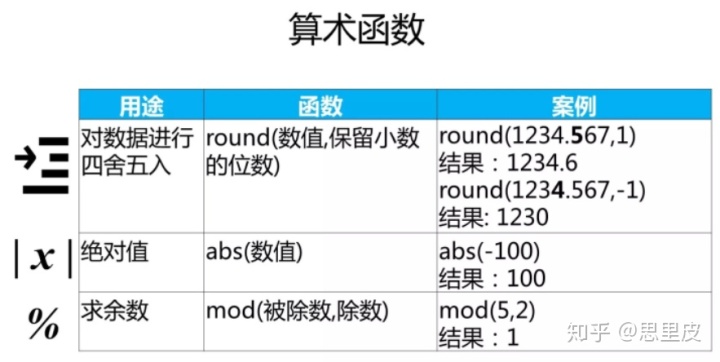
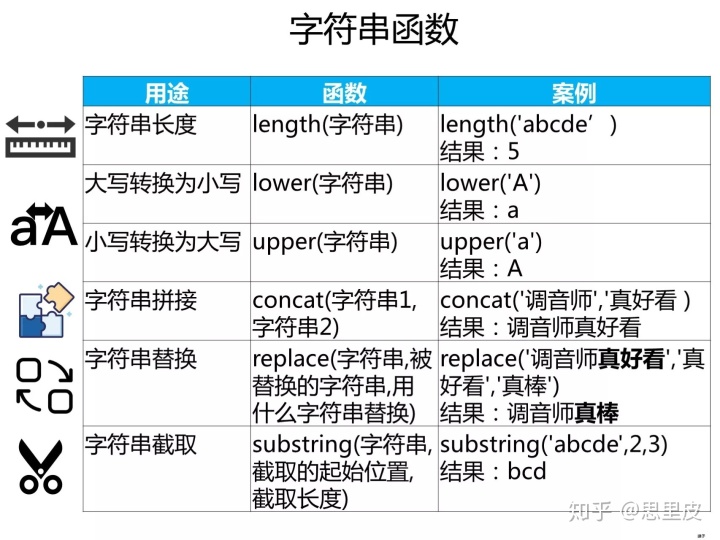
各种函数

日期函数:

Sqlzoo练习:
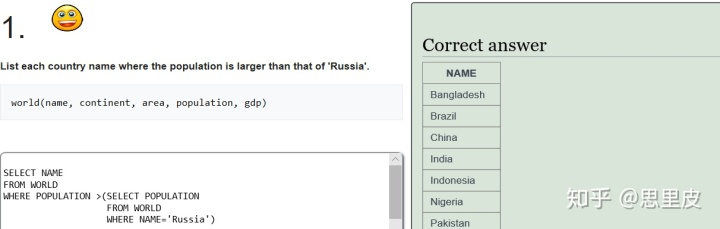
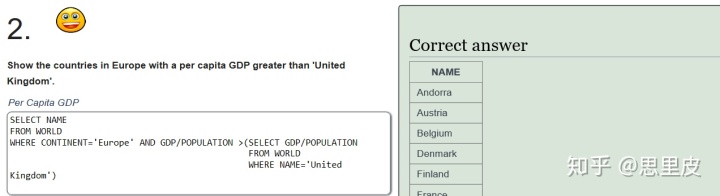
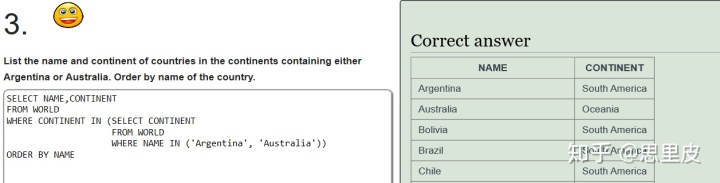
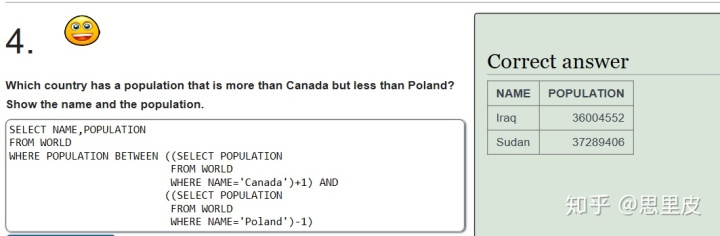
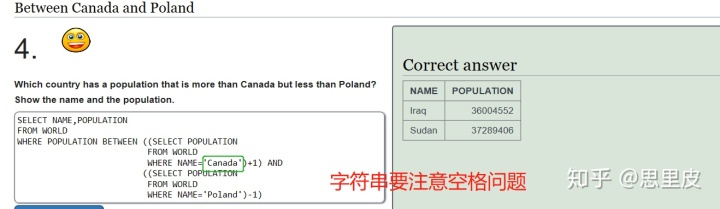

不知道为什么出错......

那为什么上面MAX()函数没有出现问题呢?因为当列名作为参数传入聚集函数的时候,那么在计算之前就已经把NULL 排除在外了。因此,无论有多少个 NULL 都会被无视。但是如果是COUNT(*)这样的形式,NULL会纳入运算。
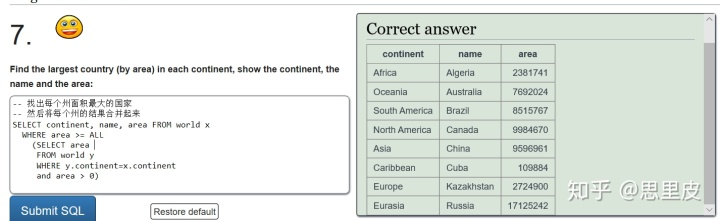
尝试解析一下整个运作流程,加深对关联子查询的理解和记忆。
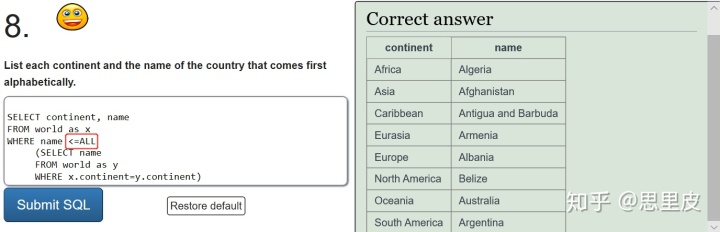
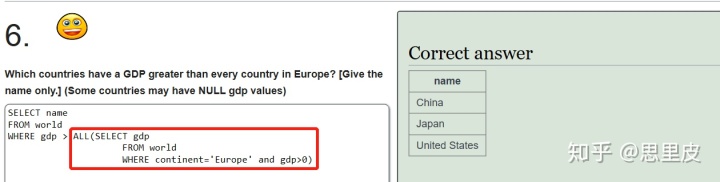
注意的ALL的灵活使用,若此处改成>=ALL,则可以选出每个州,排名最后的那个国家。


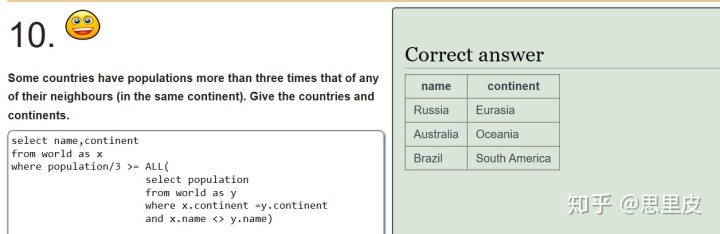
第十题中,子查询引用了外部查询的两列【continent】【name】。














 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









