






A loop within a loop;
A pointer to a pointer;
A recursion within a recursion;

《The C Programming Language》一书之所以被列为经典,不仅在于这是 C 语言发明者的著作,更在于不到三百页卻涵盖 C 语言的精髓,佐以大量范例,循序渐进。更奇妙的是,连索引页 (index) 也能隱藏学问。
上图是《The C Programming Language》的第 269 页,是索引页面的一部分,注意到 recursion (递归)一字出现在书本的第 86, 139, 141, 182, 202, 以及 269 页,后者恰好就是 recursion 出现的页码,符合递归定义!
递归让你直觉地表示特定模式
观赏影片 Binary, Hanoi and Sierpinski - Part I 和 Binary, Hanoi, and Sierpinski - Part II,记得开启的字幕(这两个链接无法访问)
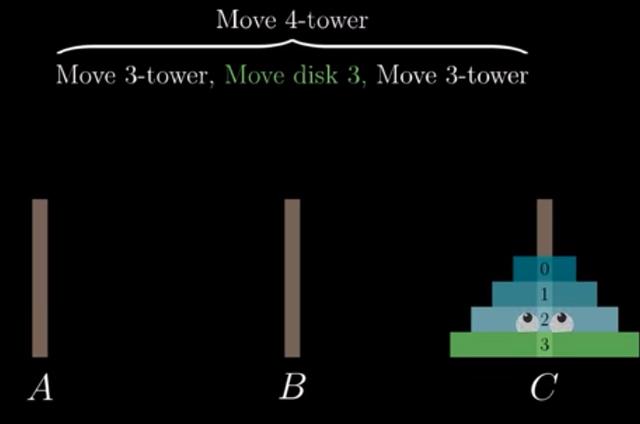

电脑程序中,子程式直接或间接调用自己就称为递归。递归算不上演算法,只是程序流程控制的一种。程序的执行流程只有两种:
- 循序,分支(循环)
- 调用子程序(递归)
循环是一种特別的分支,而递归是一种特別的子程序调用。
不少初学者以及教初学者的人把递归当成是复杂的演算法,其实单纯的递归只是另一种函数定义方式而已,在程序指令上非常简单。初学者为什么觉得递归很难呢?因为他跟人类的思考模式不同,电脑的两种思维模式:穷举与递归(enumeration and recursion),穷举是我们熟悉的而递归是陌生的,而递归为何重要呢?因为他是思考好的演算法的起点,例如分治与动态规划。
- 分治:一刀均分左右,两边各自递归,返回重逢之日,真相合并之时。
分治 (Divide and Conquer) 是种运用递归的特性来设计演算法的策略。对于求某问题在输入 S 的解 P(S) 时,我们先将 S 分割成两个子集合 S1 与 S2,分別求其解 P(S1) 与 P(S2),然后再将其合并得到最后的解 P(S)。要如何计算 P(S1) 与 P(S2) 呢?因为是相同问题较小的输入,所以用递归来做就可以了。分治不一定要分成两个,也可以分成多个,但多数都是分成两个。那为什么要均分呢?从下面的举例说明中会了解。
从一个非常简单例子来看:在一个数组中如何找到最大值。循环的思考模式是:从前往后一个一个看,永远记录着目前看到的最大值。
m = a[0];for (i = 1 ; i < n; i++) m = max(m, a[i]);分治思考模式:如果我们把数组在 i 的位置分成前后两段 a[0,i−1] 与a[i,n],分別求最大值,再返回两者较大者。切在哪里呢?如果切在最后一个的位置,因为右边只剩一个无须递归,那么会是
int find_m1(int n) { if (n == 0) return a[0]; return max(find_m1(n - 1), a[n]);}这是个尾端递归(Tail Recursion),在有编译最佳化的狀況下可跑很快,其实可发现程序的行为就是上面那个循环的版本。若我们将程序切在中点:
int find_m2(int left, int right) { // 范围=[left, right) 用左闭右开区间 if (right - left == 1) return a[left]; int mid = (left + right) / 2 ; return max(find_max(left, mid), find_max(mid, right);}效率一样是线性时间,会不会递归到 stack overflow 呢?放心,如果有200 层递归数组可以跑到 2的200次方,地球已毁灭。
再来看个有趣的问题:假设我们有一个程序比赛的排名清单,有些选手是女生有些是男生,我们想要计算有多少对女男的配对是男生排在女生前面的。若以 0 与 1 分別代表女生与男生,那么我们有一个 0/1 序列 a[n],要计算
Ans = | {(a[i], a[j]) | i < j 且 a[i] > a[j]} |循环的思考方式:对于每一个女生,计算排在他前面的男生数,然后把它全部加起来就是答案。
for (i = 0, ans = 0 ; i < n ;i++) { if (a[i]==0) { cnt = num of 1 before a[i]; ans += cnt; }}效率取决于如何计算 cnt。如果每次拉一个循环来重算,时间会跑到 O(n2),如果利用类似前缀和 (prefix-sum) 的概念,只需要线性时间。
for (i = 0, cnt = 0, ans = 0 ; i 接下来看分治思考模式。如果我们把序列在 i 处分成前后两段 a[0,i−1] 与 a[i,n],任何一个要找的 (1, 0) 数对只可能有三个可能:都在左边、都在右边、或是一左一右。所以我们可左右分別递归求,对于一左一右的情形,我们若知道左边有 x 个 1 以及右边有 y 个 0,那答案就有 xy 个。递归终止条件是什么呢?剩一个就不必找下去。
int dc(int left, int right) { // 范围=[left,right) 惯用左闭右开区间 if (right - left < 2) return 0; int mid = (left + right) / 2; // 均勻分割 int w = dc(left, mid) + dc(mid, right); 计算x = 左边几个 1, y = 右边几个 0 return w + x * y;}时间复杂度呢?假设把范围内的数据重新看一遍去计算 0 与 1 的数量,那需要线性时间,整个程序的时间变成 T(n)=2T(n/2)+O(n),結果是 O(nlogn),不好。比循环的方法差,原因是因为我们计算 0/1 的数量是重复计算。我们让递归也回传 0 与 1 的个数,效率就会改善了,用 Python 改写:
def dc(left, right): if right - left == 1: if ar[left]==0: return 0, 1, 0 # 逆序數,0的數量,1的數量 return 0, 0, 1 mid = (left + right) // 2 #整數除法 w1, y1, x1 = dc(left,mid) w2, y2, x2 = dc(mid,right) return w1 + w2 + x1 * y2, y1 + y2, x1 + x2时间效率是 T(n)=2T(n/2)+O(1),所以结果是 O(n)。
如果分治可以做的循环也可以,那又何必学分治?第一,复杂的问题不容易用循环的思考找到答案;第二,有些问题循环很难做到跟分治一样的效率。上述男女对的问题其实是逆序数对问题的弱化版本:给一个数字序列,计算有多少逆序对,也就是
| {(a[i], a[j]) | i < j 且 a[i] > a[j]} |。循环的思考模式一样去算每一个数字前方有多少大于它的数,直接做又搞到O(n^2),有没有办法像上面男女对问题一样,记录一些简单的数据来减少计算量呢?你或许想用二分查找,但问题是需要重排序,就我所知,除非搞个复杂的数据结构,否则没有简单的办法可以来加速。那么来看看分治。基本上的想法是从中间切割成两段,各自递归计算逆序数并且各自排序好,排序的目的是让合并时,对于每个左边的元素可以笨笨地运用二分查找去算右边有几个小于它。
LL sol(int le, int ri) { // 区间 = [le,ri) if (ri-le == 1) return 0; int mid = (ri + le) / 2; LL w = sol(le, mid) + sol(mid, ri); LL t = 0; for (int i = le; i < mid; i++) t += lower_bound(ar + mid, ar + ri, ar[i]) - (ar + mid); sort(ar + le, ar + ri); return w + t;}时间复杂度呢?即使我们笨笨地把两个排好序的序列再整个重排,T(n)=2T(n/2)+O(nlogn),结果是O(nlog 2 (n)),十万笔数据不需要一秒,比循环的方法好多了。为什么说笨笨地二分查找与笨笨地重新排序呢?对于两个排好序的东西要合并其实可以用线性时间。那二分查找呢?沿路那么多个二分查找其实可以维护两个注标一路向右就好了。所以事实上不需要复杂的数据结构可以做到O(nlogn),熟悉演算法的人其实看得出来,这个方法基本上就是很有名的merge sort,跟quick sort 一样常拿来当作分治的范例。另外,如果merge sort的分割方式如果是[left,right−1][left,right−1] [right−1,right][right−1,right],右边只留一个,那就退化成insertion sort 的尾端递回。
注:计算递归的时间需要解递归函数,这是有点复杂的事情。好在大多数常见的有公式解。
Tail recursion 是递归的一种特殊形式,子程序只有在最后一个动作才调用自己。以演算法的角度来说,recursion tree 全部是一脉单传,所以间复杂度是线性个该子程序的时间。不过递归是需要系统使用stack 来储存某些数据,于是还是会有stack overflow 的问题。但是从编译器的角度来说,因为最后一个动作才调用递归,所以很多stack 数据是没用的,所以它是可以被优化的。基本上,优化以后就不会有时间与空间效率的问题。
注意: Python 没有tail recursion 优化,而且stack 深度不到1000。C 要开编译器开启最佳化才会做tail recursion 优化。















 1137
1137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









