






前几天与别人交流爬虫经验,对方发过来一个urllib实现的爬虫,顿时感觉很有古老,想起当年初学爬虫,也是用的urllib+beautifulsoup玩了好几个月。自己也试着实现了两个。这里发下实现豆瓣的那个。
分析网页
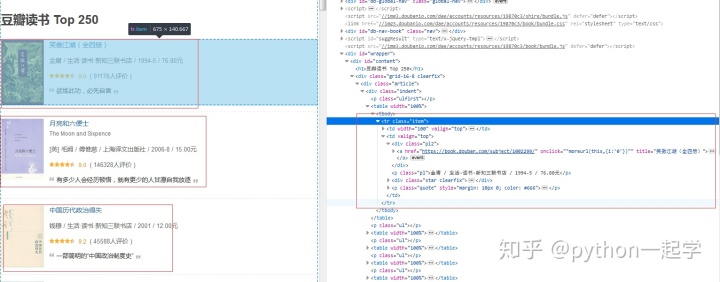
所有的关键信息都在红框的html内,看下内部如下:
<td width="100" valign="top">
<a class="nbg" href="https://book.douban.com/subject/1002299/" onclick="moreurl(this,{i:'0'})">
<img src="https://img9.doubanio.com/view/subject/s/public/s2157335.jpg" width="90">
</a>
</td>
<td valign="top">
<div class="pl2">
<a href="https://book.douban.com/subject/1002299/" onclick=""moreurl(this,{i:'0'})"" title="笑傲江湖(全四册)">
笑傲江湖(全四册)
</a>
</div>
<p class="pl">金庸 / 生活·读书·新知三联书店 / 1994-5 / 76.80元</p>
<div class="star clearfix">
<span class="allstar45"></span>
<span class="rating_nums">9.0</span>
<span class="pl">(
91178人评价
)</span>
</div>
<p class="quote" style="margin: 10px 0; color: #666">
<span class="inq">欲练此功,必先自宫</span>
</p>
</td>要获取的内容包括,书名,图片,作者,译者,出版社,日期,价格,评分,评价人数。先看下urllib如何打开网页,获取内容。
urllib的使用
USER_AGENTS = [
'Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16.2',
'Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.14.1) Presto/2.12.388 Version/12.16',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2919.83 Safari/537.36']
headers = {
'user-agent' : random.choice(USER_AGENTS),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
#'Referer': 'https://www.baidu.com/',
}
#打开网页
request = urllib.request.Request(url=url, headers=headers)
try:
response = urllib.request.urlopen(request)
except urllib.error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='n')
except urllib.error.URLError as e:
print(e.reason)
else:
print('Request Successfully!')
return response.read().decode('utf-8')基本使用,结合try能抛出一些错误,无错误则返回内容(这个库用的我都烦了,这里不深入,网上很多内容)。
反爬的设置有的包括加入cookie,随机头,随机代理等内容,这里只涉及到随机头。还有请求的时候,设置随机休眠3-5s,免得出发反爬。代码开始:
if __name__ == '__main__':
base_url = 'https://book.douban.com/top250?start={}'
for offset in range(0, 10):
next_url = base_url.format(offset * 25)
response = parse_html(next_url)#返回网页内容
temp = get_data(response)#获取关键数据
time.sleep(random.randint(3, 5))#随机休眠
save_csv(temp)难么如何获取关键信息的方法如下,这里花了大概2小时,beautifulsoup使用方法一边看一边调试,获取作者,译者,出版社,出版时间,价格这里,格式比较固定长度在3-5个,所以用了这类型的方法,想不到更好的了。
def get_data(response):
re_int = "[1-9]d*"
#解析网页
soup = BeautifulSoup(response, 'lxml')
items = soup.find_all('tr', {'class':"item"})
#需要保存的字段
item_list = []
for item in items:
'''
没一本书都包含在一个item中,item下有的内容都在td中。
每一个td下的内容都有以下的代码获取
'''
item_data = item.find_all('td')
#书名
title = item_data[1].find('div', {'class':'pl2'}).a.get_text().replace('t', '').replace('n', '').replace(' ', '')
#评分
rating_nums = item_data[1].find('span', {'class':'rating_nums'}).string.replace('t', '').replace('n', '')
#评价人数
comment_nums = item_data[1].find('span', {'class':'pl'}).string
comment_nums = re.search(re_int, comment_nums).group()
#图片链接
img = item_data[0].img['src']
#获取作者,译者,出版社,出版时间,价格
result = item_data[1].p.string.split('/')
if len(result) <= 3:
author = ''
fan_yi = ''
chu_ban = result[0]
chu_time = result[1]
jia_ge = result[2]
elif len(result) == 4:
author = result[0]
fan_yi = ''
chu_ban = result[1]
chu_time = result[2]
jia_ge = result[3]
elif len(result) == 5:
author = result[0]
fan_yi = result[1]
chu_ban = result[2]
chu_time = result[3]
jia_ge = result[4]
else:
author = ""
fan_yi = ""
chu_ban = ""
chu_time = ""
jia_ge = ""
item_list.append([title, author, fan_yi, chu_time, rating_nums, comment_nums, chu_ban, jia_ge, img])
return item_list这小爬虫就这么写完了,关键在beautifulsoup的使用,urllib的库会使用就可以,能实现打开网页,获取信息的库不止这个,还是推荐reequests。















 1651
1651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









