







1.文档编写目的
内容概述
1.测试环境准备
2.配置StreamSets
3.创建Pipline及测试
4.总结
测试环境
1.RedHat7.3
2.CM和CDH版本为cdh5.13.3
3.Kafka2.2.0(0.10.0)
4.StreamSets3.3.0
前置条件
1.集群已启用Sentry
2.测试环境准备
1.准备测试的JSON数据
{
"school": 1,
"address": 2,
"no": "page",
"class": 3,
"students": [{
"name": "page1",
"teacher": "larry",
"age": 40
}, {
"name": "page2",
"teacher": "larry",
"age": 50
}, {
"name": "page3",
"teacher": "larry",
"age": 51
}]
}
(可左右滑动)
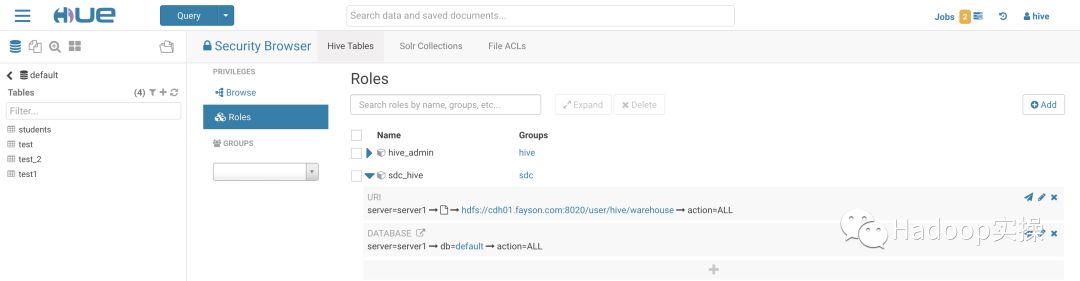
2.为sdc用户授权
由于集群已启用Sentry,所以这里需要为sdc用户授权,否则sdc用户无法向Hive库中创建表及写入数据
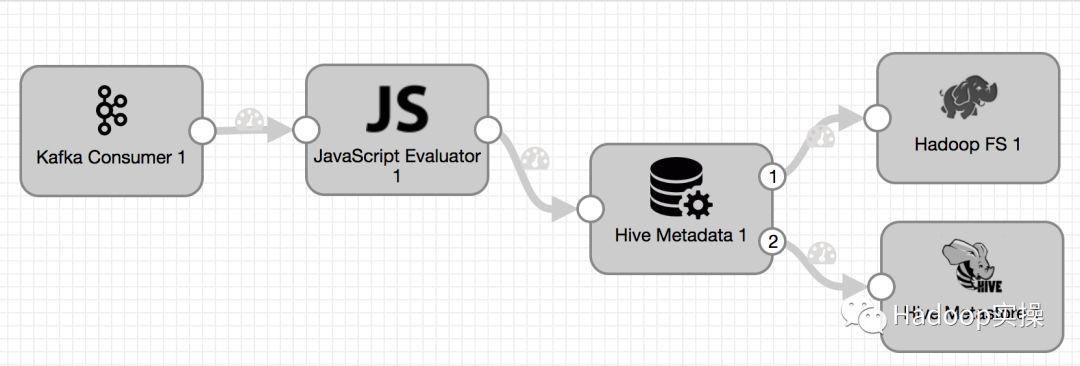
3.创建StreamSets的Pipline
1.登录StreamSets,创建一个kafka2hive_json的Pipline

2.在Pipline流程中添加Kafka Consumer作为源并配置Kafka基础信息
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









