







管道概念与设计
什么是管道?
管道描述了从源头系统到目标系统的数据流,并定义了在此过程中如何转换数据。
可以使用单个origin(初始)阶段表示源头系统,使用多个processor(处理器)阶段转换数据,使用多个destination(目标)阶段表示目标系统。
在开发管道时,可以使用Development Stages(开发阶段)提供示例数据并生成错误以测试错误处理。您还可以使用data preview(数据预览)来确定阶段如何通过管道更改数据。
可以使用executor阶段执行事件触发的任务执行或保存事件信息。要处理大量数据,可以使用多线程管道或集群模式管道。
在写入Hive、parquet或PostgreSQL的管道中,您可以实现一个数据漂移解决方案,它可以检测传入数据的漂移并更新目标系统中的表。
启动管道时,Data Collector将运行管道,直到停止管道或关闭数据收集器为止。可以使用Data Collector运行多个管道。
在管道运行时,您可以监视管道,以验证管道是否按预期执行。您还可以定义指标和数据规则以及警报,以便在达到某些阈值时通知您。
传输中的数据
数据成批地通过管道。它是这样工作的:
origin在从源头系统读取数据或作为数据到达时,创建批处理,并记录偏移量。偏移量是origin停止读取的位置。
当批已满或批等待时间过期时,origin发送批数据。批数据在管道中从一个处理器移动到另一个处理器,直到到达管道目的地。
目的地将批数据写入目标系统,Data Collector在内部提交偏移量。根据管道交付保证,Data Collector要么在向任何目标系统写入数据时立即提交偏移量,要么在收到所有目标系统的写入确认之后提交偏移量。在偏移量提交之后,origin阶段创建一个新批处理。
注意,这描述了一般的管道行为。根据特定的管道配置,行为可能会有所不同。例如,对于Kafka消费者,偏移量存储在Kafka或ZooKeeper中。对于不存储数据的源头系统,比如Omniture和HTTP Client,不会存储偏移量,因为它们不相关。
单线程和多线程管道
上面的信息描述了一个标准的单线程管道—origin创建一个批数据并通过管道传递它,只在处理完前一批数据后,创建一个新批数据。
一些origins可以生成多个线程,以支持在多线程管道中进行并行处理。在多线程管道中,可以配置origin来创建要使用的线程数量或并发量。Data Collector基于管道Max Runners(最大运行器)属性创建许多管道运行器来执行管道处理。每个线程连接到origin系统,创建一批数据,并将批数据传递给可用的管道运行器。
每个管道运行器一次处理一个批处理,就像在单个线程上运行的管道一样。当数据流变慢时,管道运行程序会无所事事地等待,直到需要它们时才会运行,并定期生成一个空批处理。您可以配置Runner Idle Time管道属性,以指定时间间隔或选择不生成空批处理。
本指南中所有关于管道的一般引用都描述了单线程管道,但是这些信息通常适用于多线程管道。有关特定于多线程管道的详细信息,请参见多线程管道概述。
交付保证(语义)
在配置管道时,需要定义如何处理数据:是否要防止数据丢失或数据重复?
Delivery Guarantee(交付保证)管道属性提供以下选择:
至少一次
确保管道处理所有数据。
如果失败导致Data Collector在处理一批数据时停止,当它重新启动时,它将重新处理该批数据。此选项可确保不丢失任何数据。
使用此选项Data Collector在收到来自目标系统的写确认后提交偏移量。如果在Data Collector将数据传递到目标系统之后,但在收到确认并提交偏移量之前发生故障,那么目标系统中最多可能复制一个批处理数据。
最多一次
确保数据不会被处理一次以上。
如果一个故障导致Data Collector在处理一批数据时停止,那么当它启动时,它将开始处理下一批数据。此选项避免了由于重新处理而导致目标中的数据重复。
使用此选项,Data Collector在写入后提交偏移量,而无需等待目标系统的确认。如果在Data Collector将数据传递到目的地并提交偏移量后发生故障,可能最多有一批数据不会写入目标系统。
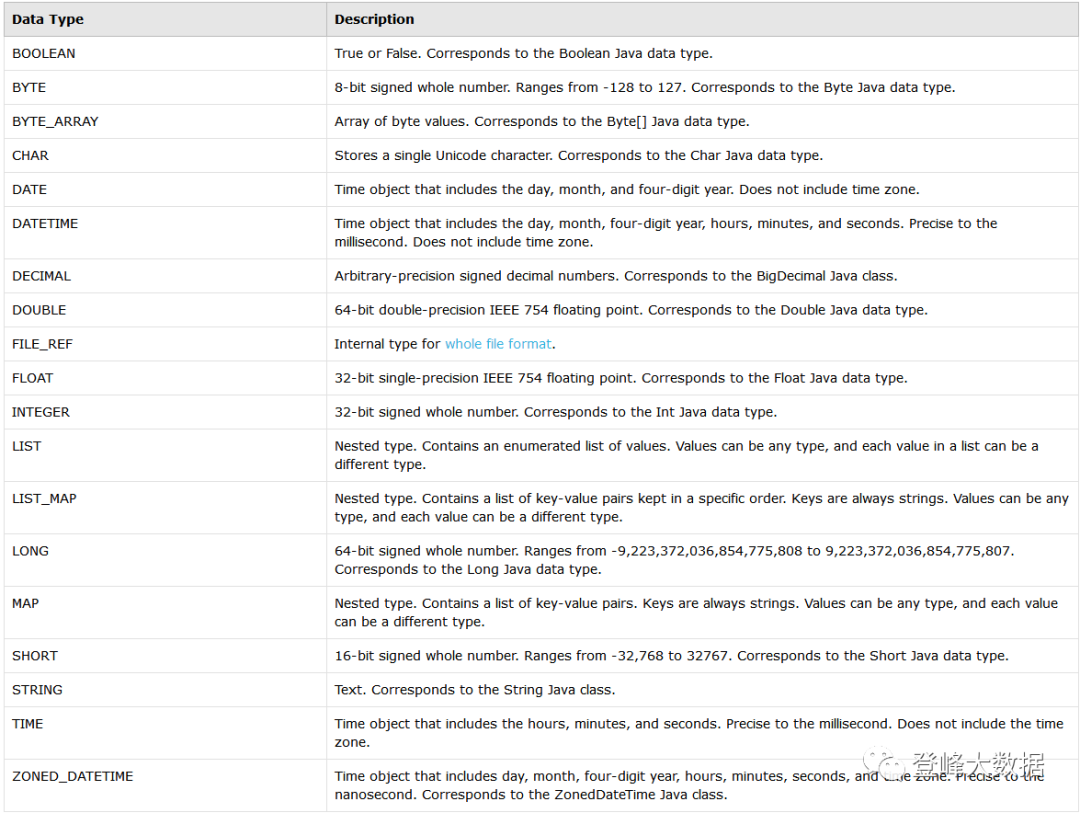
Data Collector数据类型
在管道中,Data Collector使用以下数据类型,在从外部系统读取或写入数据时根据需要进行数据转换:
设计数据流
在设计数据流时,可以在管道中分支和合并流。
分支流
当您将一个阶段连接到多个阶段时,所有数据都会传递到所有连接的阶段。您可以配置阶段所需的字段,以便在记录进入阶段之前丢弃记录,但在默认情况下,所有记录都将被传递。
例如,在下面的管道中,来自Directory origin的所有数据都传递到管道的两个分支,以进行不同类型的处理。但是您可以选择为Field Splitter或Field Replacer配置必需的字段,以丢弃不需要的任何记录。
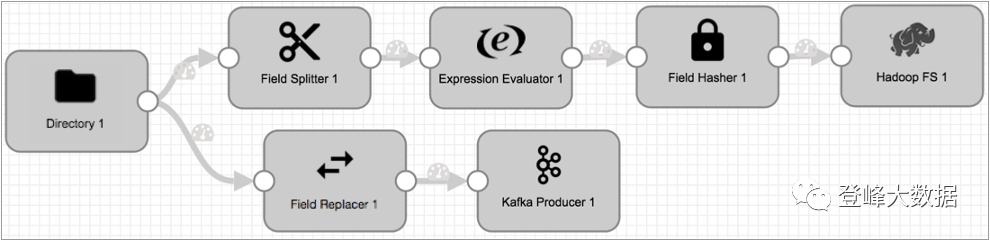
要基于更复杂的条件路由数据,请使用Stream Selector。
有些阶段生成传递到事件流的事件。事件流从事件生成阶段(如起点或目的地)开始,并从阶段通过事件流输出,如下所示:
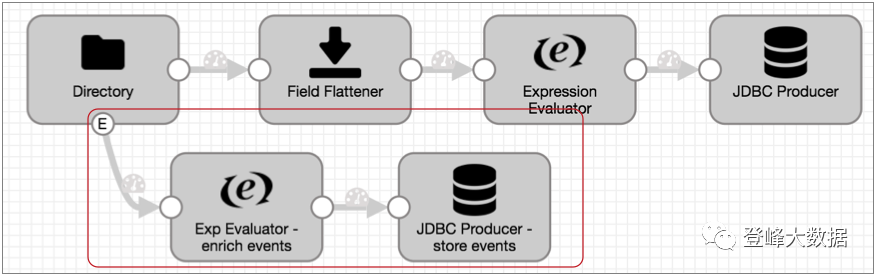
有关事件框架和事件流的更多信息,请参见Dataflow触发器概述。
合并流
通过将两个或多个阶段连接到同一下游阶段,可以合并管道中的数据流。当您合并数据流时,Data Collector将来自所有流的数据传输到同一阶段,但不执行流中的记录联接。
例如,在下面的管道中,Stream Selector阶段将null值的数据发送到Field Replacer阶段:

来自Stream Selector默认流的数据和来自Field Replacer的所有数据传递到Expression Evaluator进行进一步处理,但没有特定的顺序,也没有记录合并。
重要提示:管道验证不能防止重复数据。若要避免向目的地写入重复数据,请将管道逻辑配置为删除重复数据或防止生成重复数据。
注意,您不能将事件流与数据流合并。事件记录必须从事件生成阶段流到目的地或执行器,而不与数据流合并。有关事件框架和事件流的更多信息,请参见Dataflow触发器概述。
-
加群一起学习Streamsets:加我微信,拉你进群。
-
快速使用Streamsets就看培训视频:
https://edu.csdn.net/course/detail/32343















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









