






 随机森林是一种集成学习方法,由多棵决策树组成。每棵树通过自助采样和随机特征选择构建,最终结果由各树预测的多数表决决定。随机森林在处理高维数据时表现出色,可以评估特征重要性,且训练速度快,易于并行化。然而,它可能在噪声较大的问题上过拟合,且对取值划分多的属性权重不可信。
随机森林是一种集成学习方法,由多棵决策树组成。每棵树通过自助采样和随机特征选择构建,最终结果由各树预测的多数表决决定。随机森林在处理高维数据时表现出色,可以评估特征重要性,且训练速度快,易于并行化。然而,它可能在噪声较大的问题上过拟合,且对取值划分多的属性权重不可信。
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 发展出推论出随机森林的算法。 而 "Random Forests" 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林而来的。这个方法则是结合 Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"random subspace method"以建造决策树的集合。
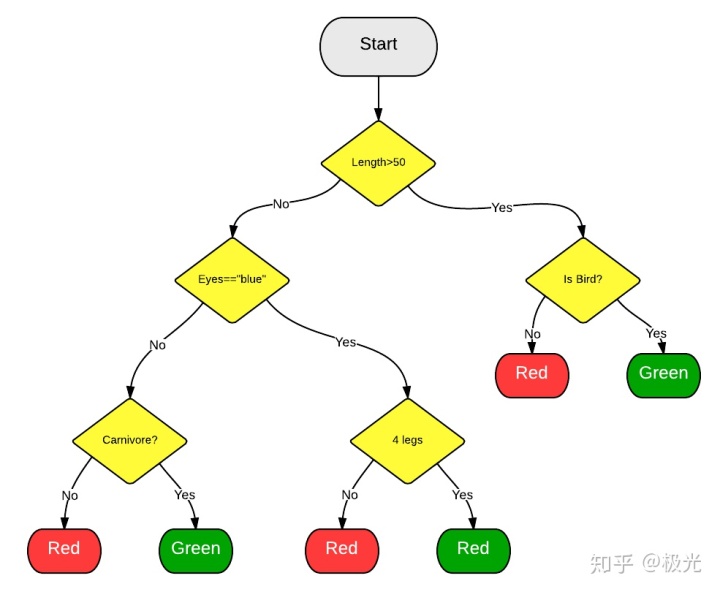
常见思路:
- 用N来表示训练用例(样本)的个数,M表示特征数目。
- 输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
- 从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
- 对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。
- 每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用。
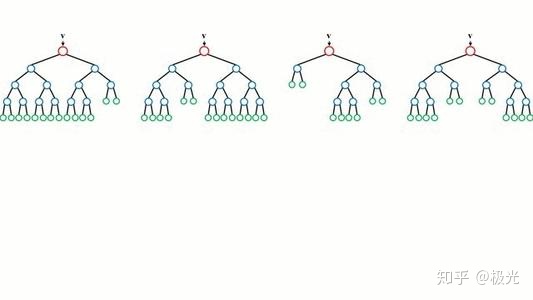
Bagging是并行式集成学习方法最典型的代表框架。其核心概念在于自助采样(Bootstrap Sampling),给定包含m个样本的数据集,有放回的随机抽取一个样本放入采样集中,经过m次采样,可得到一个和原始数据集一样大小的采样集。我们可以采样得到T个包含m个样本的采样集,然后基于每个采样集训练出一个基学习器,最后将这些基学习器进行组合。这便是Bagging的主要思想。Bagging与Boosting图示如下:
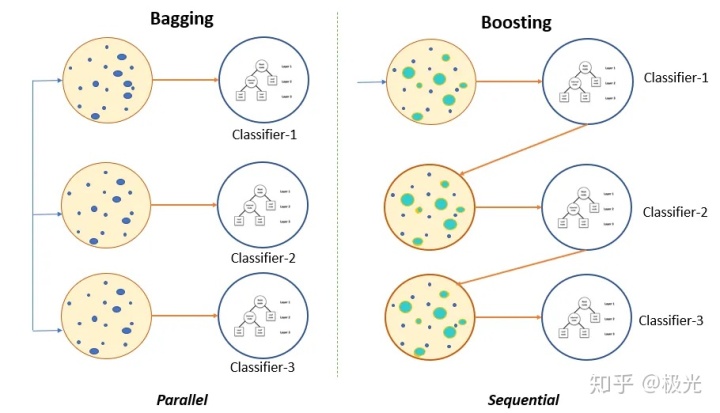
可以清楚的看到,Bagging是并行的框架,而Boosting则是序列框架(但也可以实现并行)。随机森林(Random Forest)就没有太多难以理解的地方了。所谓随机森林,就是有很多棵决策树构建起来的森林,因为构建过程中的随机性,故而称之为随机森林。随机森林算法是Bagging框架的一个典型代表。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









