







用神经网络来解决回归和分类问题,通常被称为深度学习。
神经网络是一个非常好用的工具,使用这个工具,相当于训练自己的AI(人工智能)。相比于机器学习,神经网络可以省略做特征工程的过程,解决各列特征并非独立同分布的问题。同时,神经网络能够处理的问题类型更广(CV,NLP,推荐算法等)。
本文的内容是BP神经网络的理解+对应Keras实现框架的解读。
目录
一、神经网络的理解
首先需要明确的是,所有机器学习、深度学习的任务都只有两种:分类和回归。而实现任务的手段只有一个:拟合出合适的函数。对神经网络而言,只不过是这个函数的结构复杂了一点。
①神经网络的结构
从总体来看,神经网络的结构就像它的名字一样,是由节点和它们之间的联系构成的。但是与图不太一样的是,神经网络是分层的、有向的。一个四分类的BP神经网络就像这样:
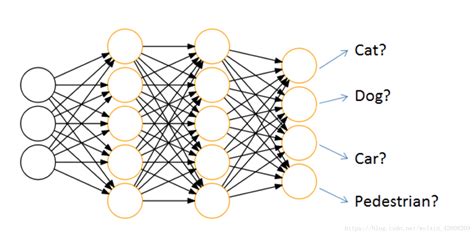
输入层的节点个数就是输入的列数,也就是有多少类影响因子;
输出层的有多个节点的是分类问题,只有一个节点的是回归问题。
输入层和输出层中间的层数叫做隐层。层数越多,神经网络越“深”。
②神经网络的运行
从细节来看,每一个神经元就像这样:
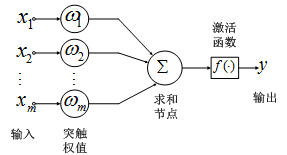
每一个神经元就像对上一层的节点做了一次融合打分。计算公式如下:
依次对每个节点完成这一计算过程,使得神经网络从输入层向输出层正常运行,就叫前向传播(Forward propagation)。其中两个向量的点乘就是x1w1+x2w2+……+x3w3,b是偏置(bias),有时可以省略,但一般情况下保留。在送入f()之前,完全是一个线性变换。
f()是激活函数(Activation Function),它的作用一方面是使一部分神经元失活,另一方面是实现我们所要拟合的函数从线性到非线性的转换(毕竟一条直线不可能完成所有的任务hhh)。常见的激活函数类型可以参考这篇博客:激活函数,你真的懂了吗? - 知乎 (zhihu.com)
③神经网络的调参
和机器学习一样,神经网络调参的方式就是构建损失函数(Loss Function),并使得损失函数的值最小。常见的损失函数类型可以参考这篇博客:机器学习中常用的损失函数你知多少? | 机器之心 (jiqizhixin.com)
如何使损失函数最小呢?原理就是梯度下降(Gradient Decent)。也就是说,通过求导来找到函数的最小值点。如果说损失函数是,那么实现梯度下降的公式如下:
其中就是神经网络的参数矩阵,
为学习率(用于控制步幅)。也就是说,每次都按这个公式来更新参数。更新一个参数的过程叫梯度下降,更新多个参数的过程就是反向传播。
关于常见的梯度下降算法,可以参考这篇:详解梯度下降法(干货篇) - 知乎,大的原理就是说可以把损失函数理解成一个曲面,要致力于找到真正的最小值,而不要落入局部最小值。
④神经网络的解释性
神经网络的解释性就是对特征的相关性建模(特征融合)。
二、Keras框架实现
keras是一个以tensorflow为后端的神经网络库,编写团队来自谷歌。
①Keras建模四步走
首先以一个回归问题为例:
1、定义网络结构:层数+每层神经元个数+激活函数
# 导入模块
import keras
from keras.layers import Dense # 全连接层
from keras.models import Sequential # 模型容器
import pandas as pd
# 读取数据集
df_wages = pd.read_csv('./data/hourly_wages.csv')
# 特征数量
n_cols = df_wages.iloc[:, 1:].shape[1]
# 构建模型
model = Sequential()
# 增加第一个隐层
model.add(Dense(50, activation='relu', input_shape=(n_cols,)))
# 增加第二个隐层
model.add(Dense(32, activation='relu'))
# 增加输出层
model.add(Dense(1))查看模型结构:
model.summary()
2、编写/Compile: Loss function(损失函数)/optimization(优化器)
这里损失函数是均方误差,优化器用的是adam,常用优化器的参考链接:Optimizers
model.compile(optimizer='adam', loss='mean_squared_error')
print("Loss function: " + model.loss)3、训练/Fit: back-propagation
model.fit(df_wages.iloc[:, 1:], df_wages.iloc[:, 0], epochs=10)
4、预测/predict
model.predict(df_wages.iloc[0:5, 1:])接着,对于分类任务,compile和输出层神经元会略有不同,尤其是一般会选择用交叉熵做损失函数。二分类的激活函数选择softmax。
df_titanic = pd.read_csv('./data/titanic_all_numeric.csv')
X_train_titanic = df_titanic.drop(['survived'], axis=1)
n_cols = X_train_titanic.shape[1]
# 模块导入
from keras.utils import to_categorical
# 生成标签
y_train_titanic = to_categorical(df_titanic.survived)
# 建模
model = Sequential()
# 单隐层
model.add(Dense(32, activation='relu', input_shape=(n_cols,)))
# 输出层
model.add(Dense(2, activation='softmax'))
# Compile
model.compile(optimizer='sgd', loss = 'categorical_crossentropy',
metrics = ['accuracy'])
# Fit the model
model.fit(X_train_titanic, y_train_titanic, epochs=10)需要注意的是此处应用了onehot编码(因为有些分类字段是字符串形式),需要用to_categorical这个库转变为矩阵。
②保存和加载模型
import numpy as np
from keras.models import load_model
model.save('./models/model_file.h5')
my_model = load_model('./models/model_file.h5')
predictions = my_model.predict(X_train_titanic)
probability_true = predictions[:, 1] # softmax函数输出了概率
pred_classes = np.argmax(predictions,axis=1) #返回概率较大的index,即返回判定为哪类
#模型评估
from sklearn import metrics
accuracy = metrics.accuracy_score(y_pred=pred_classes,y_true=df_titanic.survived)
# loss,accuracy
score = model.evaluate(X_train_titanic, y_train_titanic, verbose=1)③可视化呈现
如果要可视化呈现,那么model.fit()的结果必须保存到一个元素里,即results=model.fit()。这种情况下,对于回归问题,可以可视化其损失下降过程:
import matplotlib.pyplot as plt
plt.plot(results.epoch, results.history['loss'])
plt.xlabel('Epochs')
plt.ylabel('Mean Squared Error')
plt.title('Training Loss')
plt.show()对于分类问题,则需要用准确率等分类指标来评估:
plt.plot(model.history.epoch, model.history.history['accuracy'])
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.title('Training Accuracy')
plt.show()














 2884
2884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









