






如果把数据库比作一个图书馆,那么数据库表格就是存放在图书馆的书,表格里的一行行就是那书里的一页页。当我们一页页翻书去寻找想要的那一页,可能需要花费很长时间。同理,如果要从几百万行数据中查找想要的数据,让数据库逐行扫描也需要花费很长时间。怎么解决这一问题,这里就引入了索引的概念,利用索引来提高SQL的查询效率。
1 索引分为两种不同类型
1)聚集索引:如例子actor_id
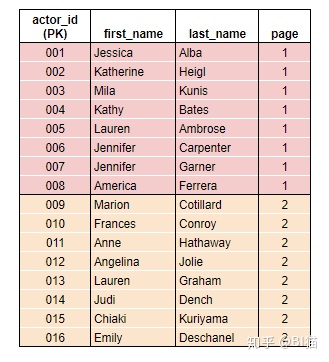
代码:
create clustered index [id_idx]
on [dbo].[actor_registration](actor_id)
2)非聚集索引:last_name
相当于创建一个lookup去指向所需要的数据。
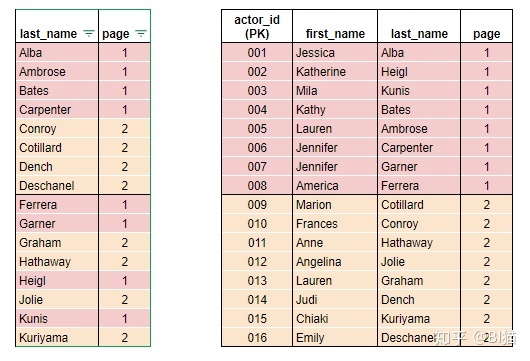
代码:
create nonclustered index [last_name_idx]
on [dbo].[actor_registration](last_name)
其次,我们也可以在SSMS中数据库中创建索引或者查询已有的索引:
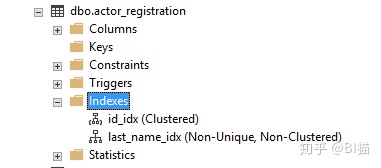
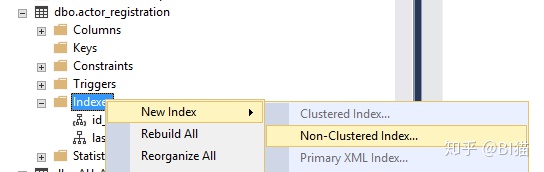
通常来说,像ID,Name, account number这些独特,具有变化性,经常用来做查询的列比较适合做索引。像性别,国家,年份这些就不太适合做为索引。
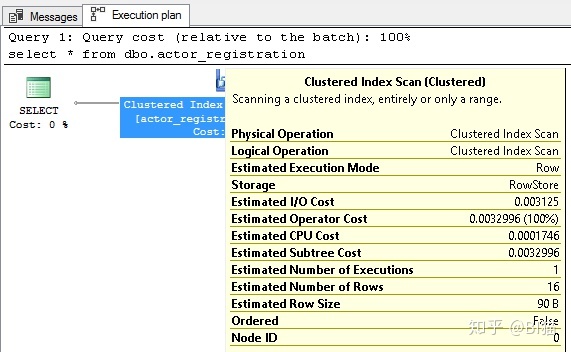
当然索引是需要维护,并不是建立一次就一劳永逸了,刚开始建立索引可能提高了效率,但之后随着数据库的增大需要随着需求去更新维护索引,如果发现query效率降低,试着检查下Execution Plan,看看问题出在哪里。















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









