






前言
虚幻引擎中的 蓝图 - 可视化脚本系统 是一个完整的游戏脚本系统, 其理念是,在虚幻编辑器中,使用基于节点的界面创建游戏可玩性元素。 和其他一些常见的脚本语言一样,蓝图的用法也是通过定义在引擎中的面向对象的类或者对象。 在使用虚幻 4 的过程中,常常会遇到在蓝图中定义的对象,并且这类对象常常也会被直接称为“蓝图(Blueprint)”。本文从代码的层面讲解虚幻引擎中蓝图的编译(包括编辑部分的代码,使用的版本是UE4 4.13.0)。
编译原理相关术语
编译程序是现代计算机系统的基本组成部分.从功能上看,一个编译程序就是一个语言翻译程序,它把一种语言(称作源语言)书写的程序翻译成另一种语言(称作目标语言)的等价的程序.
我们这里只是对一些术语进行简单地介绍,如果想系统学习编译原理,那么需要去找一些专业的书籍(如龙书、虎书、鲸书等,用搜索引擎都可以找得到),并且需要实践才能对编译原理有一个比较透彻和了解。
一般编译器编译一个程序会分为词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成这几个阶段来进行。
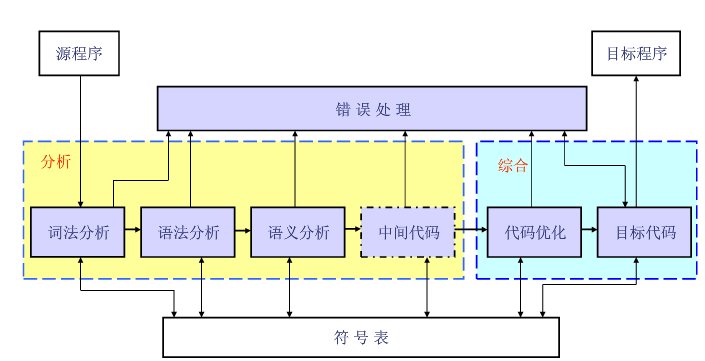
词法分析
从左至右读字符流的源程序、识别(拼)单词。
- 单词---token
- 保留字---reserved word
- 标识符 ---identifier(user-defined name)
示例:

语法分析
功能:层次分析.依据源程序的语法规则把源程序的单词序列组成语法短语(表示成语法树). 语法分析程序从扫描程序中获取记号形式的源代码,并完成定义程序结构的语法分析 (syntax analysis ),这与自然语言中句子的语法分析类似。语法分析定义了程序的结构元素及其关系。通常将语法分析的结果表示为分析树(parse tree)或语法树(syntax tree)。

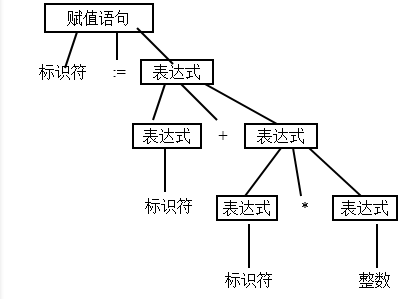
实例:
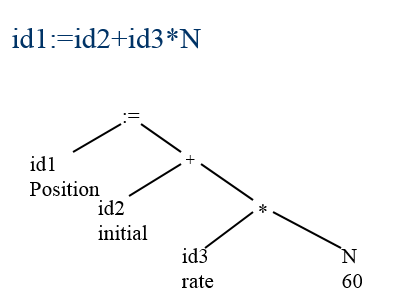
语义分析
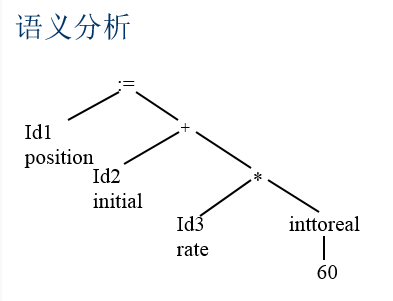
程序的语义就是它的“意思”,它与语法或结构不同。程序的语义确定程序的运行,但是大多数的程序设计语言都具有在执行之前被确定而不易由语法表示和由分析程序分析的特征。 这些特征被称作静态语义(static semantic),而语义分析程序的任务就是分析这样的语义(程序的“动态”语义具有只有在程序执行时才能确定的特性,由于编译器不能执行程序,所以它不能由编译器来确定)。一般的程序设计语言的典型静态语义包括声明和类型检查。由语义分析程序计算的额外信息(诸如数据类型)被称为属性(attribute),它们通常是作为注释或“装 饰”增加到树中(还可将属性添加到符号表中)。
- 上下文相关性
- 类型匹配
- 类型转换
示例:

语义分析结果:
中间代码生成
源程序的内部(中间)表示:
三元式、四元式、P-Code、C-Code、 U-Code、bytecode

代码优化
- 中间代码优化
- 目标代码优化


目标代码生成
目标代码生成是编译的最后一个阶段。目标代码生成器把语法分析后或优化后的中间代码变换成目标代码。

符号表管理
这个数据结构中的信息与标识符有关:函数、变量、常量以及数据类型。符号表几乎与编译器的所有阶段交互:扫描程序、分析程序或将标识符输入到表格中的语义分析程序;语义分析程序将增加数据类型和其他信息;优化阶段和代码生成阶段也将利用由符号表提供的信息选 出恰当的代码。
- 记录源程序中使用的名字
- 收集每个名字的各种属性信息
类型、作用域、分配存储信息
出错处理
检查错误、报告出错信息、排错、恢复编译工作。此文章已于 20:43:03 2016/10/25 发布到 凡事看本质
虚幻4编译相关术语和类图
虚幻引擎中的蓝图编译跟常规的程序编译多少是有一些不同的地方,但是基本原理是相通的。我们以普通的类蓝图为例,一个类中包含多个图,每个图中又可以包含一些子图。一个图会包含很多的节点(UEdGraphNode),每个节点可以包含若干引脚(UEdGraphPin)用来连接两个节点。节点又分为执行节点和纯节点(Pure node,上面没有执行引脚)。还有一个模式类(UEdGraphSchema)用于验证语法是否正确等。类图如下所示:
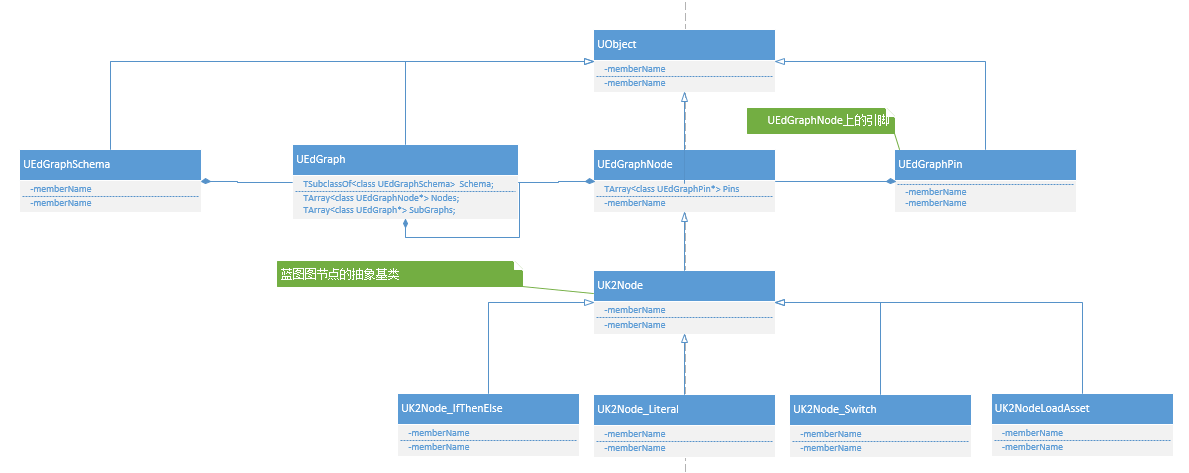
图(UEdGraph)
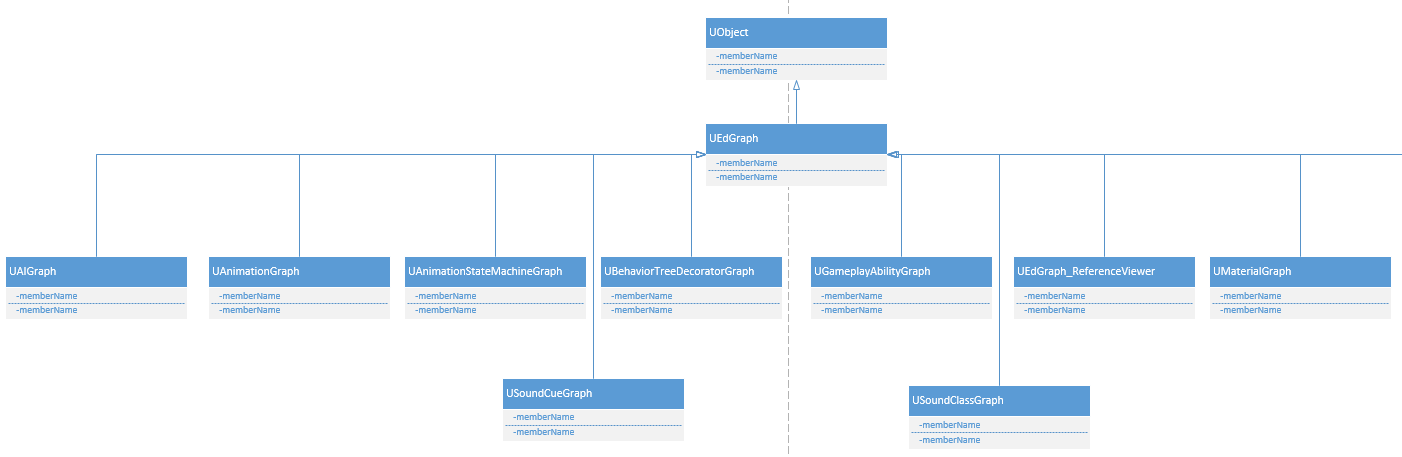
虚幻4中许多其它的也是使用图来实现的,所以它也有许多的派生类,比如UAIGraph、UAnimationGraph、UAnimationStateMachineGraph、UMaterialGraph等等。类图如下所示:
节点(UEdGraphNode)
一个有向无环图是由无数节点组成的,这个节点就是UEdGraphNode,因为上面提到的图中有支持各种功能的图,所以也就有各种各样的节点,下面我们只摘取一些节点类型,由于我们重点是讲解蓝图编译,所以我们把主要精力放在UK2Node上面,这个节点是所有蓝图节点的基类。类图所示:

引脚(UEdGraphPin)
每个节点上可以有多个节点,输入、输出节点以及参数引脚等等,这些引脚用于记录跟哪些引脚相连、类型、默认值等。
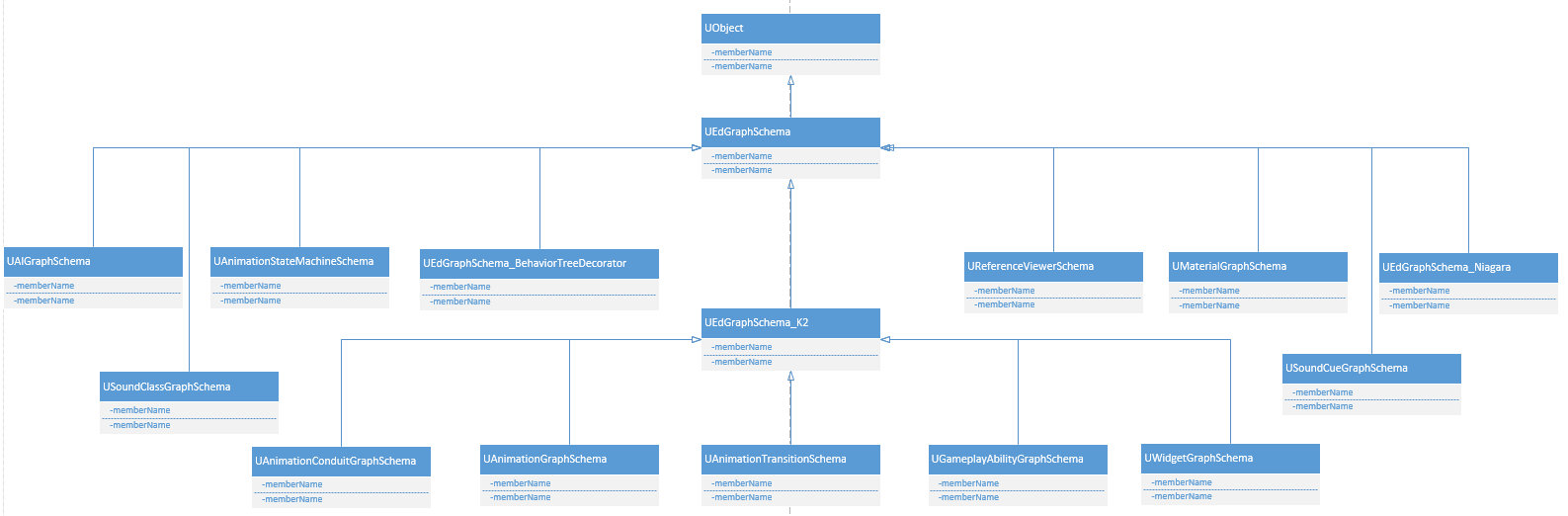
模式(UEdGraphSchema)
用于语法检查(看两个引脚是否可以相连、尝试连接引脚)等功能,如上面所有因为有多种图所以就需要多种模式。蓝图使用的是UEdGraphSchema_K2,动画以及UMG会有自己的Schema。类图如下所示:
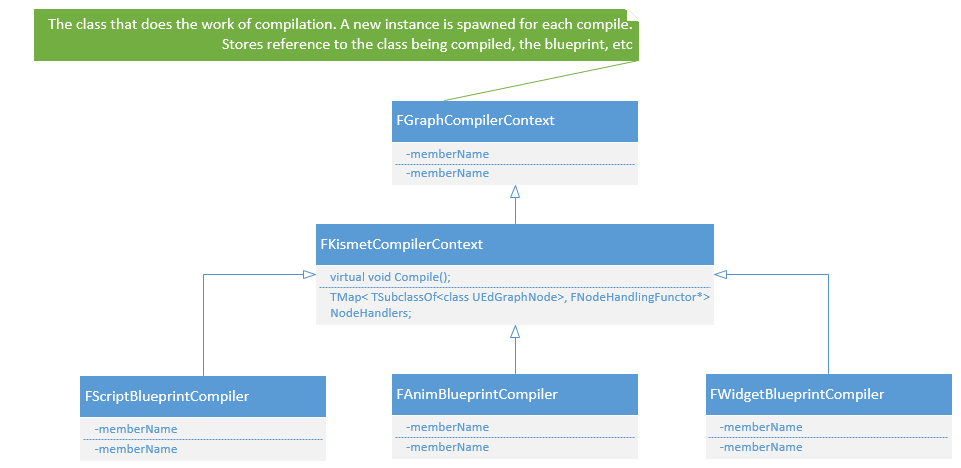
FKismetCompilerContext
真正执行编译工作的类,每编译一次就会生成一个新的实例,用来存储编译类的引用以及蓝图等。整个编译过程又分为好多步,是在Compile()函数里面做的。
FKismetFunctionContext
持有编译一个函数的所有信息,包括指向相关图(UEdGraph)的引用、属性以及生成的函数等。
FBlueprintCompiledStatement
编译过程中的单位工作。编译把节点翻译成一系列编译的语句,然后编译器后端会把它编译成字节码。例如变量赋值、goto、调用(call)等。
FBPTerminal
图中的一个终结点(字面量、常量、或者变量引用)。每一个数据引脚都跟其中的一个相关联。你可以自己在NodeHandlingFunctor里面来生成自己的项,用来存储变量、中间结果等。
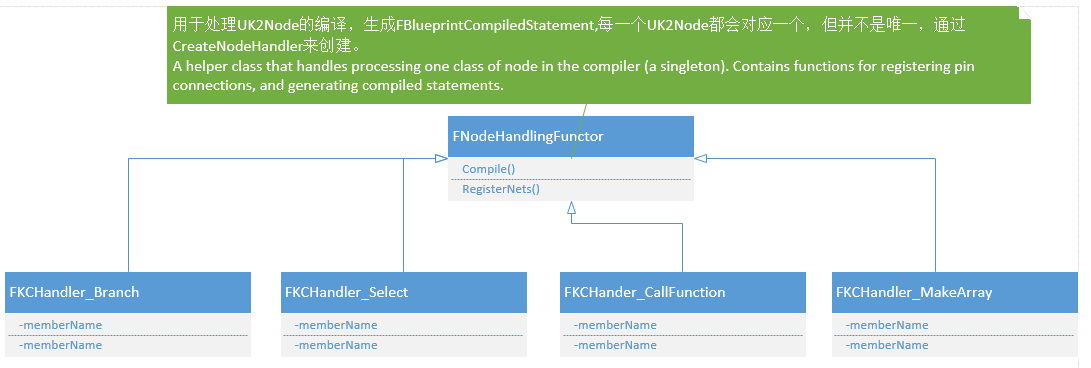
FNodeHandlingFunctor
用来处理一类节点编译的帮助类,包含用于注册引脚连接的函数(RegisterNets()),以及生成编译语句(FBlueprintCompiledStatement)。通过UK2Node::CreateNodeHandler()函数来创建。如下类图只列举了几个HandlerFunctor。
FBlueprintCompileReinstancer
在编译基本完成的时候,由于类可能已经改变了大小或者有新的属性被添加或删除了,那么编译器需要重新实例化我们刚刚编译类生成的对象实例,生成一个新的,然后使用CopyPropertiesForUnrelatedObjects()函数来把旧的实例中的数据拷贝到新的实例中去。
FKismetCompilerOptions
编译选项,用于指定编译时的设置,包括编译类型(只编译Skeleton, 全部编译、只生成字节码、只生成cpp)等。
Skeleton Class
Skeleton类如其名字定义是一个骨架类,在添加成员变量或者成员函数时都会重新重新(它里面没有代码和自动生成的隐藏变量)















 9988
9988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









