






这篇文章介绍了利用标签排列组合的方式来进行特征重要性的核验,原理可见这篇文章
用标签排列组合变换的方式来得到特征重要性的原理其实有点像统计线性方程中的p值检验的过程,本质就是看实际标签拟合的重要性与我随机shuffle建模得到的特征重要性差距是否足够显著,我们用如下的步骤来完成这个过程:
- 创建null feature 分布:我们通过不停的shuffle 样本标签值并拟合模型来完成这部。在过程中我们可以观察模型特征对于随机的标签值的表现。
- 在原始标签分布下拟合模型,得到真实的特征分布,这将用于之后与第一步形成的特征分布做对比。
- 对于每个特征,我们进行一个类似于p值检验的步骤:
- 计算真实特征分布于第一步null distribution之间的差距,这个kernal上直接使用了occurences来进行计算。
- 将实际特征重要性与null importance中的mean和max做对比。
数据集用的还是home-default-credit之前已经写了好几个kernal了就不写数据处理过程了,下面直接开始:
import 下面的函数是主体,遍历特征得到特征重要性矩阵:
def 先跑一个bench mark
need 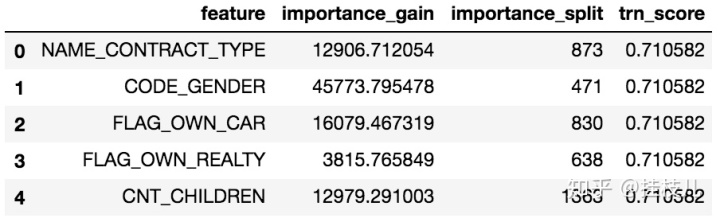
null_imp_df 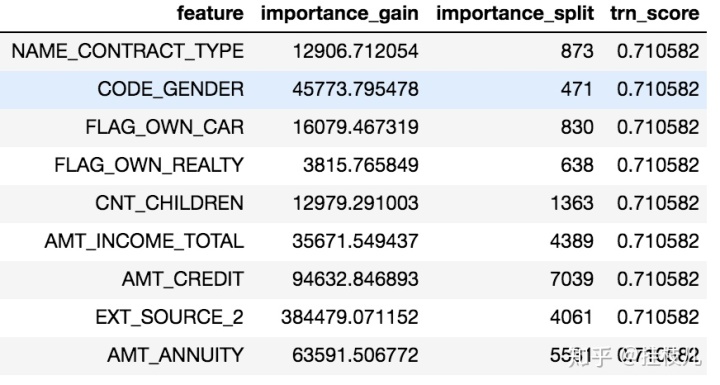
好了,我们来看看几个强特征的分布
display_distributions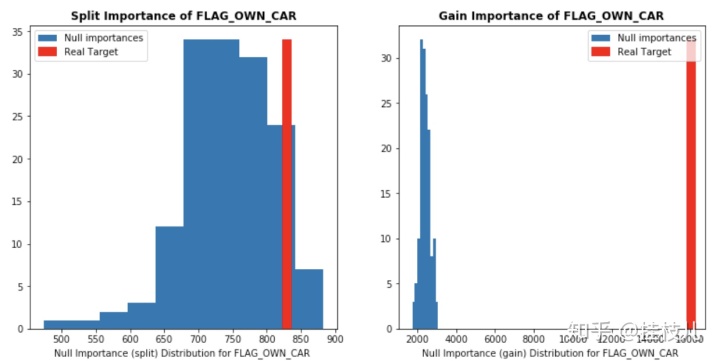
display_distributions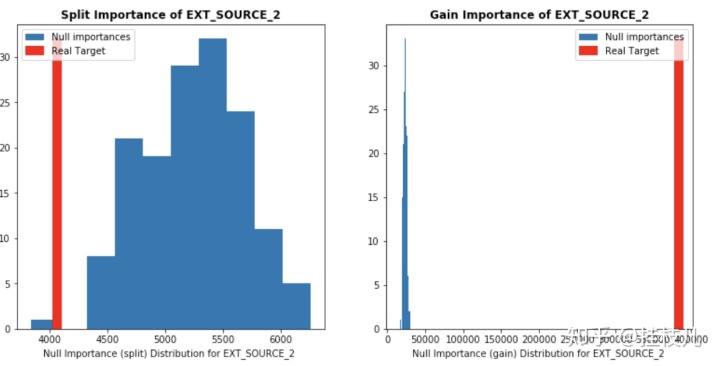
从上面选的几个特征来看的话这种方式的强力之处显然大家都看得出来了:
- 任何一个特征只要方差够大并且能够给树模型用的话,他总可以找到切分点针对损失函数去做进一步优化。
- 相关的特征的重要性在树模型中会互相造成影响(比如2个相关的强特征1,2,他们的切分的过程中如果被交替使用的话,那么特征的重要性就会被稀释)。 所以我们这个挑选方式的优势就在于:
- 剔除在建模过程中由于高噪声而被选入模型建模的特征
- 剔除相关特征在建模过程中特征重要性被稀释的影响。















 3661
3661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









