







最近爬取某个网站的书籍信息,大概请求几百次之后网站就会出现302 跳转提示ip异常需要登录。于是就用挂代理换ip的方法。网上看了下,大部分都是从把从网上爬取到的代理ip写到txt里。然后scrapy 加载这个txt,然后随机获取一个ip爬取数据。这种方式有很多弊端:ip用完了,爬虫就停止了。每个ip用一次就换了,scrapy没多久就会停止。
经过两天的研究,我终于写出了自己满意的代码。这个scrapy 代理中间件可以满足以下要求:
1,从一个ip代理的接口获取ip地址(ip代理池 github上有很多项目)
2,使用这个ip爬取数据,如果没有被网站Ban掉就一直使用这个ip
3,如果这个ip失效了,或者是也被ban了,就在从ip接口里再获取一个ip继续请求
主要就是在中间件里增加一个方法就行
class RandomProxy(object):
def __init__(self, settings):
self.PROXY_URL = settings.get('PROXY_URL')
self.chosen_proxy = ''
if self.PROXY_URL is None:
raise KeyError('需要先设置获取代理ip接口的地址')
#从地址获取一个ip
self.chosen_proxy =self.getProxy()
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def getProxy(self):
log.msg('get proxy')
proxy_addr=json.loads(requests.get(self.PROXY_URL).text)['ip']
log.msg("[+]---get proxy ip is:" + proxy_addr)
return proxy_addr
def delip(self, proxy):
log.msg("要删除的ip:" + proxy)
sql = 'delete from ip where data =%s' % ''' + proxy + '''
sta = cursor.execute(sql)
log.msg(sql)
log.msg(sta)
if sta > 0:
log.msg("del band ip from databases")
db.connection.commit()
else:
log.msg('del ip faile')
def process_request(self, request, spider):
if 'proxy' in request.meta:
if request.meta["exception"] is False:
return
request.meta["exception"] = False
request.meta['proxy'] ="http://" + self.chosen_proxy
def process_response(self, request, response, spider):
if response.status in [403, 400,302] and 'proxy' in request.meta:
log.msg('Response status: {0} using proxy {1} retrying request to {2}'.format(response.status,
request.meta['proxy'],
request.url))
proxy = request.meta['proxy']
del request.meta['proxy']
proxyip = proxy.split("//")[1]
try:
#删除数据库里的ip
self.delip(proxyip)
log.msg('deleted banned proxy , proxy %s' % proxyip)
except KeyError:
pass
self.chosen_proxy = self.getProxy()#这个代理被403,302了 重新获取
return request
return response
def process_exception(self, request, exception, spider):
if 'proxy' not in request.meta:
log.msg("没代理错了,需要检查")
return
else:
log.msg("有代理也错了,把数据库的ip删掉")
proxy = request.meta['proxy']
proxyip = proxy.split("//")[1]
try:
# 删除数据库里的ip
self.delip(proxyip)
except KeyError:
pass
request.meta["exception"] = True
log.msg("重新获取ip")
self.chosen_proxy=self.getProxy()
return request
然后在settings.py 中配置你的获取ip代理接口的地址
PROXY_URL = 'http://xxxx:3000/v2/ip'需要注意的是 中间件里的 这段代码
proxy_addr=json.loads(requests.get(self.PROXY_URL).text)['ip']
你要根据你的实际情况解析,我这个返回的就是 ip:port 形式
最后在 settings设置DOWNLOADER_MIDDLEWARES
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 90,
'douban.middlewares.RandomProxy': 100,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
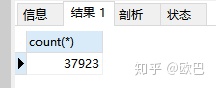
}这个数值和顺序很重要,最后附上截图,已经爬了26个小时

数据量:
参考资料:
aivarsk/scrapy-proxiesgithub.com














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









