






pandas 中的 read_csv 方法是一个十分强大的读入数据的方法,官网的 read_csv 的参数列表如下。看这些参数的解释,都能十分详细地了解该方法的用法,网络上也有很多中文版的参数翻译。但是,对于基本的应用情景,缺乏比较到位的解释,导致每次导入数据时都要看文档,试错数次才能正确读入数据,降低了数据分析的效率。本文旨在通过简单的例子,对该方法的具体应用做一个整体的总结和分析,以期覆盖常见的数据读入情景,方便日后使用。
pandas.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~ AnyStr]], sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal: str = '.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
典型的 csv 文件
典型的 csv 文件如以下的图中所示,由第一行的列名称和多行组成,不同项目之间以英文逗号最为间隔符。
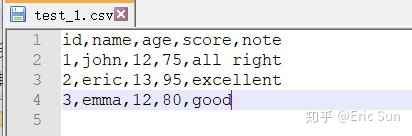
这种文件可以用最简单的格式读取。
import pandas as pd
file_name = 'test_1.csv'
data1 = pd.read_csv(file_name)data1 读取后得到下面的 DataFrame:
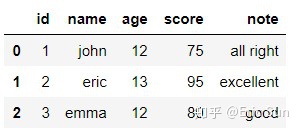
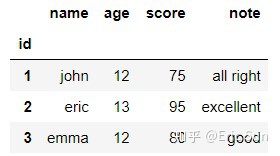
发现这个 DataFrame 的 index 并没有用我们数据中的 id,想用数据中的 id 作为 index,只需要按下面的读取格式:
data2 = pd.read_csv(file_name, index_col=0)data2 读取后得到
含有日期格式的 csv 文件
有时文件中有日期格式,可以用 read_csv 直接将日期转换成 python 可以识别的 datetime64[ns] 对象,方便后面的对时间序列数据的处理。示例文件如下图所示。
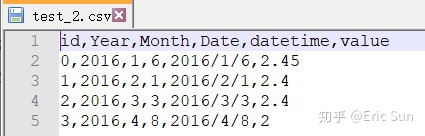
这里采用 read_csv 中的 parse_date 参数。有以下几种形式:
file_name ='test_2.csv'
data1 = pd.read_csv(file_name, parse_dates=['datetime'])
data2 = pd.read_csv(file_name, parse_dates=[[1, 2, 3]])
data3 = pd.read_csv(file_name, parse_dates={'mydate': [1, 2, 3]})
data4 = pd.read_csv(file_name, parse_dates={'mydate': [1, 2, 3]},
keep_date_col=True)data1~data4 的内容分别如下:
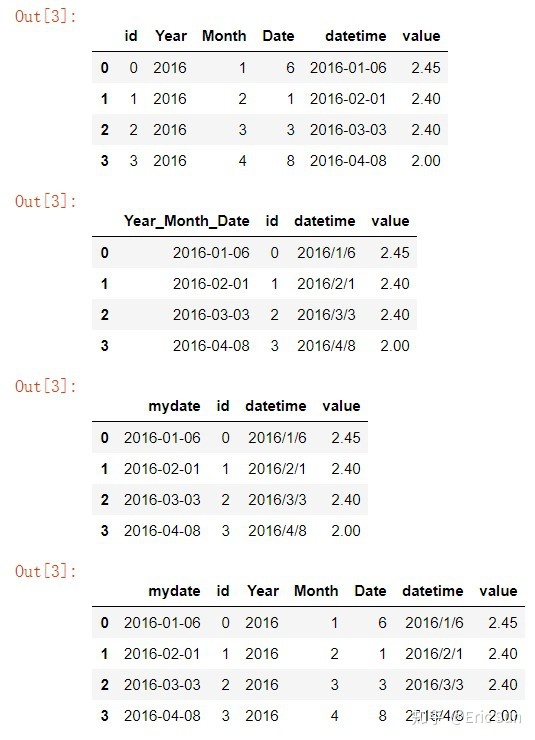
data1 用数据中名为 datetime 的列作日期解析用,data2 用第 1,2,3 列的内容作日期解析用,data3 给 1,2,3 列的数据用用户自定义的 mydate 命名,data4 通过 keep_date_col ,保持源数据的被解析列正常读入不被修改。
固定列宽的 txt 文件
对于固定列宽的 txt 文件,也可以用 read_csv 方法读取,示例文件如下:
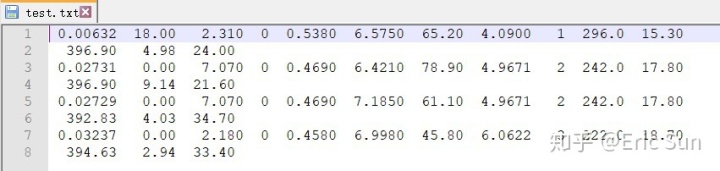
这种文件两列间用不定数量的空格间隔,每一列对齐。读取方法如下:
data1 sep 参数可以定义列与列之间的分隔符,默认为逗号,读固定列宽的 txt 文件时,指定为 's+' 采用的是正则表达式的写法,意思是分隔符为一个至多个(数量不限)的空格。此时得到如下的读取结果:

自定义读取内容
当然,读取文件的最高境界就是自定义读取内容。这部分用 read_csv 就不能完全胜任了。需要用到 python 原生的 read/readline/readlines 方法,文件指针 seek/tell 方法,以及少部分正则表达式的知识。
比如说,我们想读取数据文件中数据 33.40 上一行的数据是什么,可行的思路有三种,一种是利用 read_csv 方法读取整个文件,再利用 numpy 中的 where 方法查找数据 33.40,最后用 iloc 索引查到所求的数为 34.70。
ix, iy = np.where(data1 == 33.40)
data1.iloc[ix-1, iy]该方法适用于小文件,可以一次性地读取到内存中作进一步处理。
此外,我们可以用 python 原生的 readlines 方法做到这一点:
input_str = '33.40'
with open('test_1.txt', 'r') as f:
linelist = f.readlines()
for i, line in enumerate(linelist):
if input_str in line:
ii = i-1
idx = line.find(input_str)
target_str = linelist[ii][idx:idx+len(input_str)]即通过 readlines 方法读取文件内容作为列表形式储存,再对所查找的内容逐行匹配,匹配到后记录索引,最终找到所求的数据 34.70。
同样的,该方法是一次读取所有的文件内容,适用于小文件。
以下是一种适用于大文件的方法。
input_str = '33.40'
with open('test_1.txt', 'r') as f:
last_last_pos = None
last_pos = f.tell()
line = f.readline()
while line:
if input_str in line:
if not(last_last_pos is None):
f.seek(last_last_pos)
idx = line.find(input_str)
last_line = f.readline()
target_str = last_line[idx:idx+len(input_str)]
break
else:
print('data in the first line')
last_last_pos = last_pos
last_pos = f.tell()
line = f.readline()tell 方法是返回当前文件指针位置的方法,readline 方法每次读取文件中的一行,seek 方法可将文件指针跳转至指定位置。
以上代码首先记录文件开始的指针位置,然后向下读取一行,如果未读至文件尾,即判断所查内容是否在当前行,若在,回到上一行找对应位置的数据即可,若不在,记录当前行位置后,读取下一行内容,依次类推,直至找到所求数据 34.70 为止。
判断应该用小文件方法还是大文件方法的依据是,如果计算机能够一次性读取文件内容,用小文件方法速度上占优,但如果计算机内存不足以读取所有文件内容,则应该按照大文件方法进行读取。
综合以上内容,我们对 read_csv 方法的读取数据功能的应用作了初步讨论。在实际文件读取的过程中,只有将固有方法、python 文件 I/O 及正则表达式灵活运用,才能简介快速地完成数据的读取操作,为后续的数据分析提供支持。
参考文献
- pandas read_csv 方法官网
2. Stack Overfow:如何找到文件中的特定行
https://stackoverflow.com/questions/40546376/how-to-seek-to-a-specific-line-in-a-filestackoverflow.com3. Python 菜鸟教程:seek 方法
https://www.runoob.com/python/file-seek.htmlwww.runoob.com














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









